Thanks everyone for the feedback.
- I agree that Individual Groups Inputs are almost a separate topic. But I wanted to bring them in to show the workflow of drag & dropping attributes (e.g., vertex groups) in the node editor.
- Also agree that the advanced options in the Node Group are also a separate topic. But I wanted to have them here to address the scenarios where the node group is used inside a node tree.
- @Erindale I will work on some examples. This is also something @jacqueslucke asked me about.
- Attribute Input node: It should be possible to replace the attribute input node with the Get Attribute node and no geometry input. However I also think it is important to have a clear distinction between the input nodes and every other node. Specially if they can be spread throughout the nodetree. So I think it may be worth to having it around. Besides, if we will have one input node for any other input, we may as well have one for attributes.
- Unifying the Get/Set Nodes:
I sketched this out and I think it can work. The name of the corresponding categories/namespaces are still in the air. But the overall behaviour would be:
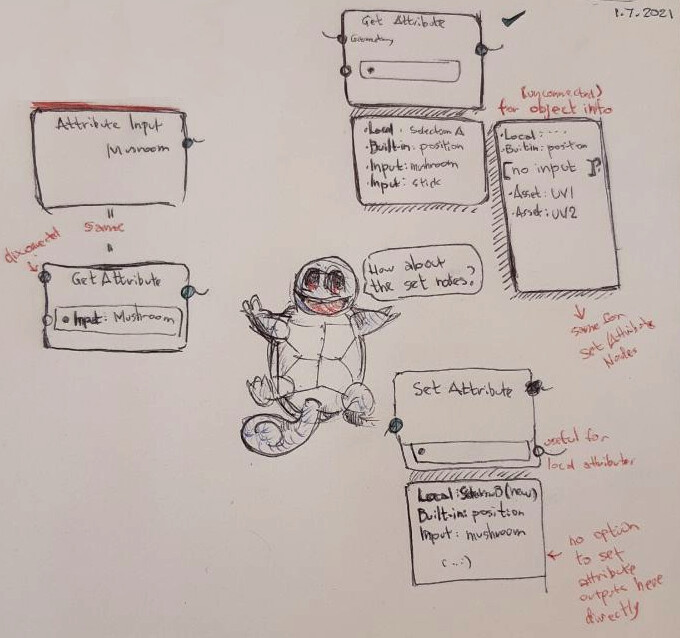
In the image you can see under the nodes the options you get in the attribute search input.
Also, as you can see, when the object/collection info has the object defined inside the nodetree, the Asset namespace will also be exposed in the geometry.