This is just my thoughts following on from some of the ideas put forward in the Nodes Workshop.
I am a big proponent for handling the data in the node tree as lists (or attribute columns) as opposed to as attributes that are irreparably tied to the enigmatic “Geometry” socket. I think attributes are an excellent solution to sharing parametric data around Blender, especially as we gain more editors, and they also make sense for being able to send data long distance within a node tree where the noodles would clutter the view.
People have always talked about the issue with very linear node trees caused by the attribute workflow but a lot of the feedback that I’ve had through YouTube or Discord has been about how unreadable they make the logic and how slow it is to create a system. I do appreciate that the Attribute Processor’s task is to change the workflow to allow nodes to be used as in shaders with visual connections that allow for reading the logic and therefore no typing out attributes. I would maybe argue that if the processor is being added to cover a UX issue, perhaps the solution would be to roll out that workflow paradigm more widely. The Attribute Processor still has the issue that it can’t create new geometry, it only manipulates existing attributes on existing geometry which makes its utility in a true parametric modelling setting somewhat limited.
A disclaimer; my main experience comes from Grasshopper (for Rhino3D) and Sverchok (addon for Blender) and a little Animation Nodes (addon). I have used Geometry Nodes fairly extensively but I am coming to it from tools that are more focused on lists of data. I am also only an artist with effectively zero understanding of limitations and impediments under-the-hood with developing this kind of system.
For ease I will just illustrate these use cases with Sverchok although I’m not suggesting to copy the workflow, just to show simply common modelling techniques that benefit from columns sans geometry.
-
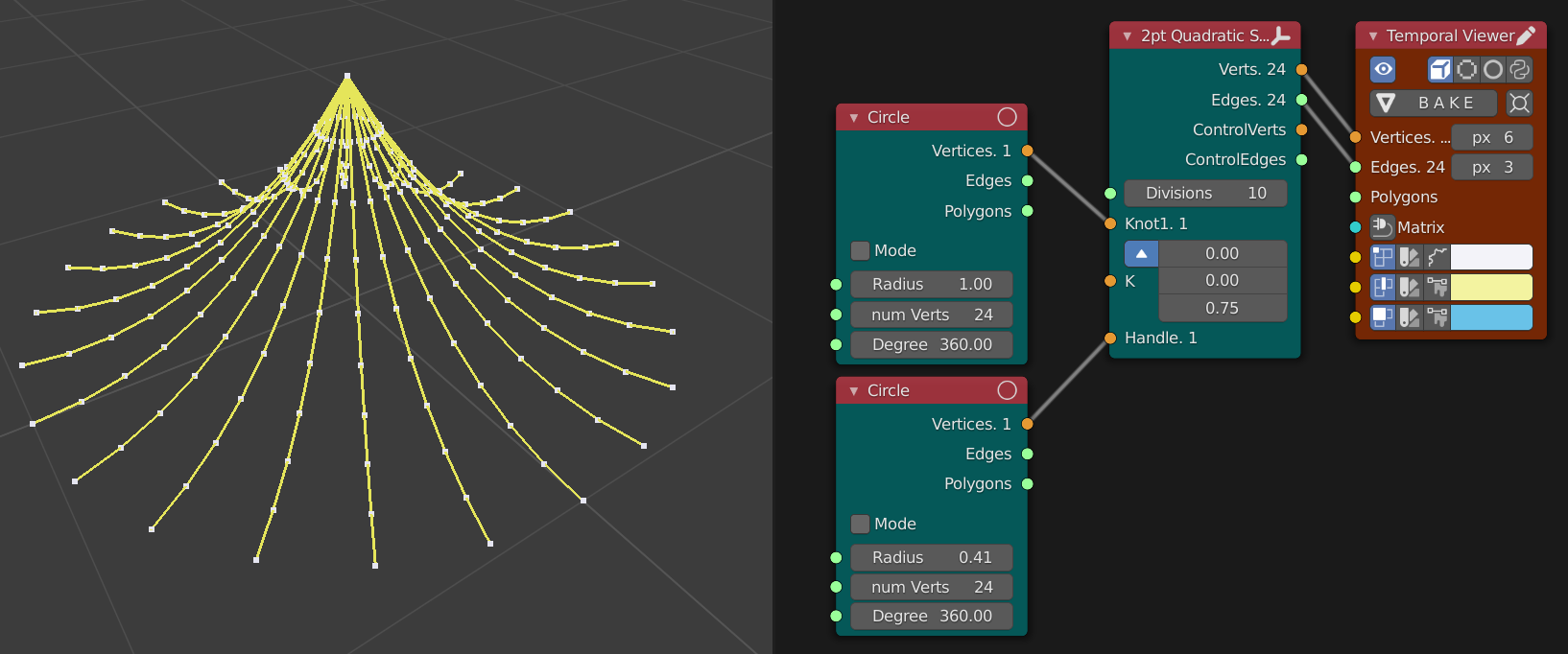
Use of
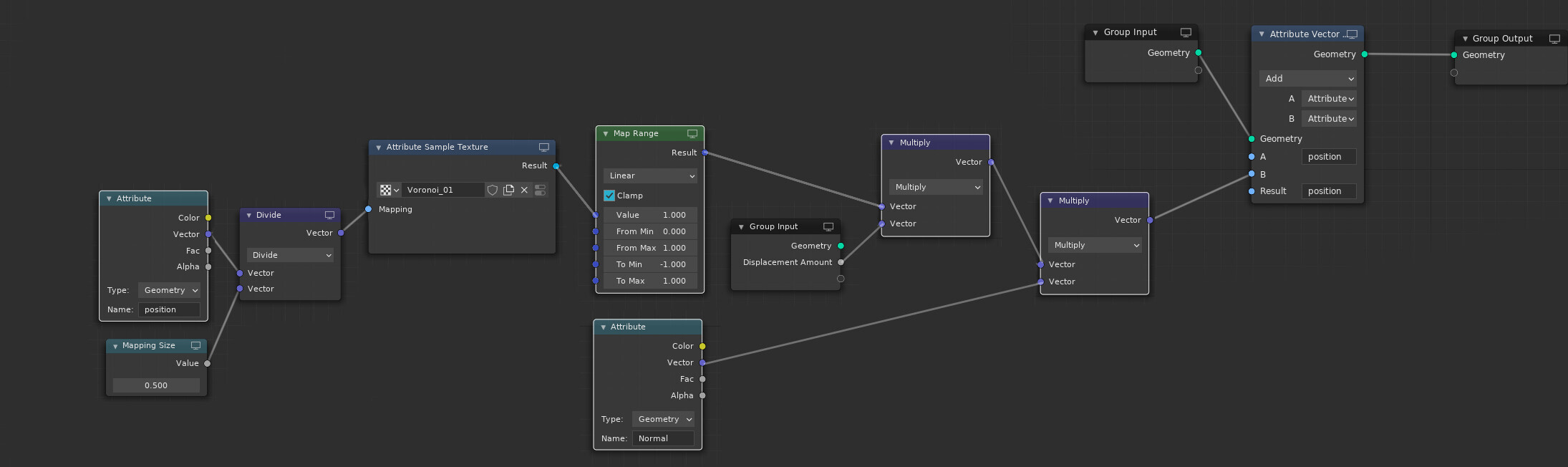
positiondata from one mesh being used as an input for another mesh.
In this case, the initial circles have 24 vertices and so 24 quadratic splines are generated.
The Knot1 and Handle inputs are receiving a list of 24 vectors and Knot2 only has a single vector and so it is repeated to be common for all resulting splines.
-
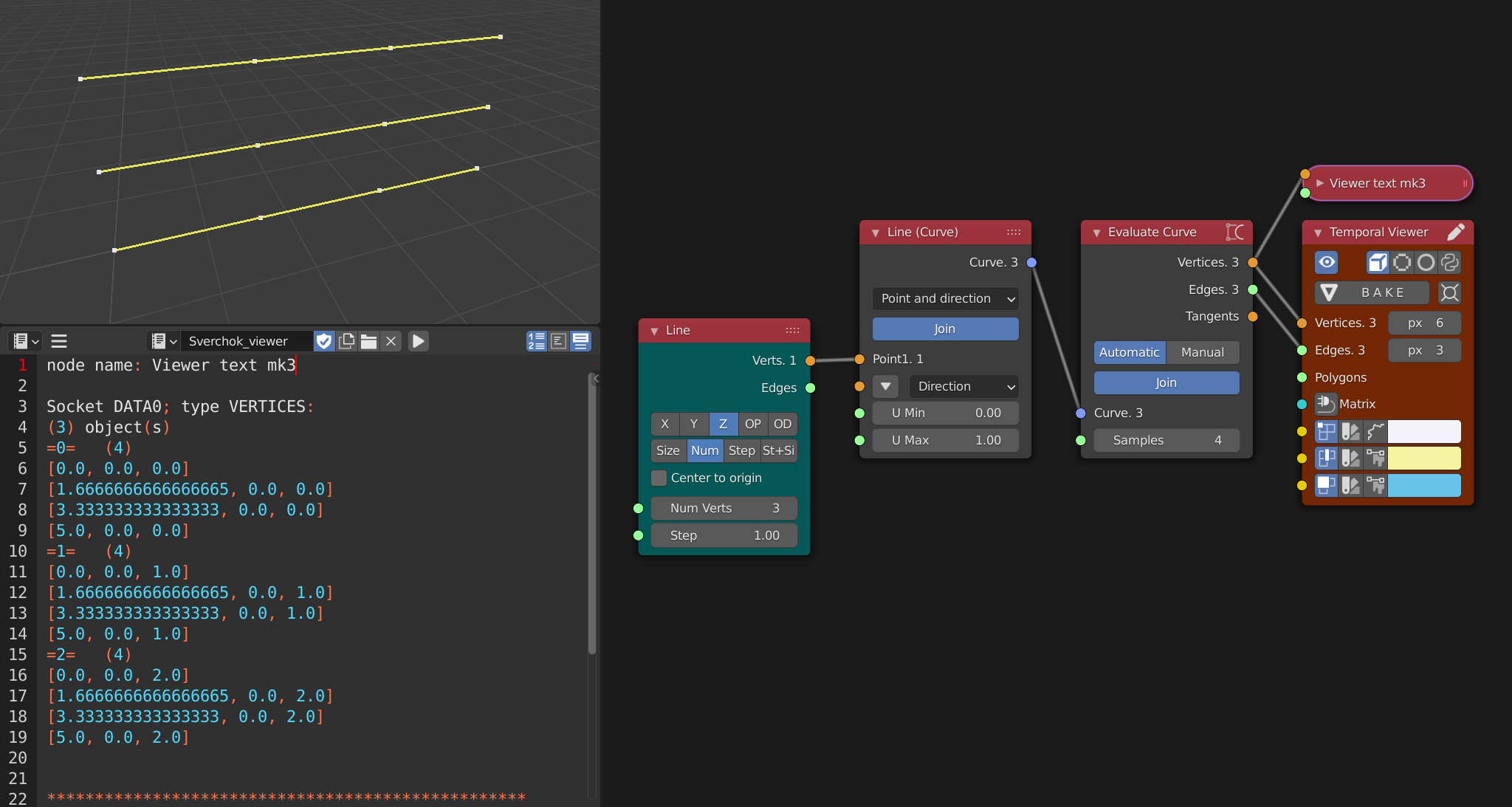
List Levels can be taken advantage of to be able to differentiate seperate elements within the same set
In this case we have one list of vectors coming out of the final node but we can see in the text editor that we have 3 discrete objects each containing 4 vectors. This is exceptionally useful for being able to join and separate elements as needed.
-
Curating Edge Flow
Little bit of a messy example but using List Shifting, Sorting, Shuffling etc can all offer the artist more authorship over the modelling process.
-
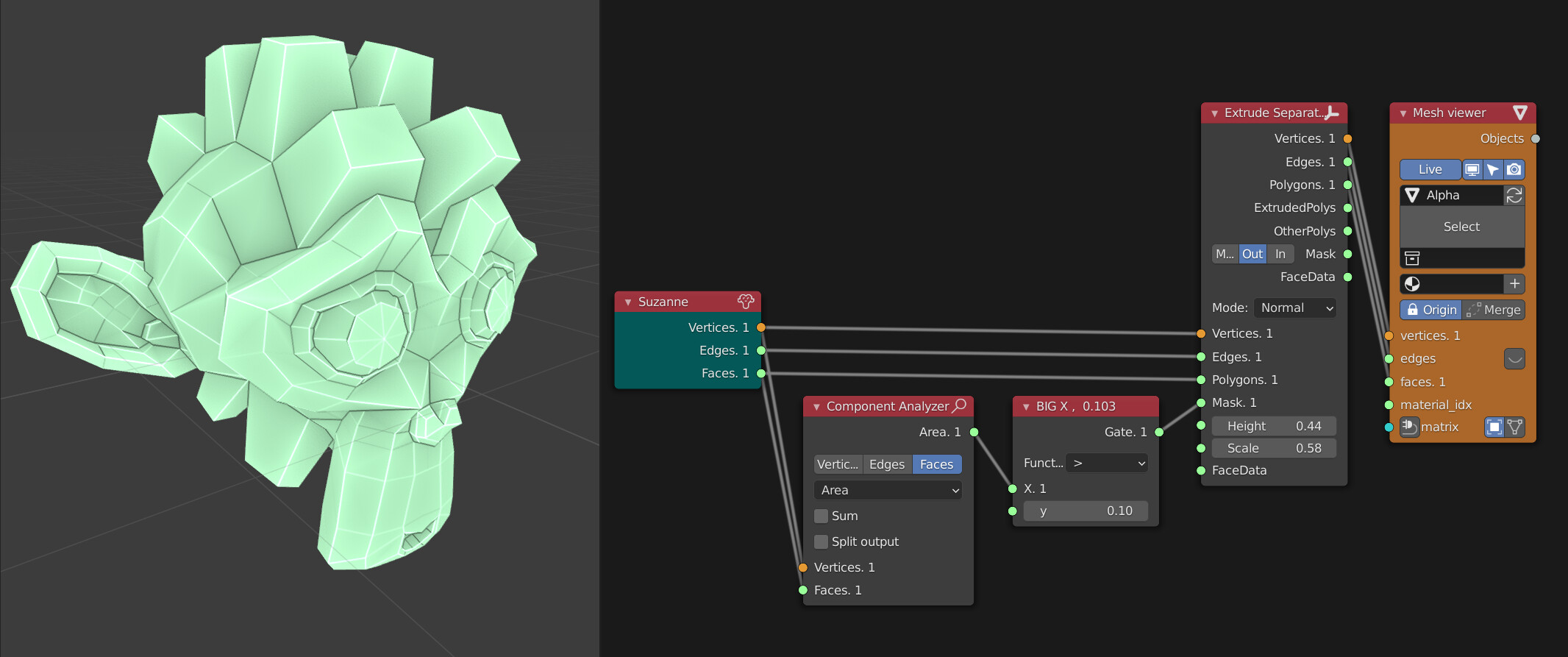
Creating selections and masks
Here Suzanne is getting a mohawk by masking faces by their area and then using that mask on the extrude separate node. This example could be as easily done with Attributes but in more complex systems the branching helps readability as well as using the data in other parts and even other geometries.
-
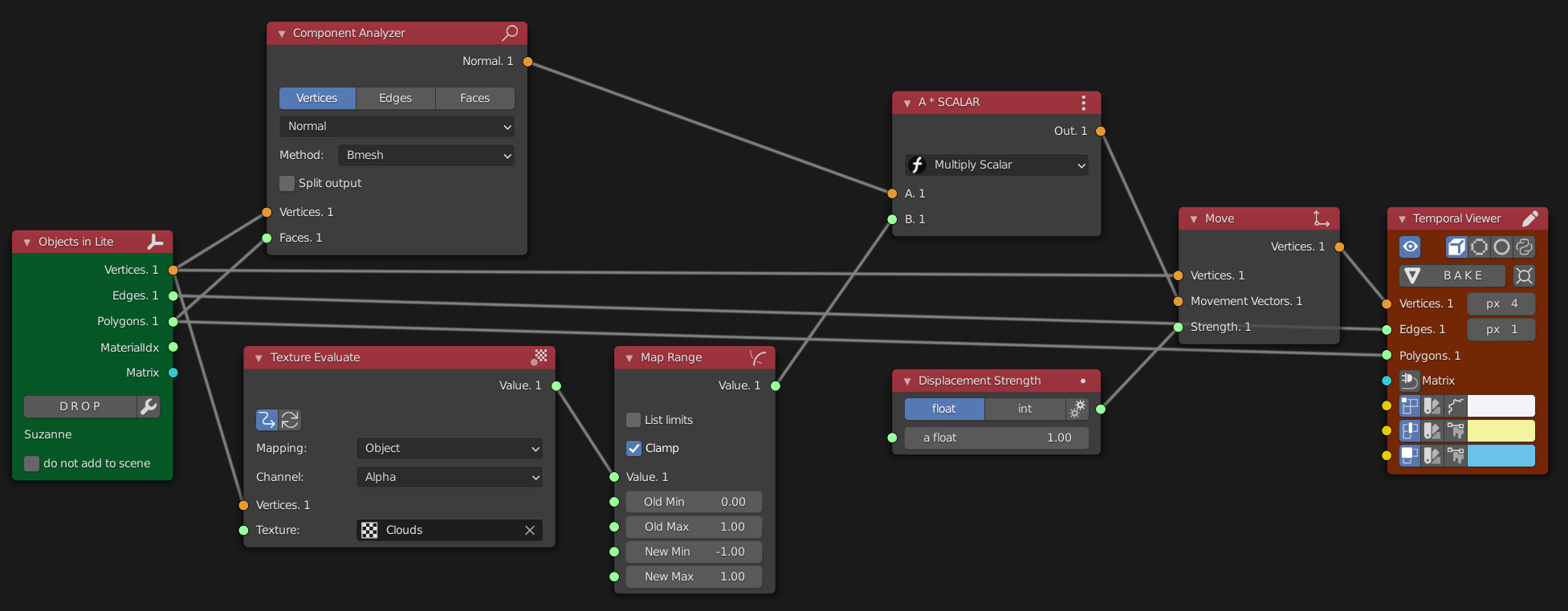
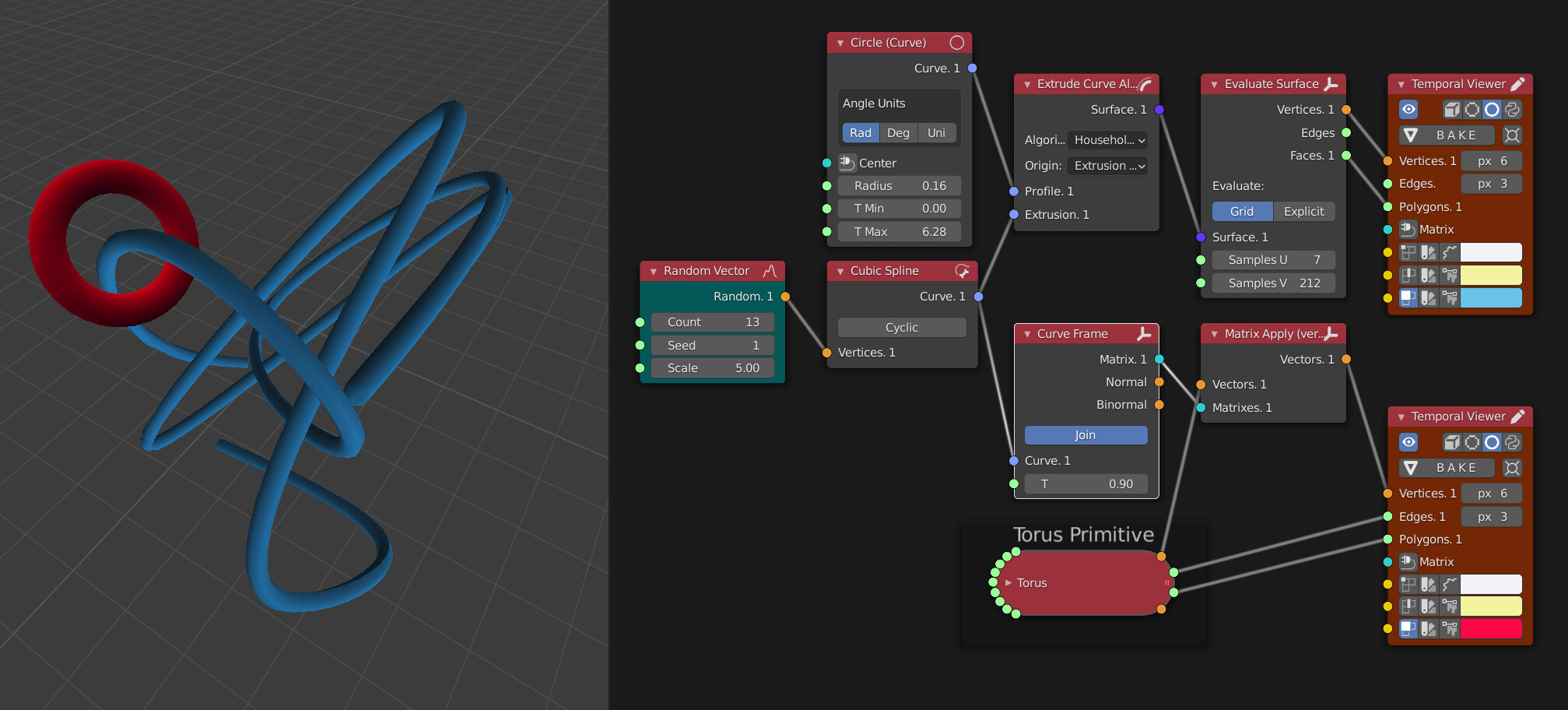
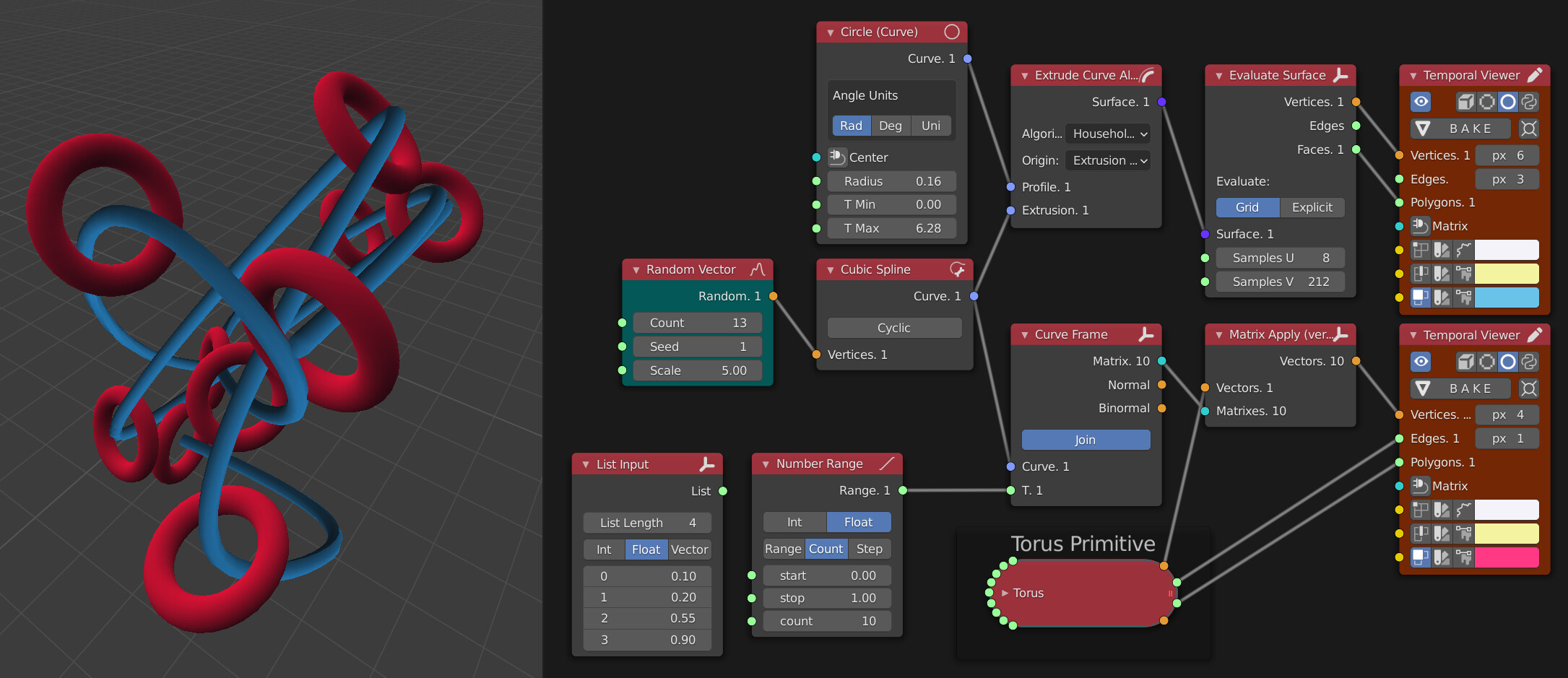
Analysis data from one object can easily be used to control any aspect of another
Here an initial list of random vectors is used to create a cubic spline. Along the top row a circle gets lofted along the spline to create a pipe surface (not disimilar to the current Curve to Mesh node in Geo Nodes but we’re able to maintain the superior parametric features of curve / surface workflow).
Along the bottom, a curve frame is generated from the initial spline object which is essentially a transform matrix. That matrix is applied to the vectors being output from the Torus primitive node. As none of the order is altered, the edges and polygons don’t fail during this transform.
Alternatively a list of float values can be used to analyse the transform matrix at multiple positions along the curve. An artist is able to maintain absolute control and use a manual list input or else generate a list of values (or control it by analysing another part of the model).
-
Readable Logic
There are some benefits of the attribute workflow but legibility is not one. The challenge of revisiting an un-commented node tree, especially if you’ve used and reused burner attributes. It’s not really feasible to understand what’s going on because string nodes will be connected to many different sockets, controlling different data at different points.
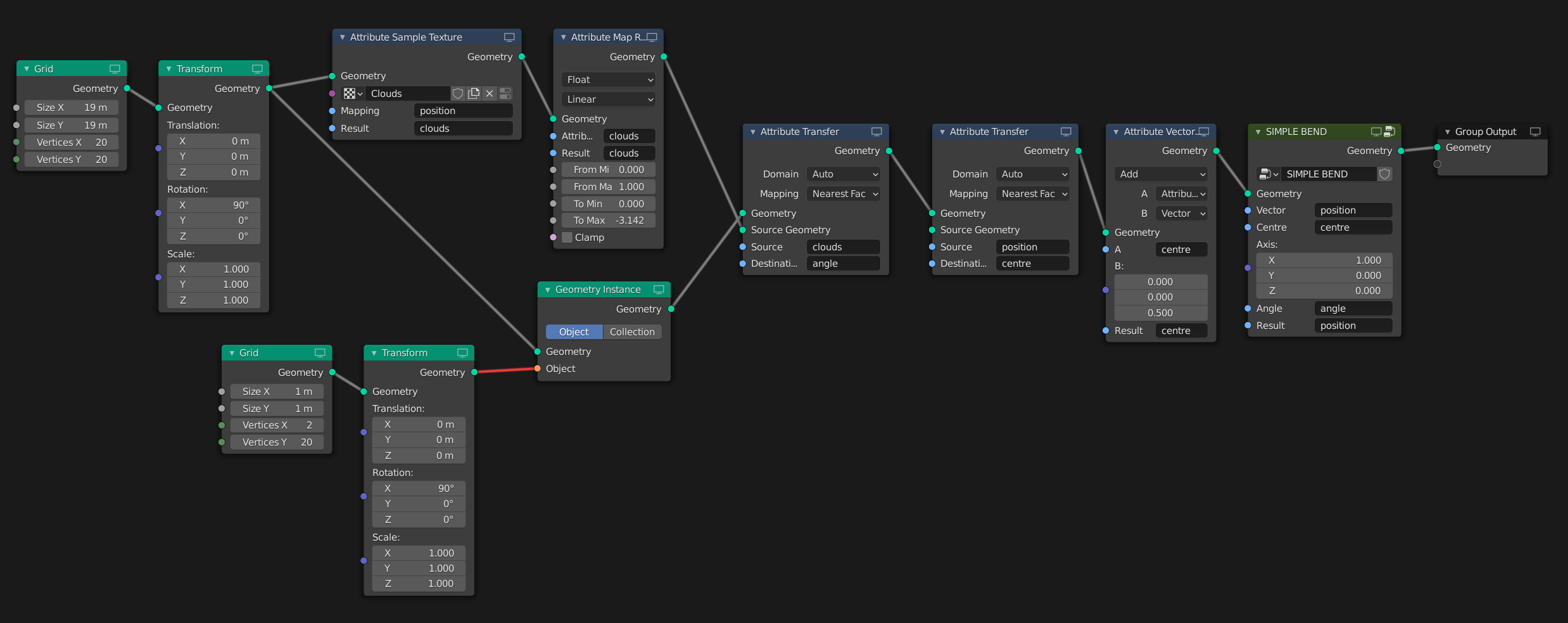
For example this is the UV Sphere node from my Geometry Nodes Toolkit (I made a custom node for it to work in extra attributes and functions such as index, U and V limits etc) and the logic is unreadable to anyone who doesn’t already know how to plot the points of a UV Sphere.
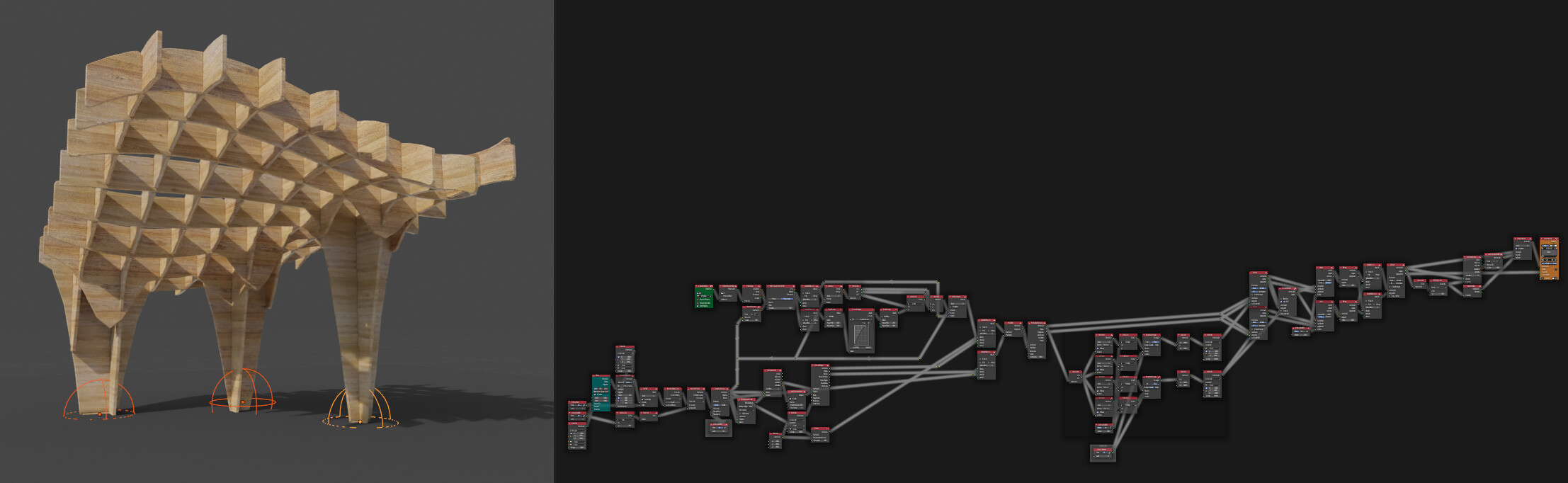
Compared to this example of a freeform waffel structure where I can still go into the (un-commented) node tree and understand what each collection of nodes does 6 months on.
-
Choosing specific elements
In this example the nodes off-screen to the left have created an irregular hexagon grid. The grid is exploded to create 85 discrete faces with unique vertices. This changes our list of vectors from 1 object containing 216 vectors, into 85 objects, each containing 6 vectors. We’re then able to selectively choose an object by its index.
I’m then able to use a manual list input to separate out the vectors for the left and right side of the shape. Two lists of 3 vectors allows me to create 3 different horizontal Line curve primitives from which I can evaluate the 3 centre points. These vectors then are moved using another list input to shape the panels manually. The nodes on the right take each set of 3 vectors and create an arc, aligned vertically, which is then used to to create the actual surface which can be instanced on the face centres of the initial hexagon grid to create the panel array.




I think one of the current problems of Geometry Nodes is the idea that geometry needs to be made and then modified. Any float list could be combined to create a vector list and any vector list could be read as vertices and the length of a list should be able to be changed on the fly based on the initial inputs rather than being restricted to what geometry is already existing. Especially relevent when doing this sort of entirely node-based workflow is having some method to mesh later on in the process. A large part of the process is going to be manipulating vectors without altering edge flow, in which case the other parts of the geometry can be inherited from the earlier stages (much the same as the current GN strategy with controlling the position attribute). For these more parametric workflows there’s often more of an emphasis on using curves and surfaces as opposed to meshes as you can easily evaluate points, trim, extend, join etc without losing the accuracy of your system. Compare this to using mesh objects and if you want to maintain accuracy you need extremely high resolutions right from the start. The parametric integrity and workflow flexibility of curves makes them an ideal tool in these systems.
I think there is more merit in the attribute workflow when Geometry Nodes is being used to create a complex modifier similar to Macros or Actions in other software. Even with the list workflow you can still take an input geometry, put it through some transforms, edit parts of it and then eject an updated geometry at the other end.
This rock formation takes a guide geometry as input, distributes points, separates into 3 levels, creates edges between levels 0-1 and 1-2 and then evaluates multiple points on those edges. These vectors are then used in Geometry Nodes with points to volume and volume to mesh. Several displacement modifiers, remesh, subdiv and displace later and it goes back into Geo Nodes for foliage. If this was all within Geo Nodes then that suddenly becomes a “Rock Formation” asset which allows artists to feed in only guide geometries and output macro rock structures for environments. I can imagine a similar utility for architectural panelling and types of common structure like waffel structures.

It feels like attributes should be used more around the edges as an artist when needing to get or set, the actual bulk of the handling of data and logic should be something visual and artist-friendly. There are many more use cases but legible logic and being able to intuit your way to an answer are two solid votes for list / attribute column workflow in my opinion.