I did a little experiment a while back with the prototype branch. I have two versions of the same node tree.
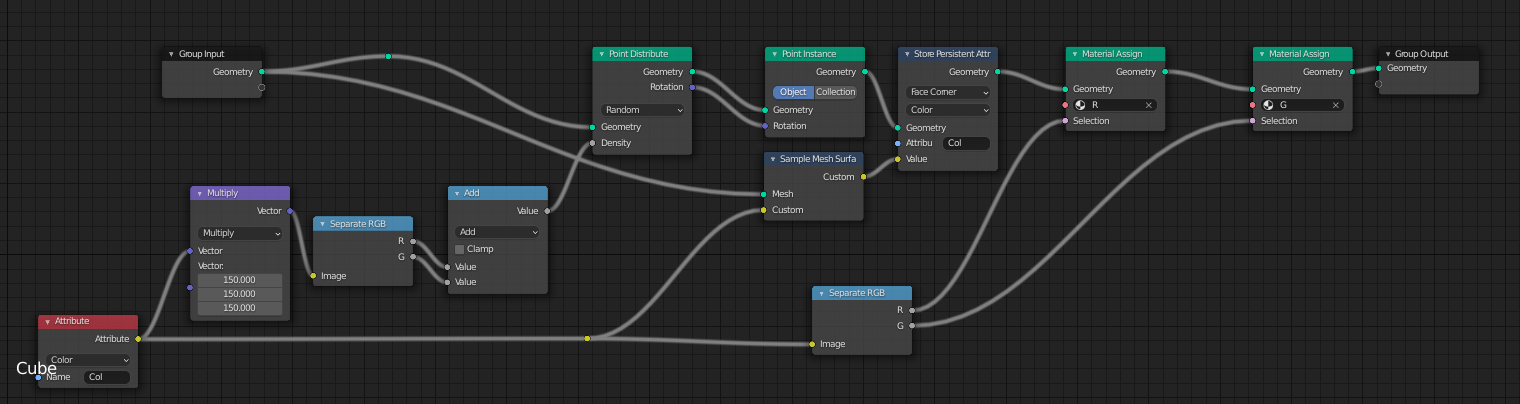
The first one tried to use less nodes but have some long connections.
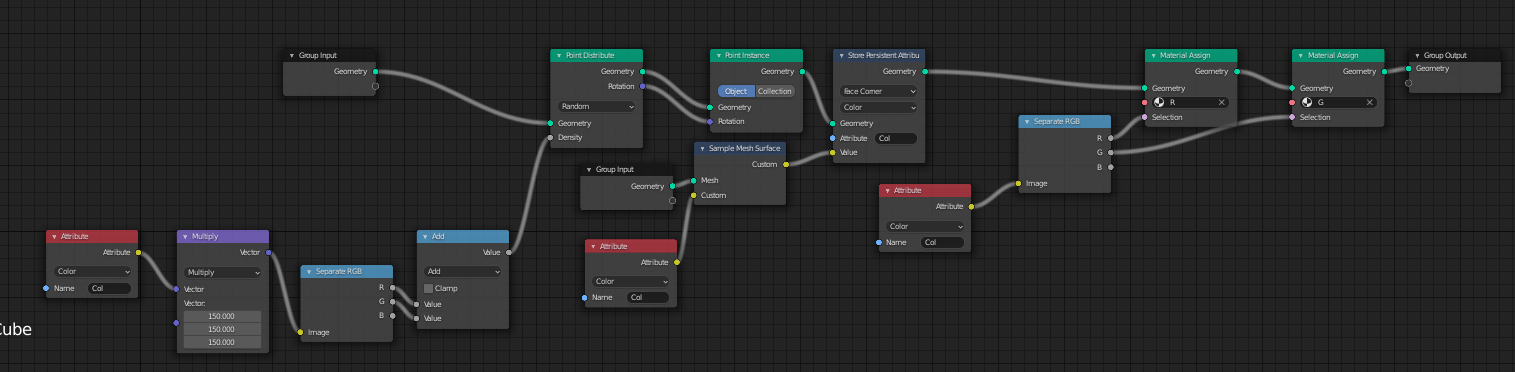
The second one tried to eliminate long connections by using duplicated nodes.
And I took these two screenshots and ask people which of them they think looks less messy. Most people around me picked the “more nodes but shorter connection” one.
I started to duplicate the group input node around ever since.
So I would lean towards the smaller nodes, I beilieve having them in their own shift A category is already enough for organizing, now they feel all over the place just because they are mixed together with other types of input nodes. It would feel nicer after they are in their own category.
EDIT: I just recalled this, the reasons why Attribute Processor was abandoned:

So it is an officially admitted problem, and new nodes should avoid stepping in the same problem as the old nodes I think.