As a follow up to the Nodes workshop I’ve been working in a design for how to handle attributes in a more direct way and to have a way to better abstract hardcoded values for re-usable assets. Here is my latest proposal.
Attributes and attribute sockets
Attributes are commonly referred to as columns. This is a reference to how they are visualized in the spreadsheet. Attribute sockets are sockets that pass an entire column from the spreadsheet containing:
- List (array) of elements.
- Datatype (float, integer, boolean).
- Domain (vertex, face, …).
So far every node were allowed to read and write any attribute to the geometry, and the result was incorporated as part of the outputted geometry. This leads to an extremely linear nodetree that makes it hard to read.
Instead, it will be interesting to pass the attributes around directly, so the operations can happen independently of the original geometry.
This was avoided in the original design because users can easily shoot themselves in the foot by connecting attributes from geometries with different index orders or length leading to unpredictable results. At the moment though, its benefits outweigh those issues.
Selections are just a an attribute socket with a list of booleans.
Asset vs on-the-fly creation
There are very distinct workflows for using geometry nodes, asset and on-the-fly creation.
At one extreme there are artists creating well crafted reusable assets where no hard-coded values are assumed, and everything the node group needs is passed via the modifier parameters. This means someone trying to re-use this asset can just plug different objects and deciding which vertex group to use from the new object.
On the other side we have an artist creating an one-off asset, with disregard to hardcoded values and “data abstraction”. A modifier in this case needs no external parameters since everything could be defined inside the node tree. The resulting asset cannot be plugged into another object and expect to work without a careful memory of which vertex group names are required for which parts of the nodetree.
There are benefits of both approaches, and the reality is that often artists start on-the-fly creation to only later prepare the asset for shareability. For this proposal the asset creation is prioritized whenever there are conflicting options.
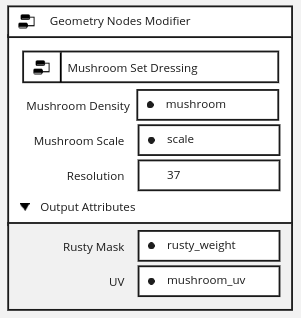
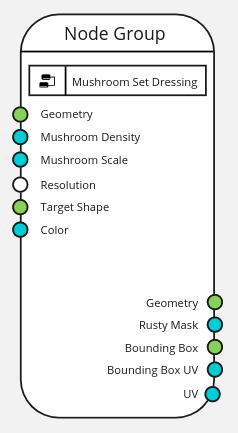
Geometry Nodes Modifier
Let’s start by looking at a simple geometry node modifier. The first new thing you can see is that all the
attributes expected from this mesh and generated from the node tree are explicitly visible in the modifier.
Note also that those attribute fields (mushroom, scale, rusty_weight, mushroom_uv) are not simply strings. They are attributes that are expected to exist in the mesh. While they are referred to as strings, inside the nodetree they are passed around as attributes (i.e., list of values).
Group and Attribute Inputs
Every group input could be presented as its own node. Those nodes should be clearly identified, and prevents the long lines we have connecting the one group input allover the nodetree. Among the group inputs there is
Among those input nodes there are the attribute inputs. Those nodes are exposed in the modifier UI as “strings” (that can be kept in sync with the original attribute name) while inside they are just a list of values.
Users can drag a UV layer from the active object in the nodeetree and get an Attribute Input for this attribute, while under the hood Blender creates a new Group Input, set the modifier value for this input, and create the Attribute Input.
Updated Attribute Nodes
Updated attributes are used when an attribute needs to be accessed after topology change.
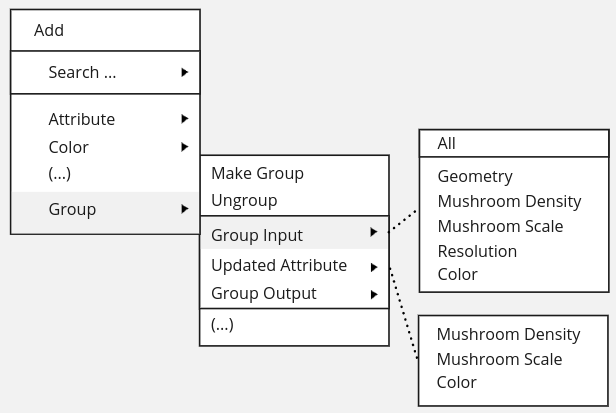
When a new Group Input is added, it becomes possible to add the corresponding Attribute Input or Updated Attribute node.
Advanced Group Input/Output Sockets
A modifier can only handle one geometry as input, and one geometry as output.
However the geometry nodes datablock can be re-used inside a nodetree. In this case complex systems can benefit from optional inputs and outputs that can’t be used when in a modifier.
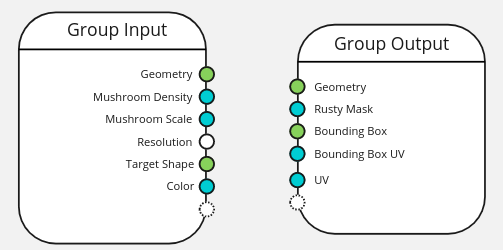
Those sockets can be marked so that they don’t show in the modifier. For the geometries this can be automatic because of the one-geometry per modifier restriction.
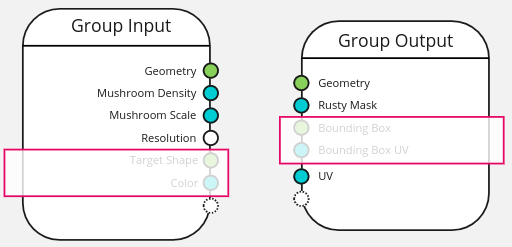
When using this node group inside a nodetree there is no distinction between the modifier parameters and the others. Also in this case the attribute socket expects the whole attribute (list of values) not the name of the attribute.
In this design the relation between the geometries and their attributes is loose and not enforced. For the update attribute node to fully work, it will require all the input attributes to be included in all the geometry inputs. The same for the output attributes and geometries.
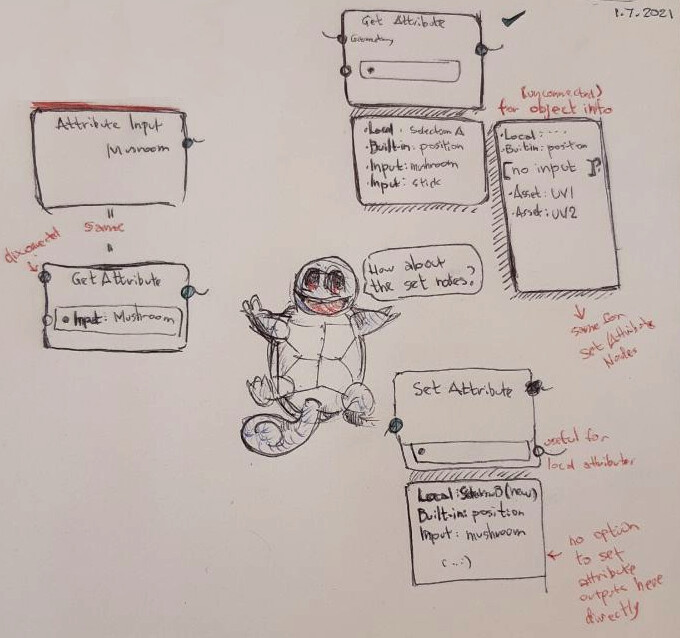
Local Attributes
Local attributes are the main place where hard-coded strings are allowed - useful to save an attribute to re-use later or to get the same attribute after topologies changes. Name clashes with existing built-in attributes can be avoided by using namespaces.
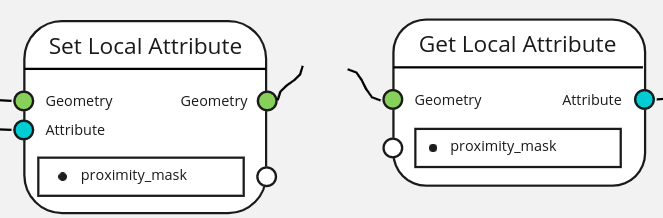
The output and input of those nodes (besides the geometry) is the attribute name. This is not the attribute itself. This permits the nodes to be connected among themselves to retrieve a local attribute after topology changes.
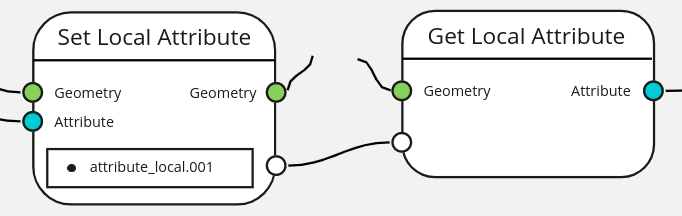
Local attributes are not outputted in the final geometry. To do that a Get Local Attribute node needs to be connected to an Attribute Output node. Those attributes will be clearly indicated in the spreadsheet.
Built-In Attributes
Built-in attributes are attributes whose type and domain is fixed and cannot be changed.
Some attributes can be expected for any geometry. It is safe to access them directly by name. For example: “position”, “material_id”, “radius”.
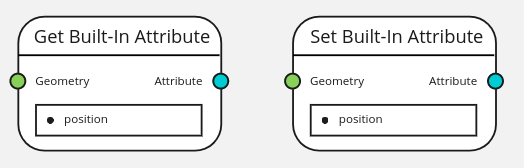
They may just be the same nodes as Set/Get Local Attributes, making both built-in and local clearly distinguishable.
Object Info
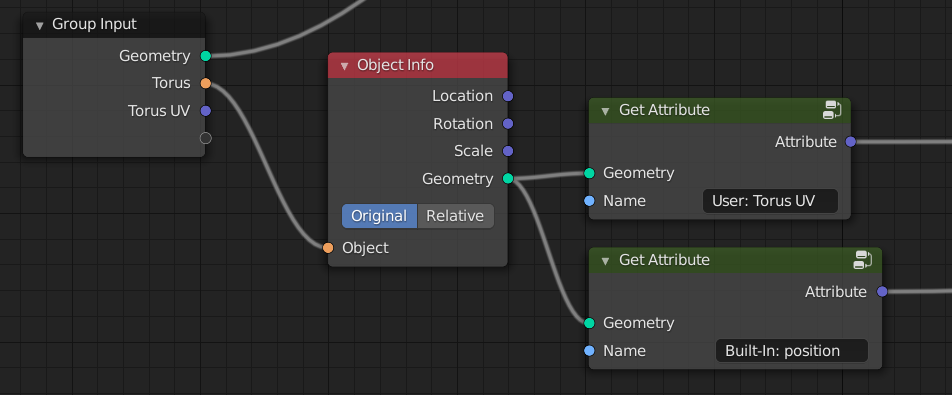
When the object comes from outside, its attributes should also be defined outside.
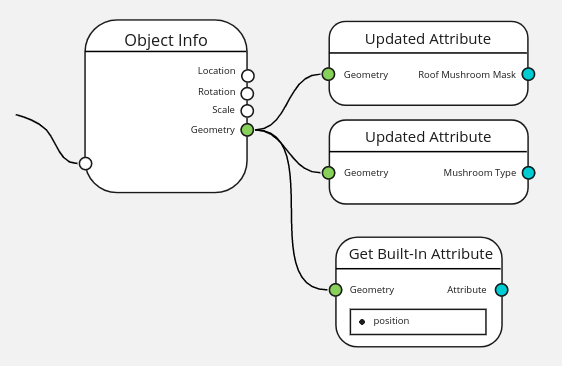
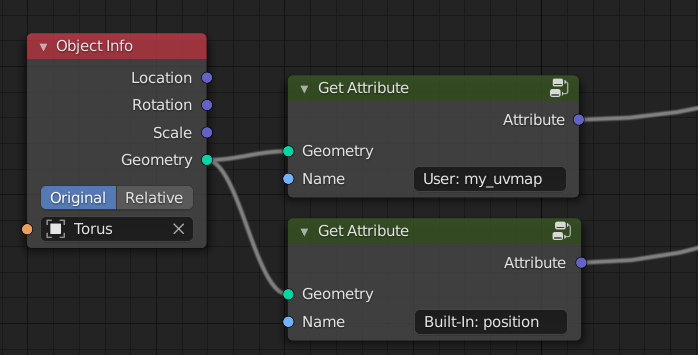
However when the object itself is hard-coded, the name of its attributes are also expected to be hard-coded. In this case the attributes need to be accessed with one of the Get Attribute nodes.
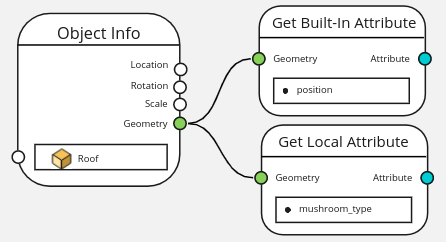
Pain Points and Extra Notes
- Get/Set Built-In and Local attributes nodes could be unified in a single node combining both namespaces.
- For the geometry and attributes to be unrelated we need to write all the attributes to all the geometries.
- We still need a way to access user attributes for the Object Info node when hard-coding attributes.
- The name of “Updated Attribute” is not the greatest.
- Backward compatibility is possible for most of the nodes. If not, Blender 3.0 is the time we can permit Blender to break this anyways.
I believe that having a single Get/Set Attribute node that contains all the available attributes solves the main issues here. I left them as separate nodes in this proposal for overall clarity:
- When getting the geometry from the Group Input only the built-in attributes would be available.
- Local attributes can be explicitly stored along the tree.
- When getting the geometry from the Object/Collection Info nodes the user attributes (UV, …) would also be available, beside the built-in attributes.
- In the attribute property search and the spreadsheet it should be easy to tell the attributes apart (built-in, user and local).
See updated proposal - basically unifying Get/Set nodes.
Examples
All these examples already include the unified Get/Set nodes.
Storing local selections to re-use after topology change for extrude operations:

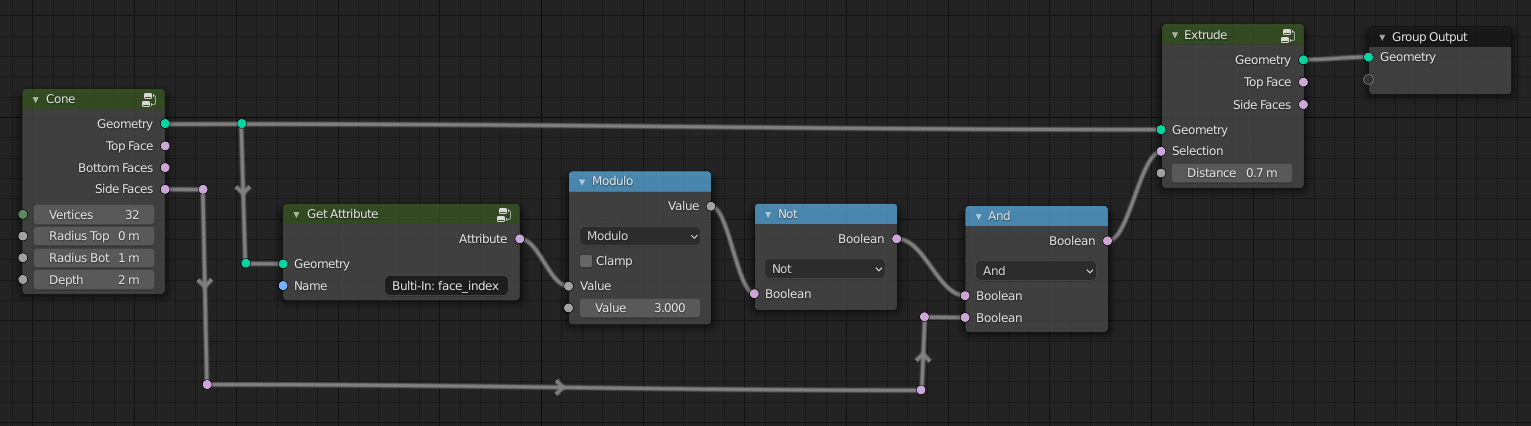
Extrude every Nth face:
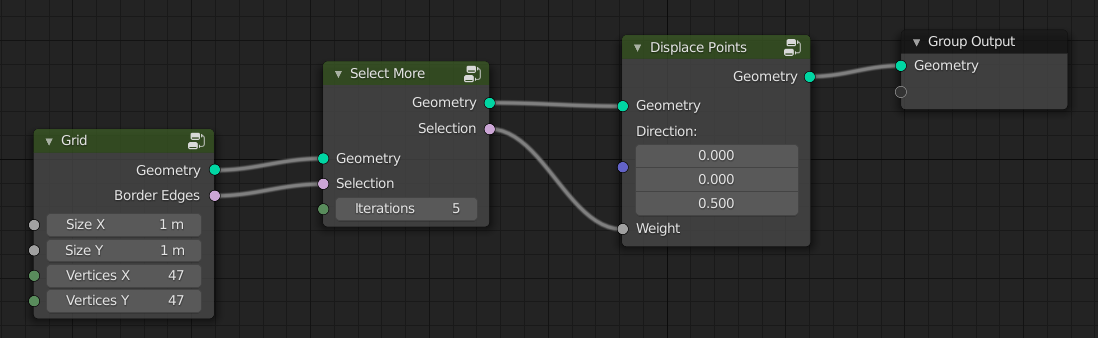
Select More used to displace points around. (note that in this case the result is the same as the fields proposal).
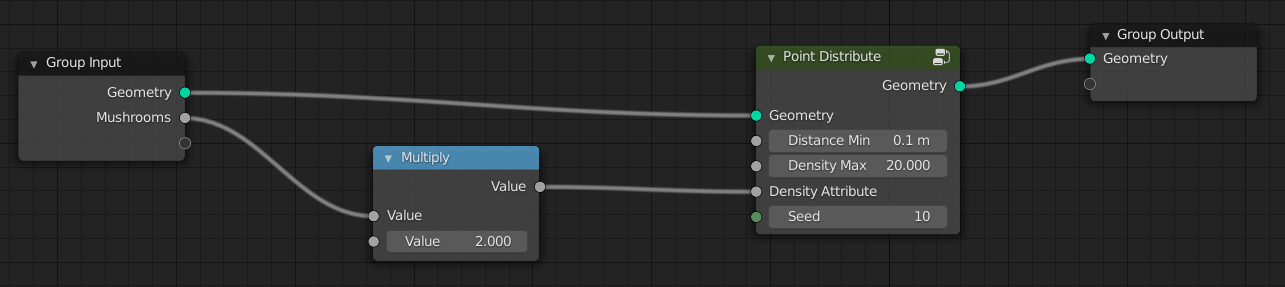
Distribute Points with multiplied attribute:
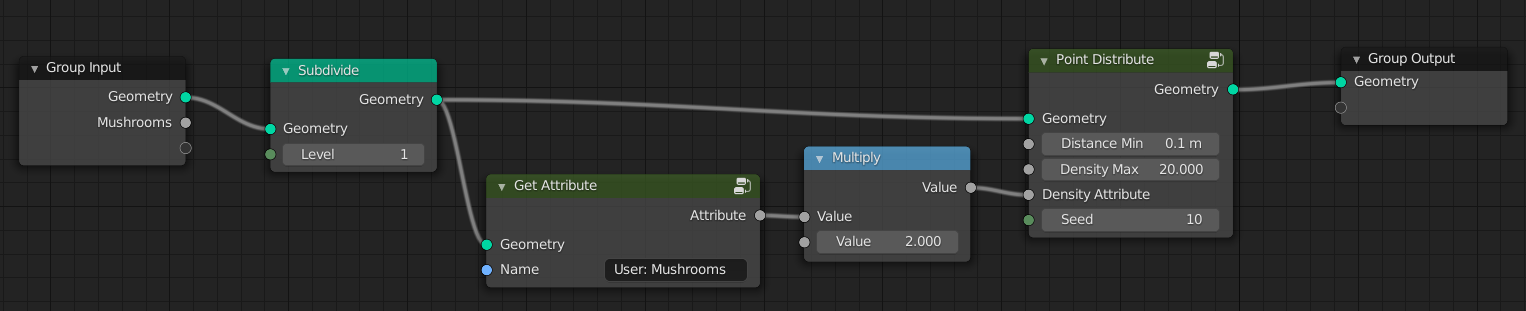
Distribute Points with multiplied attribute and topology change:
Object Info when the object is defined inside the nodetree:
Object info when the object is defined outside the nodetree:
Comparison with Fields
The Get Attribute Node would be similar, the difference is that for Fields, the Get Attribute Node has no Geometry input. Things get very different when we talk about Local Attributes though.
Fields require no local attributes since attributes can be passed around anonymously. With this proposal you have to be explicit about Setting/Getting those attributes if you need them after topology changes.
One possibility I contemplate is to use Fields only for anonymous attributes. That makes it more similar to passing attributes as reference. I haven’t thought about all of its implications though.