This proposal is inspired by multiple proposals that have come before:
- Proposal for attribute socket types.
- Fields and Anonymous Attributes.
- Expandable Geometry Socket.
- Attribute Processor.
Quick note, all the images are just mockups. They have been created using node groups, the Toggle Node Options operator in the context menu of nodes and a little patch that makes it easy to change the display shape of sockets in the sidebar (patch).
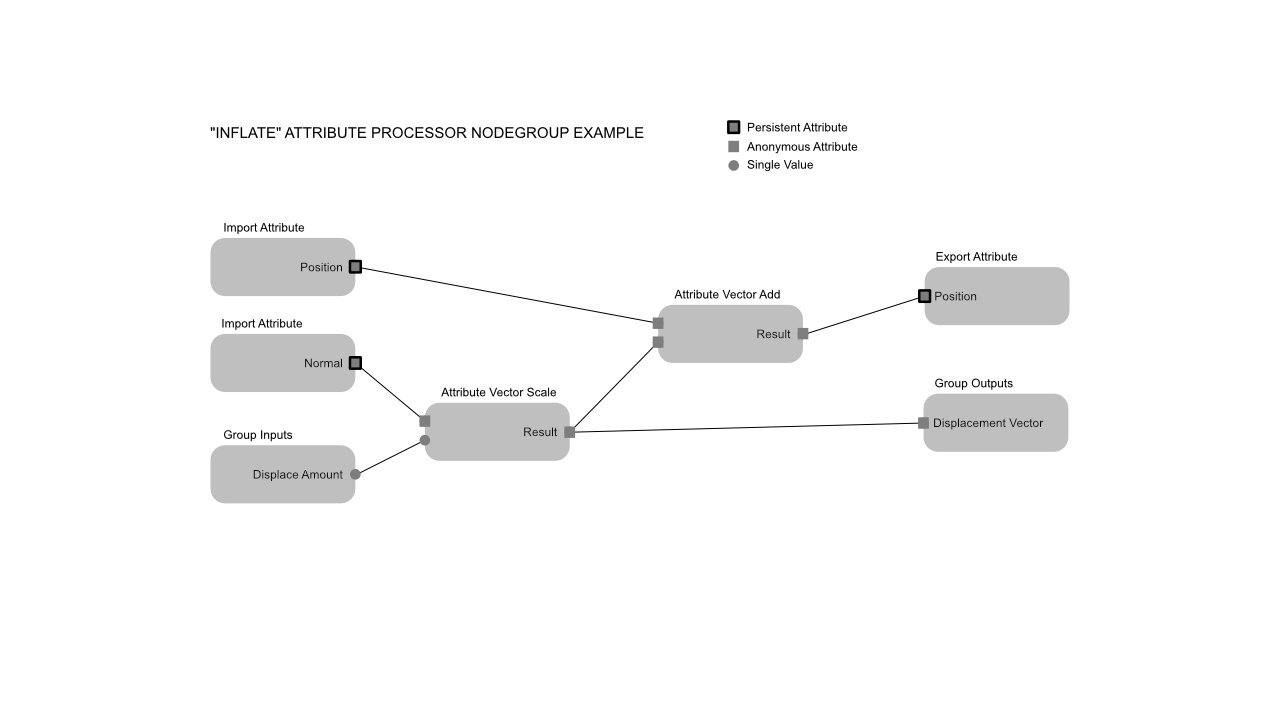
Anonymous Attribute
Definition
To recap, currently a geometry attribute is a container for data that is attached to geometry.
- It belongs to a specific domain of the geometry (such as vertices, edges, faces, …).
- It has a specific data type (such as float, integer, …).
- It has a name that identifies the attribute on a geometry.
Anonymous attributes extend this concept a little bit. Now attributes fall into two categories:
- Persistent Attributes: Those are the same as the attributes we have already.
- Anonymous Attributes: Those differ from persistent attributes in the following ways:
- They are not identified by name. Instead they are identified by some yet-to-be-defined thing that the user should never see (might be a random name, or some runtime data structure).
- Their identifier is reference counted. Once the reference count drops to zero, the anonymous attribute can be removed automatically. The geometry itself only has a weak (non-owning) reference of the identifier.
- They might have a debug-name, which is not an identifier. This name might be shown to users, e.g. in the spreadsheet or in socket inspection.
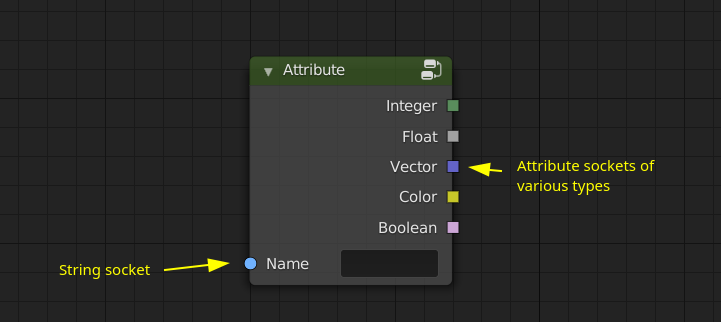
Attribute Socket
Definition
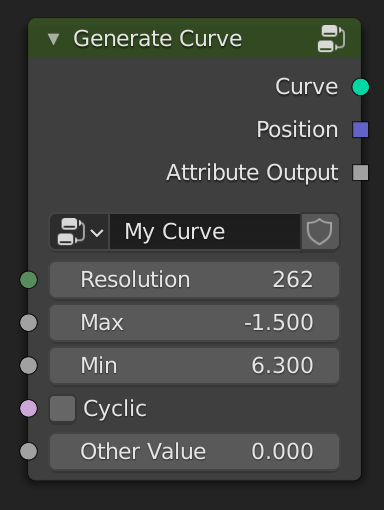
- An attribute socket is a new kind of socket. For the purpose of this proposal, they will have a square socket.
- There is an attribute socket type for every attribute data type (e.g. Float Attribute socket, Vector Attribute socket, …).
- The data flowing through an attribute socket is one of those:
- A single value of the base data type.
- A name of a persistent attribute.
- A strong (owning) reference of the identifier of an anonymous attribute.
Usage
The Attribute node can be used to get a new reference to a persistent attribute. In theory we could also have an implicit conversion from strings to attribute sockets, but I’m not sure if that is desirable.
Anonymous attribute references cannot be created from a string. Instead, they are created by nodes that add new attributes.
It is not possible to use math nodes directly on the attribute sockets.
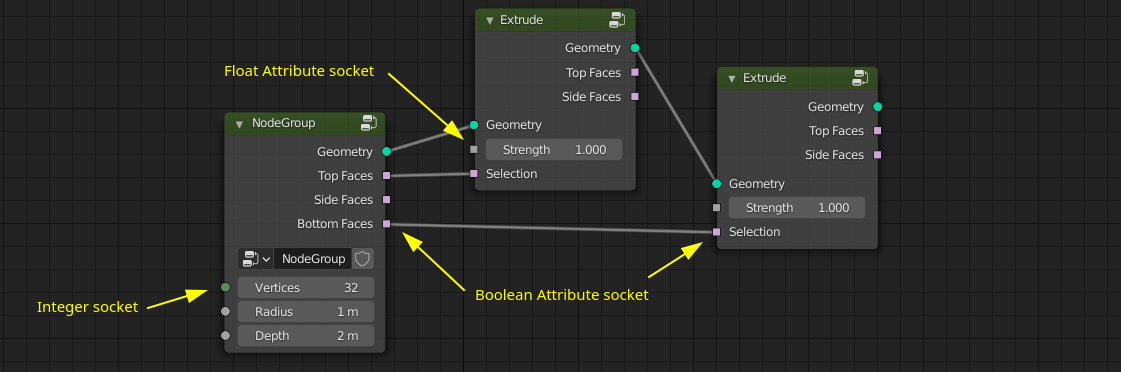
Since attribute sockets contain references to attributes, they can be used after topology changes.
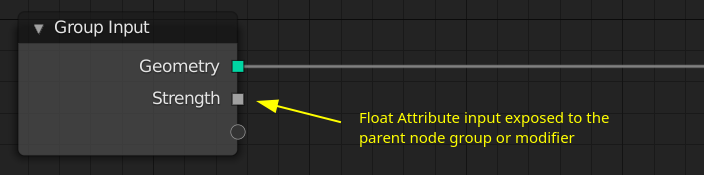
Attribute sockets can be exposed to the modifier as input or output.
- Input: In the modifier the user can choose between providing a constant value or an attribute name (with attribute search).
- Output: In the modifier the user can give a persistent name to the attribute. If the name is left empty, the attribute is discarded.

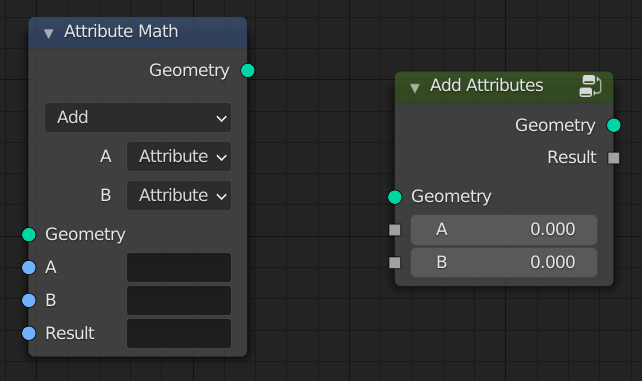
The existing attribute math nodes would still be valid nodes in the sense that they would not have to be updated. They would just only work on persistent attributes. It is possible to update them to make use of attribute sockets though. However, in practice operations on attributes should be done with the attribute processor. This is explained in more detail in the next section.
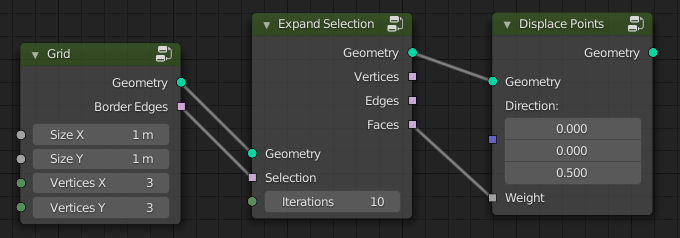
An Expand Selection node could output selections for different domains that can be used by subsequent nodes. Attribute sockets can be converted between types implicitly. The actual conversion of the referenced attribute will happen in the node using the attribute.
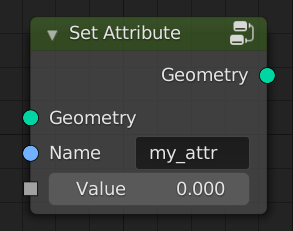
It is possible to create persistent attributes using a Set Attribute node. It’s not in the mockup, but the node would have a data type and maybe domain dropdown menu.
Creating persistent attributes with nodes can be useful when preparing geometry for rendering or export. One could build node groups that encapsulate hardcoded names that match the names used by the material or other software. Material assets could come with a (possibly automatically generated) geometry node group that makes setting up the right attributes easy.

The same concept can also be applied to getting data into geometry nodes.
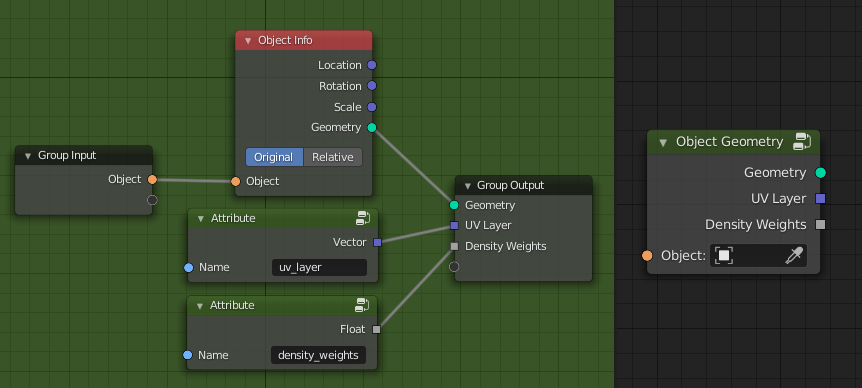
For example, a node group like this one could be build for an object (possibly automatically).
This way, the hardcoded attribute names are abstracted away from the main node group.
What works for the Object Info node here, also works for loading geometry from files.
Node Group Processors
Definition
A Node Group Processor is any node that references another node group and invokes/calls/executes it in some way.
Group Node
The Group node exists for a long time already. When it executes the referenced node group it works as if it was copy-pasted into the parent node group. The behavior will not change with this proposal.
Attribute Processor
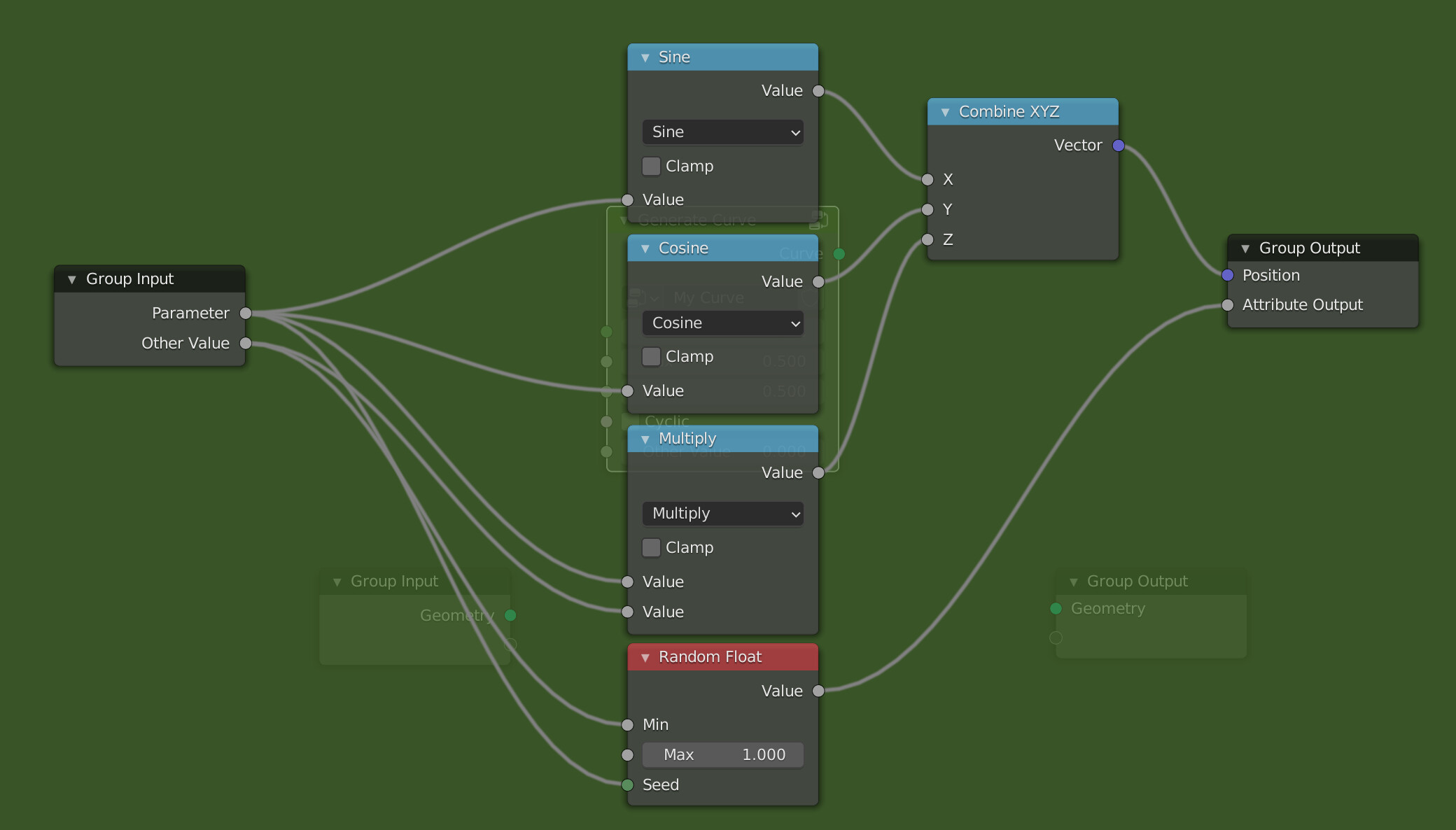
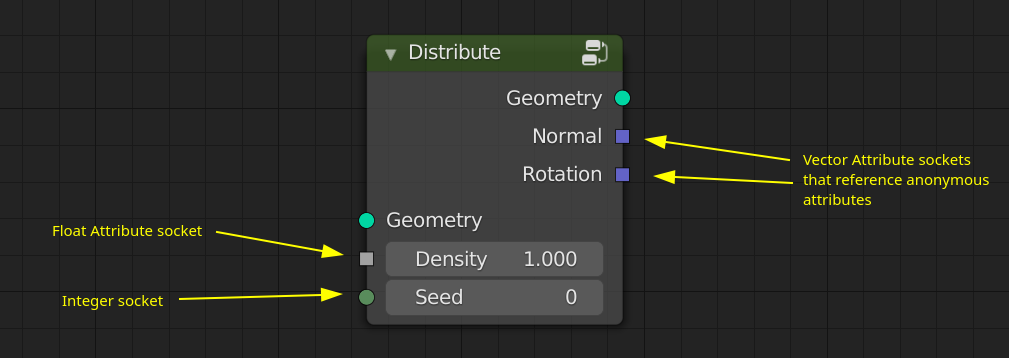
The Attribute Processor is a new kind of node group processor. Instead of executing the referenced node group only once, it executes it for every element on some geometry domain. The inputs and outputs are exposed as attribute sockets. Inside the referenced node group, it is possible to use some “special” nodes that only make sense in the context of the attribute processor. E.g. one can access the index of the current iteration. Furthermore, builtin attributes like position can be used directly without having to expose them to the outside (although that is possible as well of course).
It’s not shown in the mockup, but the attribute processor node needs a domain dropdown. In this current design, it does not need a selection input because it does not change existing attributes. Providing a selection nevertheless could be useful to improve performance. Maybe it is also possible to somehow detect the selection automatically by looking at what the output is used for. Not sure if that can work well.
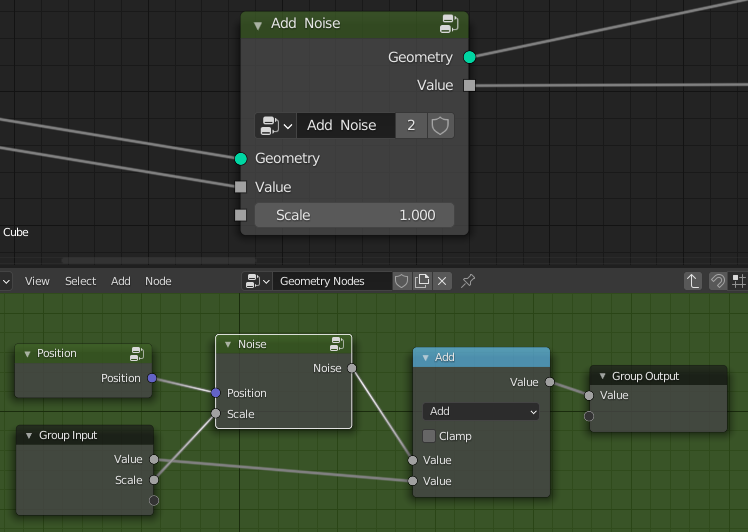
Inside the attribute processor, normal math nodes can be used to perform math operations on attributes in a non-linear way. In the current design, the node group referenced by the attribute processor would just be another geometry node group, just that some nodes might be disabled and others become available.
Others
I won’t go into much detail here, but at least wanted to mention a few other possible node group processors.
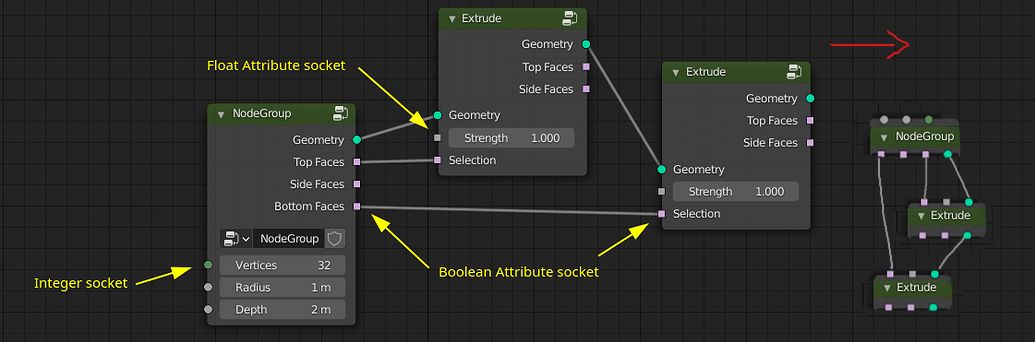
- Submesh Processor: The referenced node group would have a geometry input and output and is executed for every connected component in a mesh separately.
- Spline Processor: Similar as above, but it will be executed for every spline. The output can be a spline but also something else that replaces the spline.
- Curve Generator: References a node group that turns a float into vector that can be used to generate a spline.
- Volume Generator: Has a position as input and outputs volume grid values for the position. On the outside one would have to specify a bounding box and resolution.
- Recursive Geometry: Executes the same node group multiple times on the same geometry.
Comparison
All statements in this section are from the perspective of this proposal.
Original Attribute Socket Types
- The concept of the Attribute Socket is essentially the same, just that this proposal fills in some more details and integrates it into a larger context.
Original Attribute Processor
- Inputs and outputs inside the attribute processor group correspond to inputs and outputs in the attribute processor node respectively.
- Less need for various drop downs to configure the attribute processor.
- The attribute processor does not overwrite existing attributes.
Fields and Anonymous Attributes
- Cannot use math nodes on attributes directly in the main node tree.
- No callbacks in the main node tree, there is only one “execution context”.
- Attribute Sockets correspond to specific attributes (whereas fields do not), so nodes using attribute sockets as input can lookup the domain of the attribute. This is especially useful for selections.
- It’s more clear what node inputs may be attributes just by looking at socket types.
- One has to work with more node trees to achieve the same effect. With fields, everything could be done in a single node tree and is more plug-and-play.
- Knowledge gained in shader nodes does not apply here directly, e.g. one could not just use a standalone noise node to control some displacement. The concepts do apply to some degree within the attribute processor though.
Expandable Geometry Socket
- Hardcoded attributes names can still be used inside the node tree when appropriate.
- The modifier ui can look the same. It’s very explicit when inputs and outputs of the geometry node group are attributes, and the modifier ui can be drawn accordingly.
- It’s not necessary to flatten all data into lists to benefit from non-linear math nodes. Flattening data into lists is easy when there is a single mesh, but much less so when there are e.g. curves or instances. Also, I’m not sure how one would flatten a (sparse) volume grid into a list in a good way. It also has to be possible to un-flatten the list when it is used.
- Attribute sockets can be linked across topology changes on the geomery.
- Anonymous attributes that are not referenced anymore can be used automatically (so a “pop” operation is not necessary).
- It’s not necessary to give anonymous attributes meaningful names, because they can just be connected to where they are used, even when there are topology changes.
- There is no need for domain dropdowns in attribute outputs, because domain interpolation happens at the node using the attribute.
Compatibility
It is not required to change any existing nodes. They are all still compatible with this proposal.
We might want to change some nodes to improve the workflow, but versioning should be relatively straight forward. That makes it easy to gradually transition from the current workflow to the new workflow.
Possible Future Extensions
Lists
New list data types don’t conflict with this proposal and extend it well. It might make sense to add attribute lists as well. Those could be used in some nodes to determine which attributes should be transferred and which should not. Generally, all attributes are transferred everywhere, but that can be very expensive at times, so providing some more control might be useful.
Reference Sockets
Maybe referencing attributes is just a special case of some more generic concept: referencing data that is stored somewhere else. I don’t have anything in particular in mind currently.
Passing Callbacks
One major limitation of this proposal currently is that one cannot pass e.g. a procedural texture (generated with nodes) around. It is always used in the same place where it is defined. This can be restrictive in some use cases.
A possible solution is to pass around geometry node groups as callbacks. Obviously, there are some issues to overcome. Mainly, what happens if different node groups have different sets of inputs and outputs. I think that can be overcome be attaching some meaning to group inputs and outputs that is understood by the nodes executing them. This is similar to what was done in the fields proposal implicitly.
While it is more cumbersome to work with callbacks in this way compared to working with fields, it is much more explicit and opt-in.