The physics context is the view layer - all visible collections interact among each other.
The order of simulation is handled on the scene level by controlling which view layer is evaluated first.
Each view layer with a single physics solver.
Collections can be enabled/disabled in different view layers to exclude them from the simulation being baked.
Outcomes of the presentation:
This system wouldn’t allow an asset to be brought over with all its simulation data (e.g., character with simulated cape) (because view layer is not a datablock).
This can fit in a VFX pipeline, where the process is more linear and deal with the entire scene.
However for simple asset-centric simulations (e.g., clothes, water fountain, character hair) it makes it complicated to connect the different simulation systems.
It is also tricky to play a simulation that involves multiple solvers and tweak one of them, if the setting is in the view layer level.
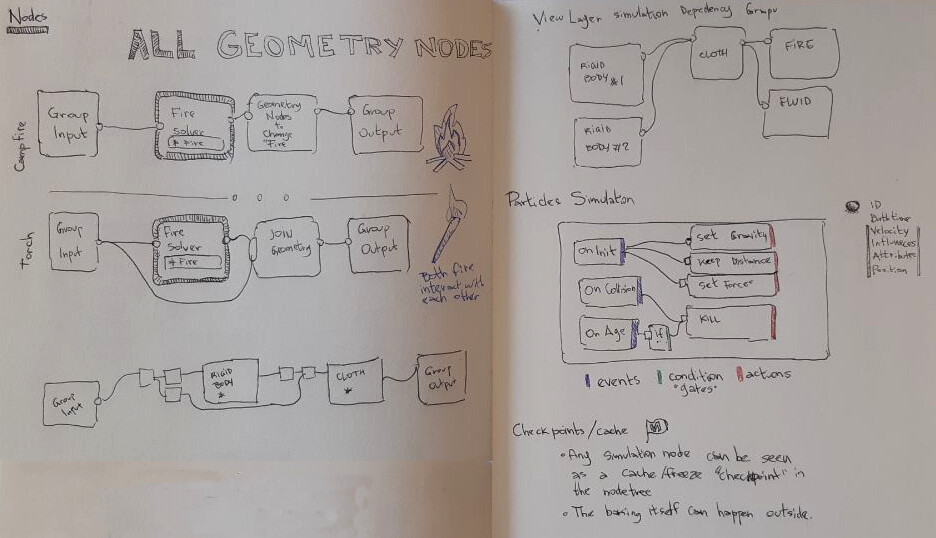
Particle Nodes / Solvers v2.0
New design round, presented to Brecht and Simon. To be presented to Ton Thursday 10:00 CEST after attributes processor.
The solvers will be integrated in the pipeline in the Geometry Nodes level.
Each solver node gets the geometry in and out, so it can be transformed with further nodes or even connected to a different solver.
Solvers are ID blocks, which can be re-used in different geometry-nodes nodetrees. That means you can have multiple geometries interacting with each other in the same solver.
In a View Layer level users can inspect (read-only) the dependency between the different solver systems and eventual circular dependencies. Their order is defined in the geometry-node trees though.
Most of the solvers can be treated as a blackbox where objects get in and out.
Colliders (and other solver specific settings) are defined on the object level.
Particle Simulations are solvers that have their behaviour set with nodes.
There are three different node types:
Events
On Init, On Collision, On Age
Condition Gates
If attribute > x, If colliding, And, Or, …
Actions
Set Gravity, Keep Distance, Set Forces, Kill Particles.
Similar to Geometry-Nodes, each Action node can either:
Add a row to the spreadsheet (i.e., create new points).
Add a column to the spreadsheet (i.e., create a new attribute).
Edit a cell/row/column (i.e., set particle material).
Checkpoints / cache
A solver can be baked into caches.
In a similar way the nodetree can be frozen (stored in a cache), edited, and continue with more nodes.
Both concepts are interchangeable, where we can get a node that reads from a cache (vdb, alembic, …) that can work the same way as if I had a solver node connected to the tree.
Freezing can be for a “frame” too, not necessarily for the entire sequence.
Attribute Processor
The attribute processor discussion faced a few problems:
The compact node is an issue for regular nodes as well, and attribute processor makes this problem even worse.
Restricting “column” operations to happen only inside attribute processor.
Attribute only nodes outside the attribute processor are not always intuitive and still require a lot of temporary attributes.
Attributes List Data-Flow / “Columns” Links
Design to be discussed on on Friday.
What if users could pass attributes around directly?
Seeing concrete plans for simulations is very exciting. It seems you’re going for something flexible. Particles nodes seemed mature enough already six months ago, I can’t wait to see how the design evolved with geometry nodes under your belt now. Cheers !
Hi Everton. I’m updating this thread every day with the daily update. The discussions themselves are happening in real-life at the Blender headquarter (and not streamed).
This would be really great to have in geometry nodes as well. Cache the state of the nodes and then be able to mesh edit the result and keep adding nodes past that point.
Right now we have an “all or nothing” option for the nodes UI. We either have all the options available or we have them hidden/hardcoded.
For example, the Point Instance node uses position, rotation and scaling (or radius? I forgot now) to instance the points. If we wanted to make this visible the only option at the moment is for this to be in the main node. That would make the UI more complicated with numerous options. So we end up having to choose between hard-coded names, busy node UIs or not having more features in some nodes.
Saw this coming miles away.
What works quite well for the shader editor (having the node options attached to the node itself) wont work quite as good for geometry nodes nor will it work for upcoming solver and more complicated nodes. Blenders node paradigm to always cram all options directly onto small nodes instead of displaying those options in a designated node properties area yields to messy looking nodegraphs, individual nodes having a horrible and confusing UI, endless UI discussions to reduce the complexity/features, and therefore slower progress.
Some nodes are already so bad that my eyes have to wander up and down several times until understand whats going on. The top level attribute processor UI is impossible to understand at first sight. This would be soo much easier if those options live in a seperate area like how many many other software packages are dealing with that problem.
I’m not sure if it’s a place to suggest things… and I’m not sure if my suggestion is something already considered… but:
What if we use “nodes” visually in the editor only for connections purpose (and some low-level or main options maybe) and edit their “advanced full options” at the side panel. Like what we have in the viewport itself. We see our objects in the viewport but we edit their properties in other places dedicated to it (object properties context tab or whatever…) I see something similar in the famous node based software “H”. You see just a “bubble” in the node-tree but it’s options are in the property editor.
I guess the challenge here is to design a user interface to control which properties are shown on the node itself… and when. I think whenever there’s an extra connection between two nodes (when I say extra, I mean one that’s not geometry), it should be shown. Or it could be a toggle… The alternative is to somehow convey that there’s a connection, without showing the noodle itself. Maybe the “main” geometry noodles could change their aspect according to this? (thicker, doubled, etc.) But how do we allow the user to connect up node properties if sockets are hidden by default ? Through a rolldown menu showing all sockets? GN being less granular than cycles nodes, users need less of those extra connections (except in attribute processor), so it might work.
Are you considering keeping the current interface as an alternative? it may not be necessary if the “compact mode” is done right. Or, we could have an enum that goes :
compact mode, only the main noodle is shown. “main noodle” would have to be defined for each node, as not all of them output geometry
compact mode with extra connections. All connected sockets are shown, unconnected sockets are hidden
full mode, where every socket is shown (connected or not)
Now that I think of it, we could have a compact mode that makes the active node show its complete interface (including unconnectable properties). All other nodes would stay compact. Clicking a node would “unroll” it so to say, to allow changing properties and connecting sockets.
In my opinion having the options split between two places is the worst of all solutions.
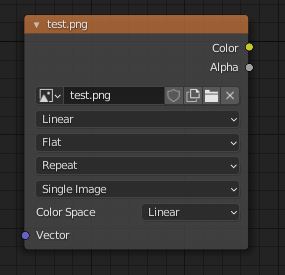
Lets take the image texture node in the shader Editor as an example:
Thanks to leaving important information out to save some space the user has to guess what the settings stand for. What does the first Linear stand for? Color space? No, Interpolation.
Where is the alpha setting? Right, in the n-panel under properties … who is aware of that? Probably under 5% of the users.
Not a good idea to make the user search for settings in more than one place.
Indeed and that’s because it’s an exception, not a rule. My opinion is that it’s a mistake. It’s not standard by any means… so obviously users don’t know to search elsewhere for a hidden setting… don’t you think? If the design is to defer properties to another area (such as the sidebar), all nodes are going to obey this and it’s going to be fully assumed, with node properties showing by default right next to the node editor.
Sure, that would be possible and would also work.
But if users have either the sidebar or a new node-properties area open all the time anyway whats the point of having some controls on the nodes itself? To strip them of the options would make a way cleaner looking node graph thats easier to read and also easier to organize. Plus it would make space for additional controls on the nodes (mute, view, statistics, errors, …).
I am not suggesting that. I suggested to have either all or none of the properties on the nodes. But personally ? I would gladly go with a single compact view, and ditch the “old way” completely. In short, I agree with you.
Wow, I used blender for 5+ years and never even knew about these settings… Also this is where “default” projection settings for images were located, I always just assumed they were hardcoded…


 )
)