Proposal for attribute socket types
DISCLAIMER: This is a proposal for what i personally think is a better approach to handling attributes in geometry nodes. It is NOT an official design document or planned work, just my own contribution to the discussion and a suggestion for improvement.
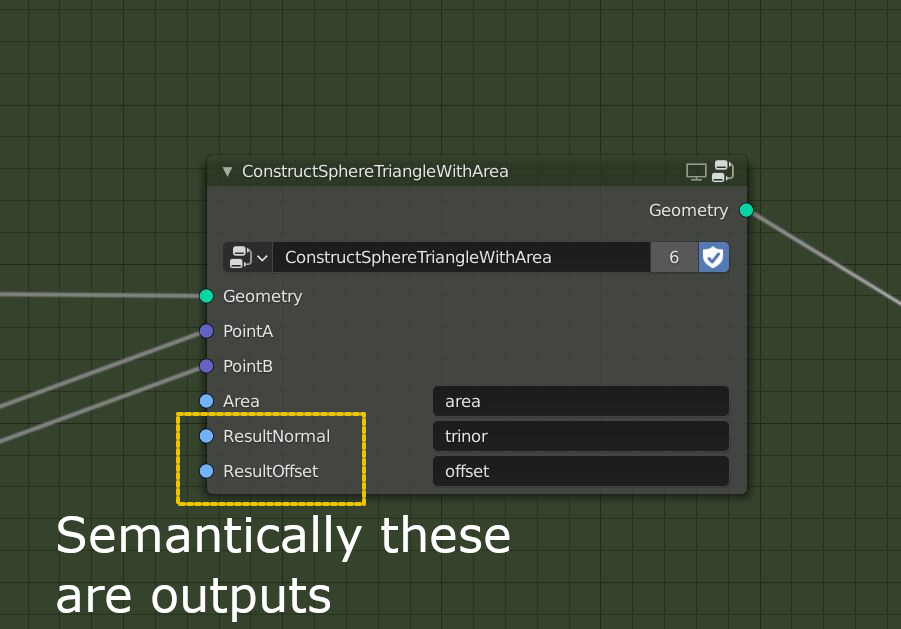
A new socket type (or multiple types, see (Socket types) is added, which represents an attribute reference. This works much like the current string references, but has some additional features that greatly simplify workflow.
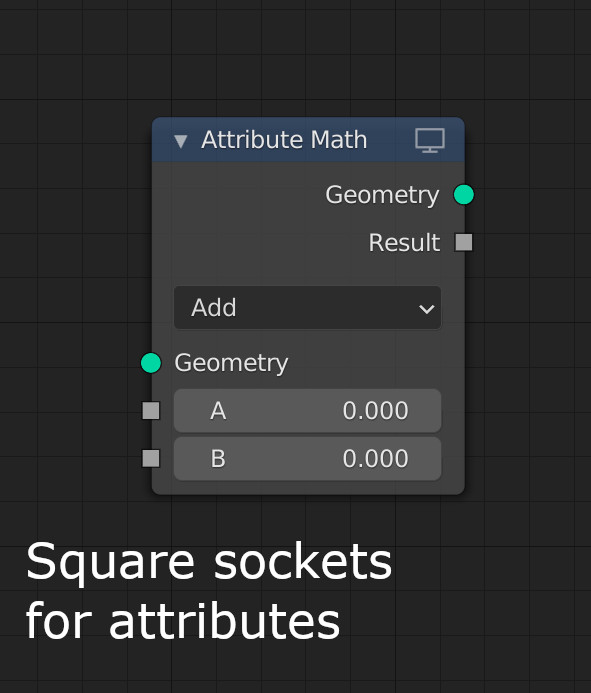
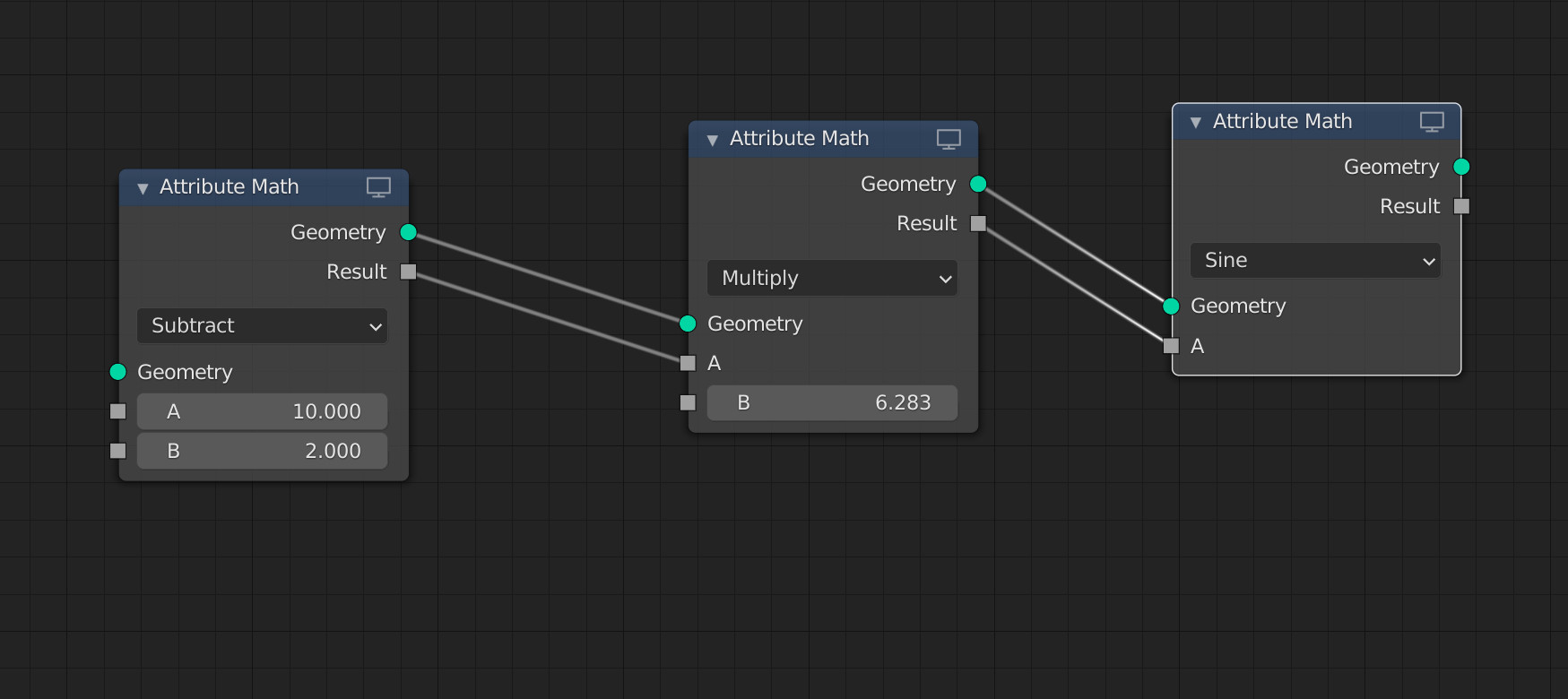
An attribute can be a node output, rather than an input that has to be named. Output attributes are named automatically. To the user the attribute is presented as unnamed, its internal generated name is largely irrelevant and only needs to be chosen such that it is unique and does not collide with user-defined attribute names.
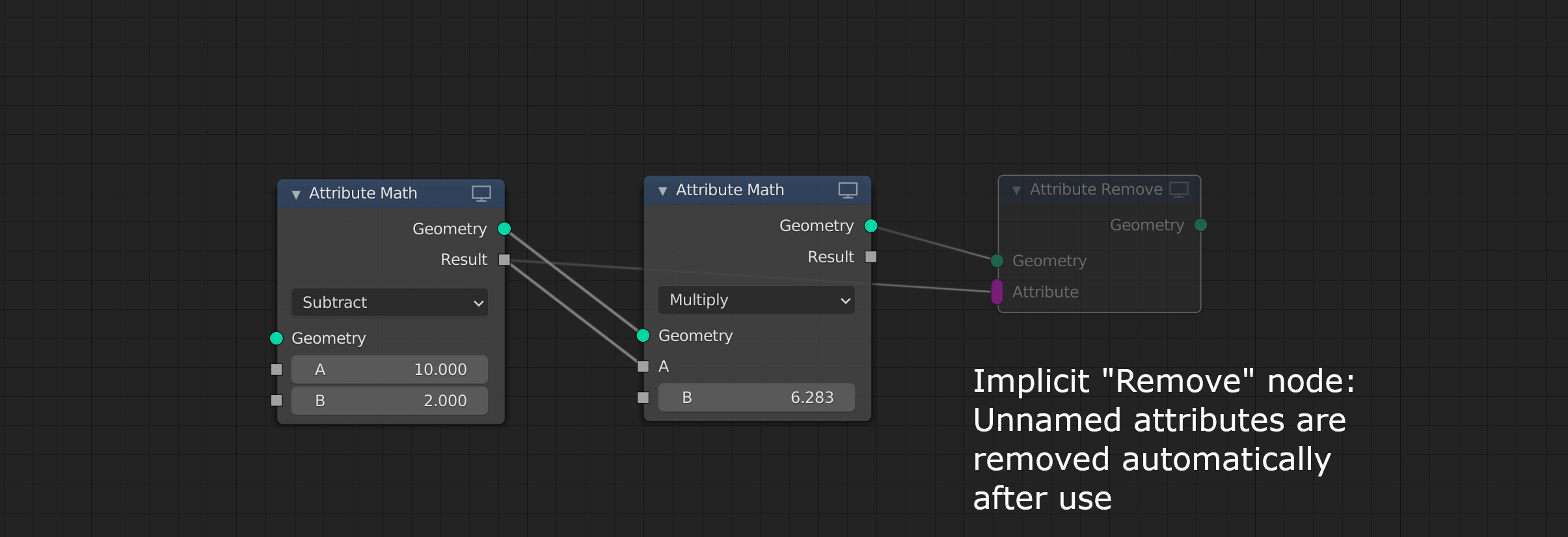
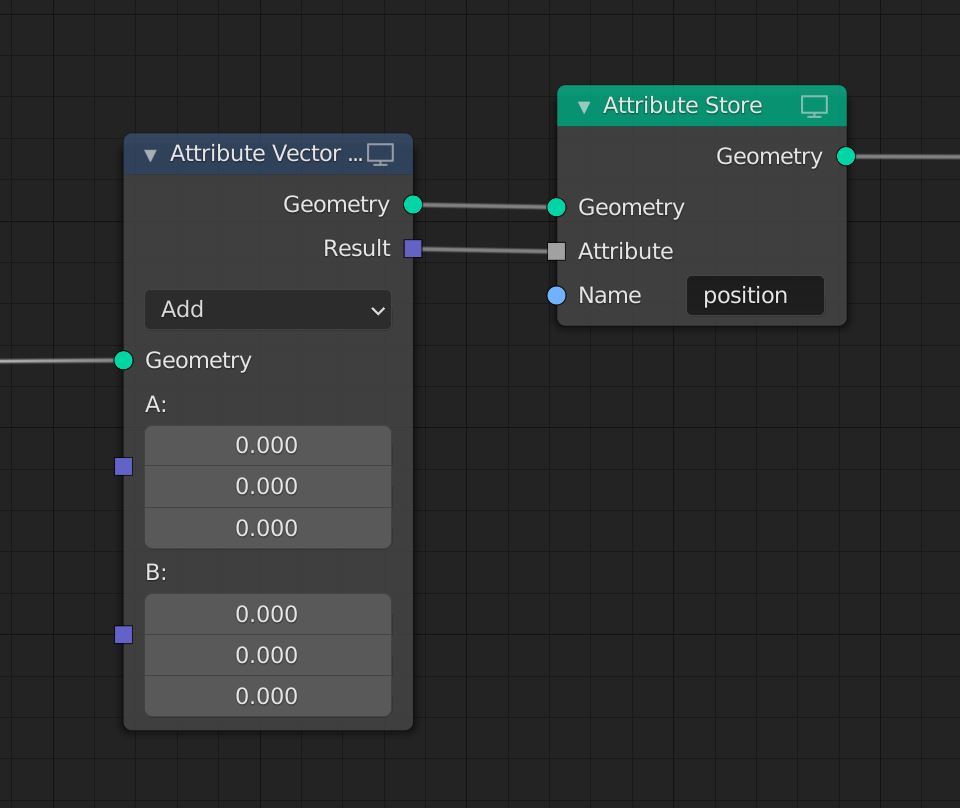
An unnamed attribute is automatically removed from the geometry when all nodes accessing it have been executed. The user does not need to remove such attributes explicitly. If an attribute is supposed to be persistent outside the node tree it must be stored with an “Attribute Store” node, giving it an explicit user-defined name (see Storing an attribute).
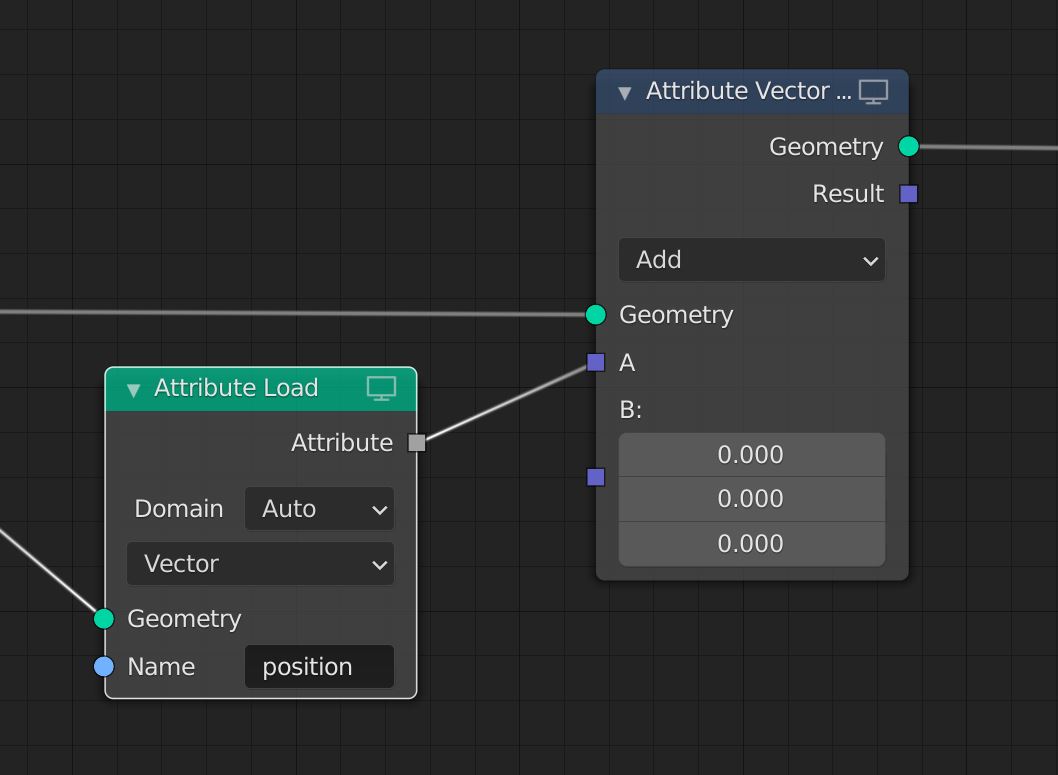
Attributes can be loaded from existing geometry layers with an “Attribute Load” node. This simply looks for an existing attribute name on the input geometry and initializes the attribute reference.
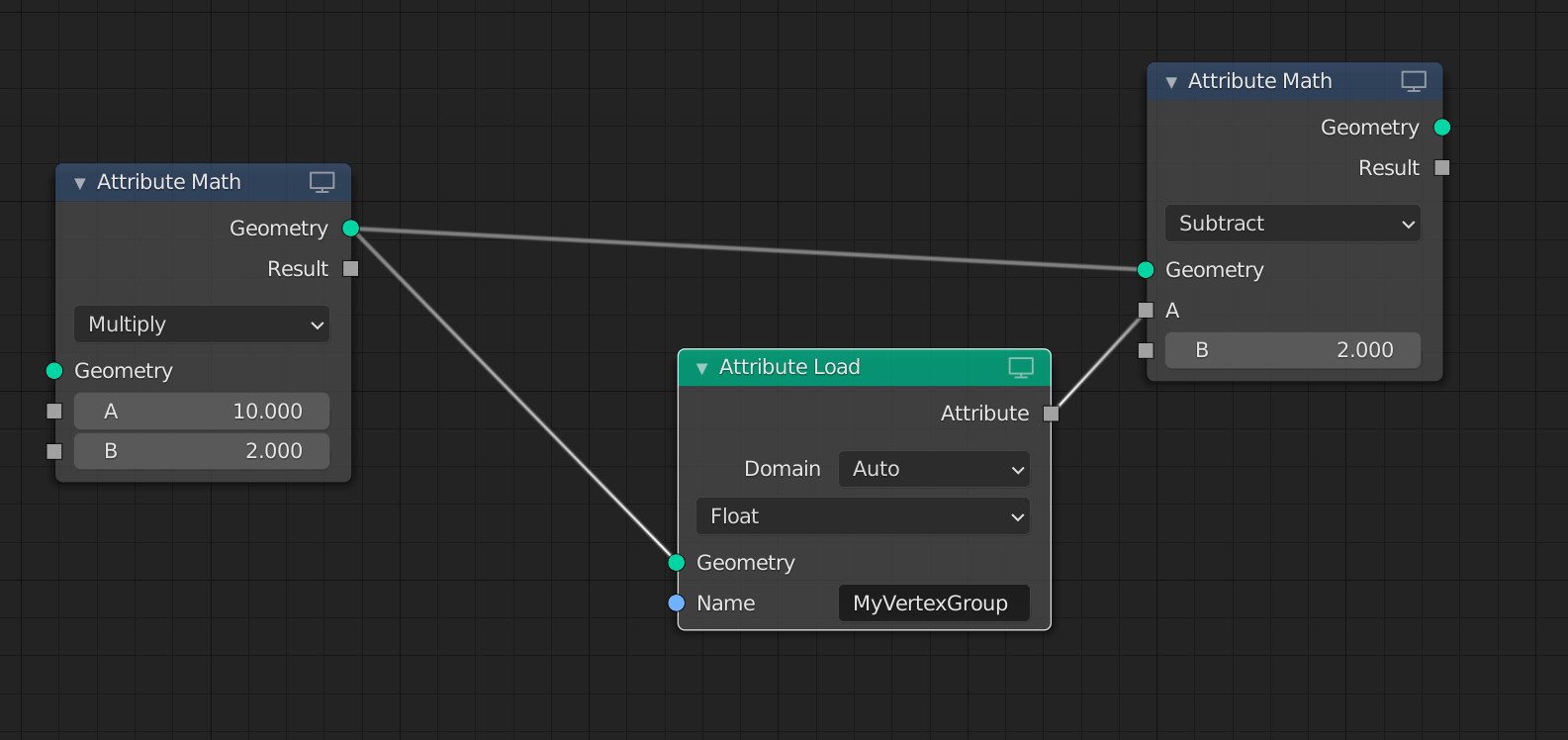
Attribute references associate a data type as well as an optional domain type with the attribute name. This should be handled with some flexibility, doing conversions between attribute types as much as possible, just like current string references do. Domain can be set to “automatic” to chose whichever domain type matches best in a given context.
Why is this needed?
Geometry nodes in their current state are powerful, but also very difficult to use beyond simple setups. The way attributes are referenced with explicit names adds a lot of visual noise and mental overhead:
-
Temporary attributes still require explicit naming. The user has to keep track of which names are used for which attributes, and where name collisions might occur.
-
Temporary attributes have to be deleted explicitly. This can also cause side effects if an attribute is supposed to be internal and transient, but an attribute with the same name is used inside a group.
-
Attribute changes are not reflected by node sockets.
For any other data type a socket represents a particular state of the value. That could be a simple number output from a math node, or a geometry set that is passed between modifiers. Attributes on the other hand are always referred to by the same name and the user has to keep track of what the state is at each point in the node tree.
-
All attributes become input sockets: The natural flow in nodes from inputs to outputs does not work, because there are no “unnamed” attributes.
The suggested implementation would generate unique disposable names for such output attributes which only become “real” persistent attributes once stored by the user deliberately (see Storing an attribute).
-
Operations that work element-wise (math nodes in particular) have to be specialized for accepting singular values.
This wouldn’t be necessary if the attribute inputs would just accept singular values and automatically treat them as “filled” attributes.
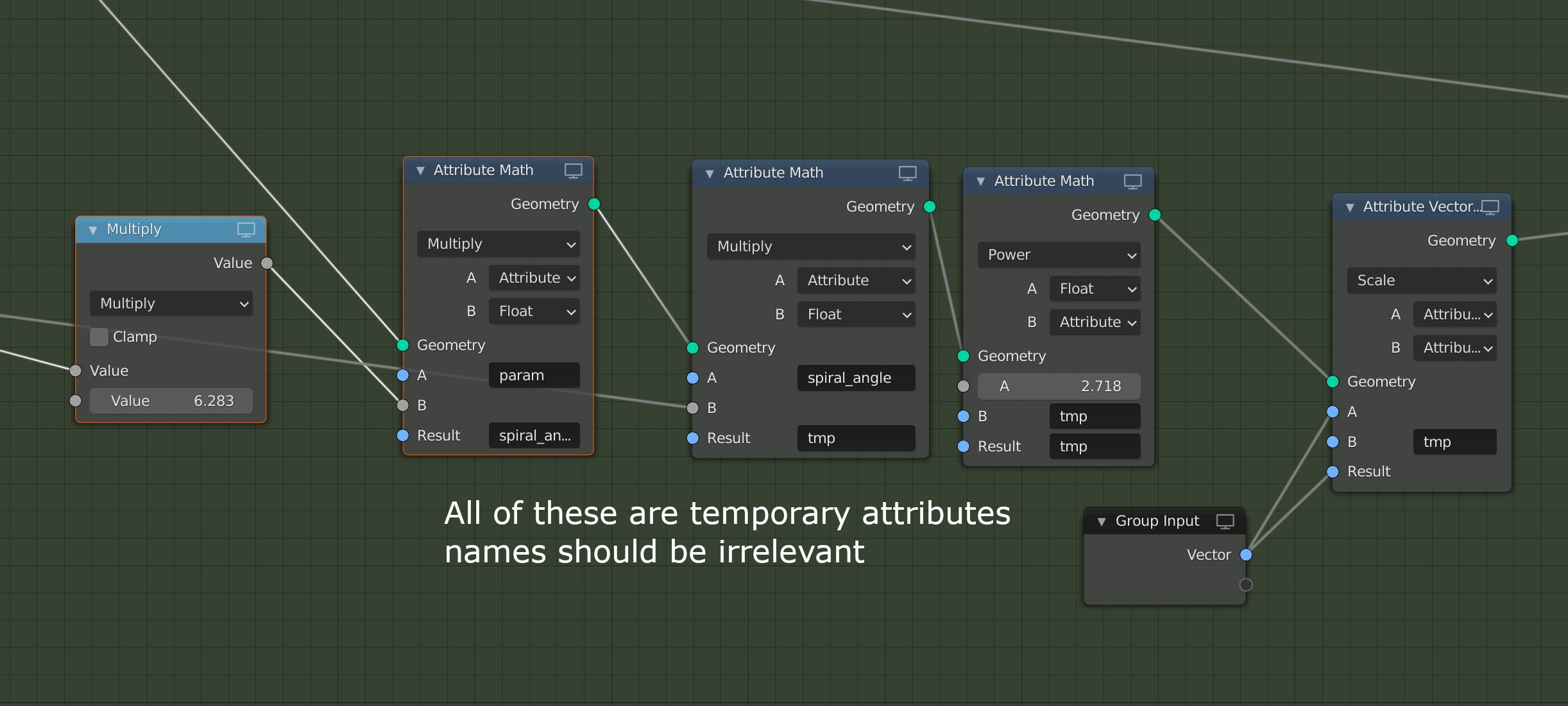
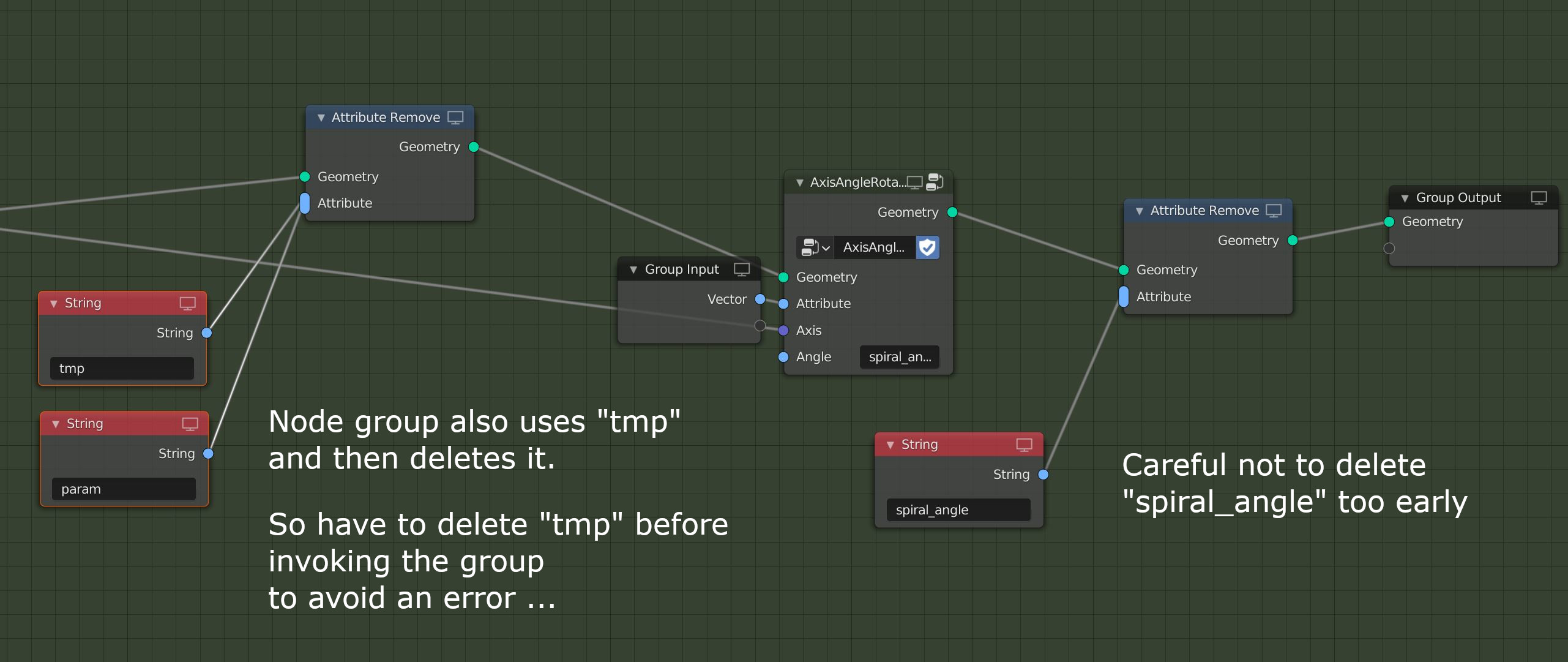
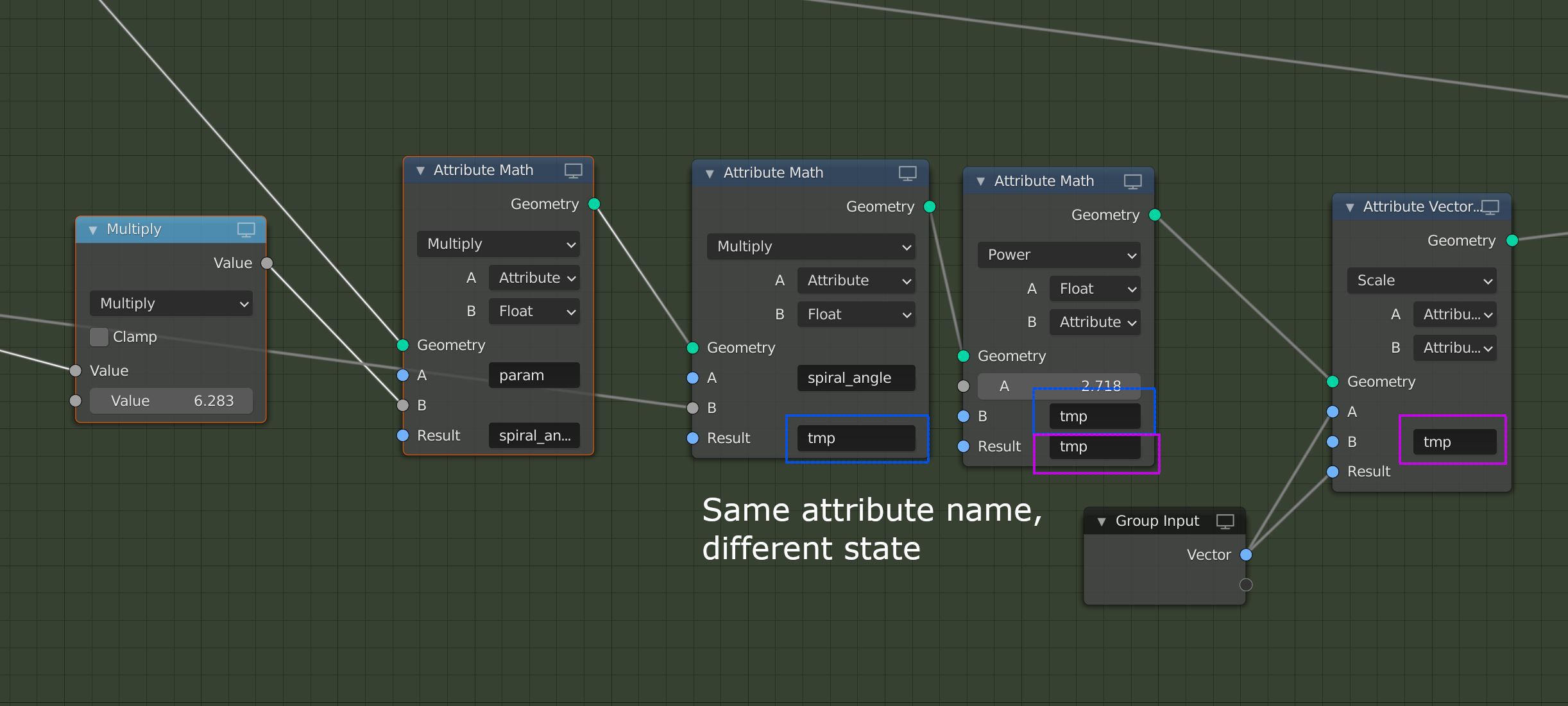

With the proposed changes, attributes would behave much more like conventional values in a node tree. This will reduce the mental overhead when constructing large and complex node trees. Attribute output sockets will keep connections shorter and localized. Broadcasting will remove the need to specify for each input whether it accepts singular values or attributes.
How does this fit in with the Attribute Processor?
The attribute processor node (D11547) will make a lot of math operations simpler and remove the complexity of string attribute references from most low-level computations.
However, modifier-like operations still have to be performed outside of the attribute node trees, e.g.
- Boolean operations
- Joining Geometry
- Subdivision
- Instancing
Passing attribute references between such higher-level nodes still relies on string references, input-heavy nodes, and explicit singular vs. attribute input switching. The changes proposed in this document could still have significant impact even when most of the low-level math is moved into attribute processor nodes.
Attribute socket types and broadcasting
Multiple typed attribute sockets for float/int/vector/color/etc. values exist on the UI level. Internally these are largely handled the same way. Different UI socket types are a convenience feature to allow default input values and give some indication of what attribute a node expects. A generic attribute socket could be used for nodes such as “Reroute”.
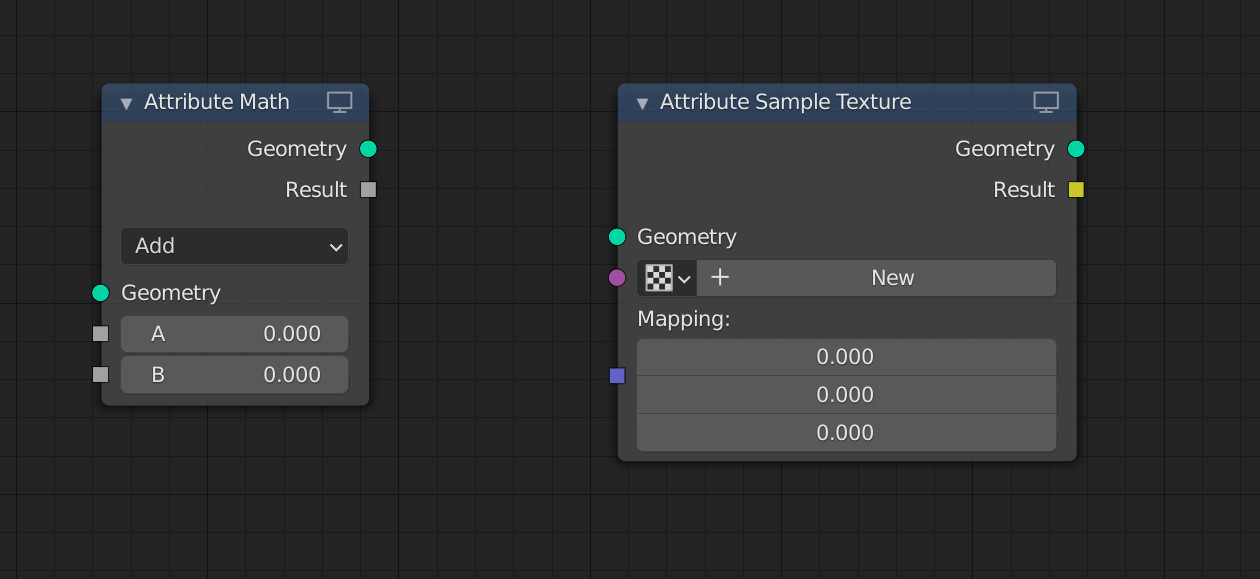
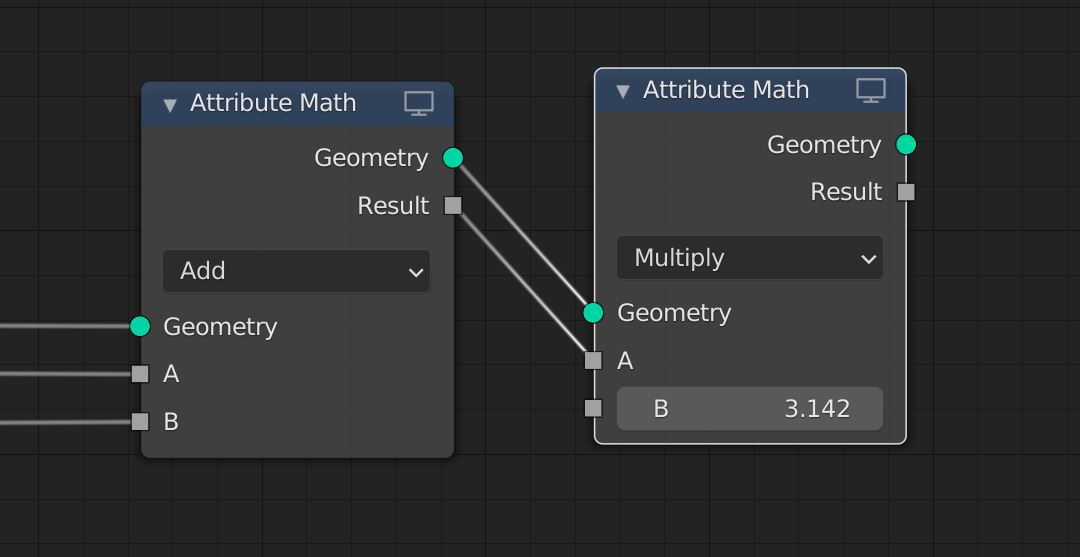
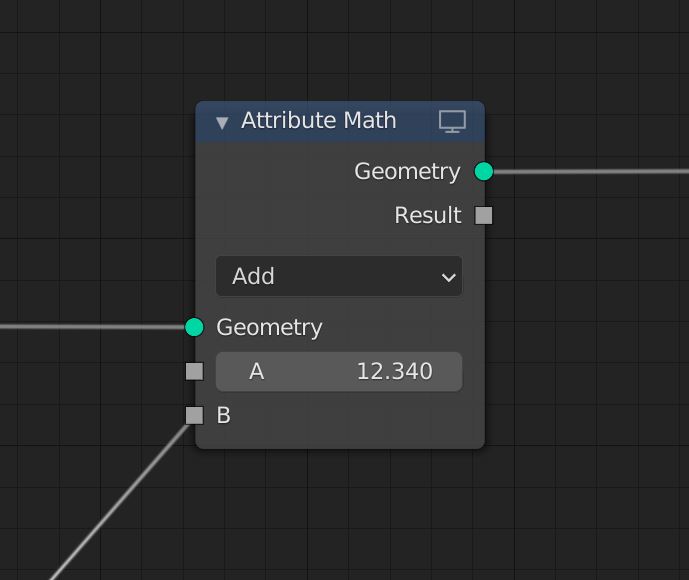
Attributes support broadcasting to simplify nodes that support both singular values and attributes (e.g. Attribute Math). A singular value can be connected to an attribute input, which is equivalent to an “Attribute Fill” node (see examples). Connecting an attribute to a singular value input is NOT allowed. In the future specialized nodes might be available for this purpose, but that is out of scope of this proposal (e.g. Attribute Sum/Average/MinMax).

The advantage of broadcasting is that specifying if an input is a singular value or an attribute is no longer necessary. A singular value can be connected directly to an attribute and will be implicitly broadcasted. If an attribute input is unconnected it will broadcast the default input value.
Future optimization: propagating input modes
The way geometry nodes evaluate does not leave much room for constant-folding right now. With broadcasting it would be possible, in principle, to reduce many nodes (like math nodes or the new attribute processor) to a singular value computation automatically if all inputs are singular values.
Determining if a node can be “constant-folded” depends on whether all inputs are singular values, which in turn depends on their source nodes, etc. (Some nodes may generate full attribute layers regardless of input modes).
Such optimization is outside the scope of this design document, but should be part of future work.
Equivalent Node Setups
The proposed system should not require fundamental changes to the execution of nodes as they are now. Below are listed a number of node setups in the proposed attribute style together with their equivalents in the current string-based system.
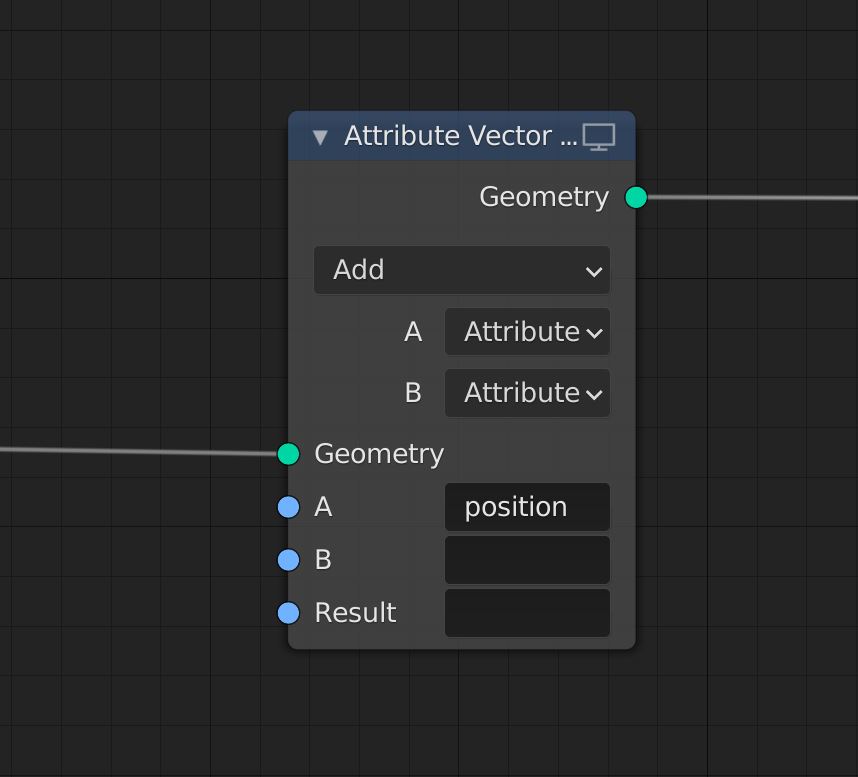
Loading an attribute with explicit lookup
Store an attribute to geometry and make it persistent
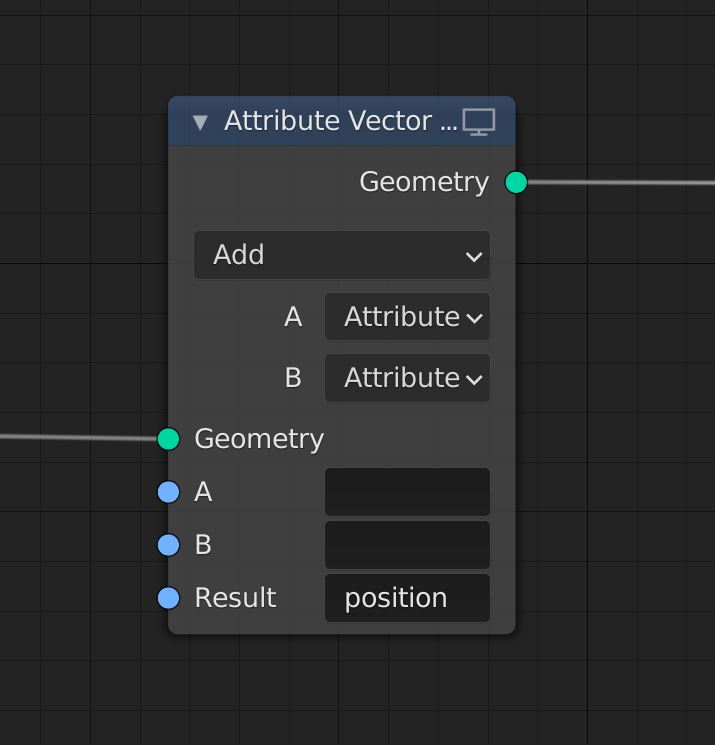
Broadcasting to an attribute input
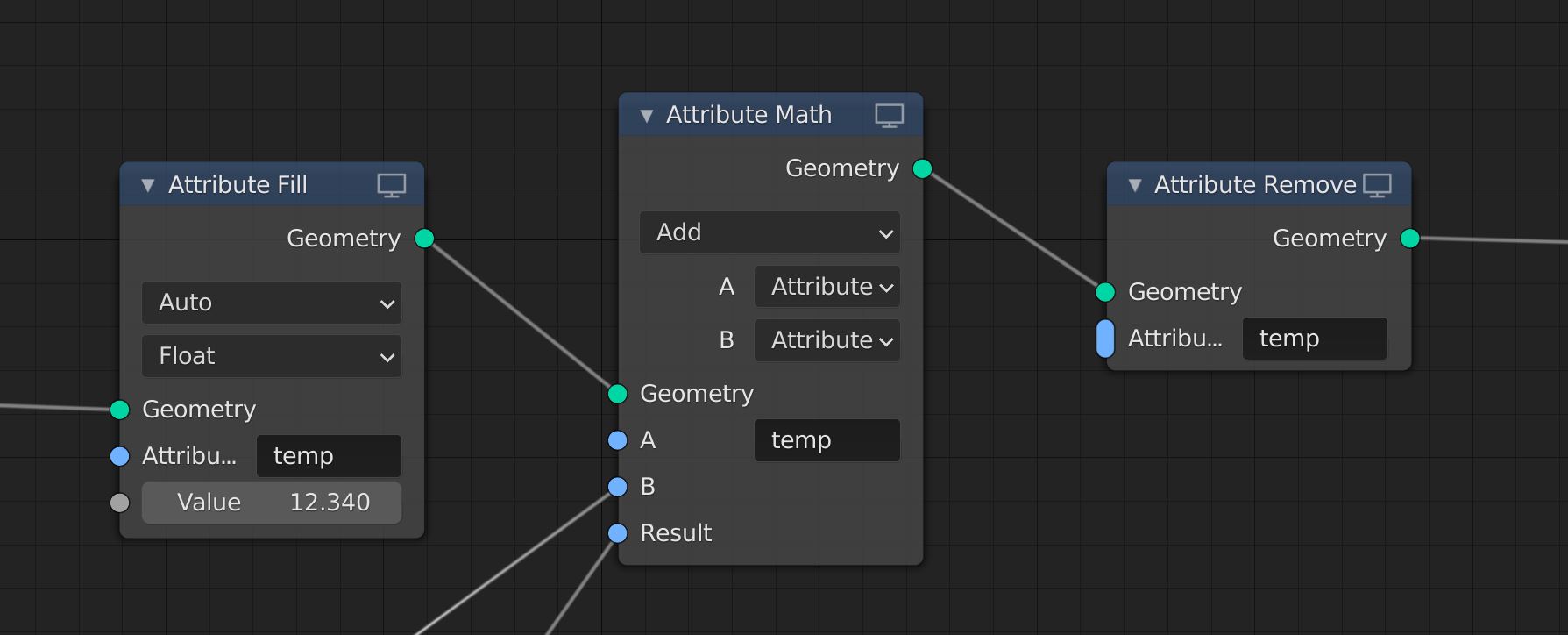
Use an unnamed output