Anonymous attributes are an important part of geometry nodes since their introduction together with fields.
They allow working with geometry attributes without having to worry about name conflicts. Contrary to named attributes, they are automatically removed when they are not necessary anymore. Attributes that stick around for longer than necessary always come with a cost. Often they are also only computed when they are actually needed. They also allow outputting attributes generated by nodes naturally as sockets.
Unfortunately, there are still a few things that can’t be done with anonymous attributes currently. This document presents these limitations and discusses potential solutions.
Current Limitations
The limitations that I’m currently aware of roughly fall into two categories: joining and propagation settings.
Joining
The first limitation becomes apparent when trying to join geometries. Since anonymous attributes on different geometries are generally independent, the resulting geometry contains each anonymous attribute separately. They can only be combined using a “hack” like simply adding them together. This works because the default value for attributes is generally zero.
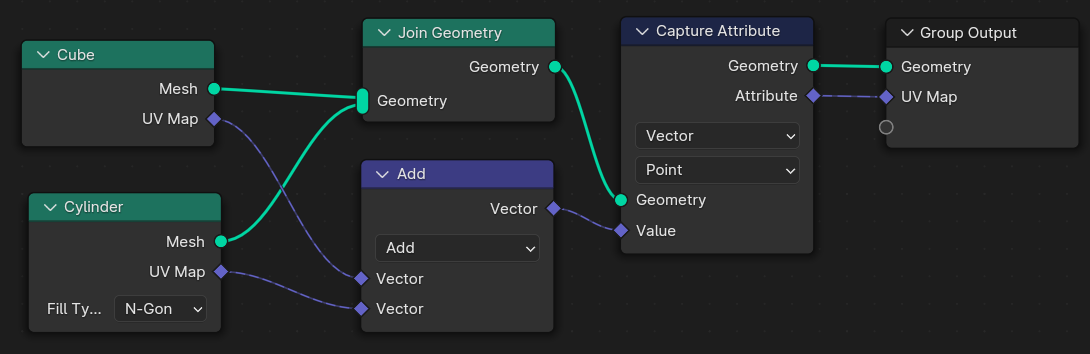
The issue here is that a workaround is required to join the attributes and that this is cumbersome and less efficient. Of course one could use named attributes but then one would loose the benefits of anonymous attributes mentioned above (e.g. that the UV map is only generated when it’s actually used).
The existing workaround becomes even more problematic, when the geometries that are joined contain instances, and the anonymous attributes don’t exist on all sub-geometries. In this case, the Capture Attribute node will generate attributes even on unrelated sub-geometries.
The problem of joining anonymous attributes becomes even more important with the upcoming for-each zone, because there it’s not possible to use the same workaround. And even if it were possible, it would be significantly less efficient due to the potentially large number of geometries to be joined (e.g. one per iteration).
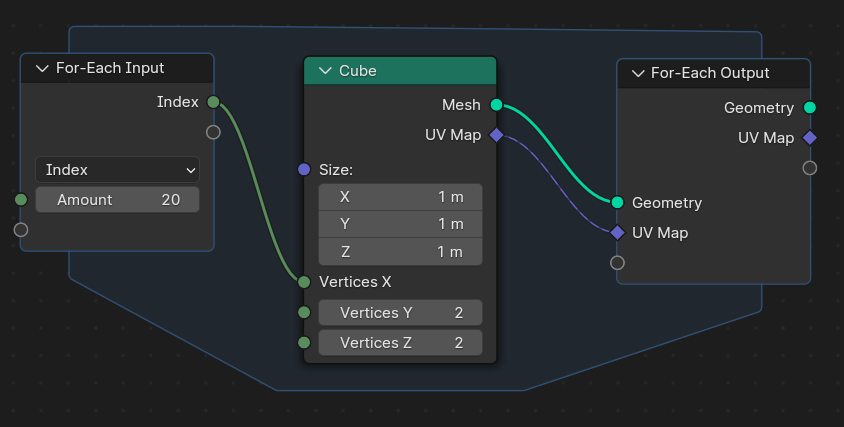
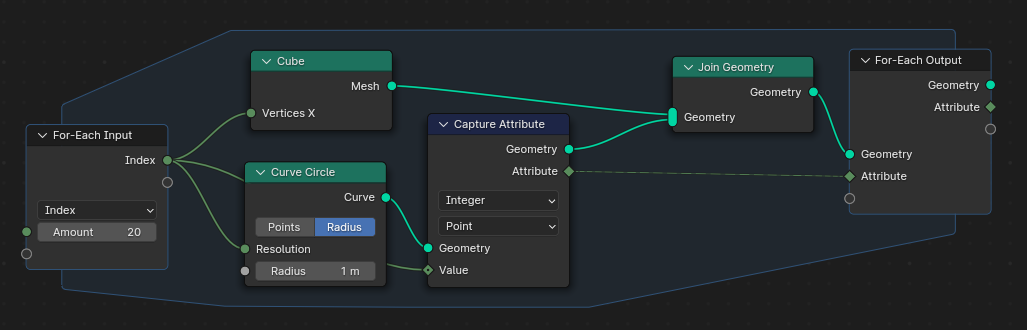
In the current design, the solution would be to evaluate the UV Map field in the For-Each Output node to create a new attribute there. This generally works fine, but has the same problems as the workaround above when the geometry contains multiple sub-geometries. That’s because then the UV Map attribute is created for all sub-geometries and not only for the ones that should have it. The same problem exists in simulation zones as well already.
Propagation Settings
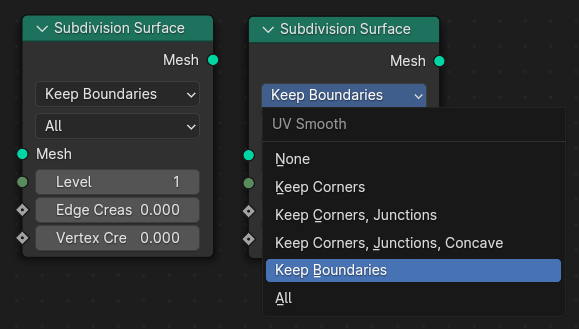
This second limitation is less prominent so far, because we don’t have nodes that allow the user to customize how attributes are propagated yet. It’s only a matter of time until we have those though, because it’s an important thing to control sometimes. For example, the Subdivision Surface node could support different ways to propagate UV maps on a per attribute basis. Currently, there is just one setting that applies to all attributes.
Use-cases for specifying this on a per attribute basis came up when we worked on hair, which use uv coordinates to specify attachment points. UV maps that use used for surface attachment should generally be propagated differently than ones which are only used for texturing.
For named attributes, a potential solution is somewhat obvious: the node could just have string inputs that specify which attributes use which propagation method. This could use some pattern matching language.
For anonymous attributes, we could have a variable number of field inputs and outputs for each kind of propagation mode. That could generally work, but also has the problem that this might generate attributes on sub-geometries that don’t have the original attribute.
Potential Solutions
Below I describe two similar but different solutions. The first solution introduces a new socket type to make the behavior more obvious. The second changes that so that no new socket type is necessary.
Attribute Reference Socket
The idea here is to introduce a different kind of socket that is just an attribute reference. This is more constrained than a field socket, because a field can reference and combine many attribute references. It’s also similar to the attribute socket in an earlier proposal, but not the same. The main difference to the socket from that proposal is that here the socket can not contain a single value of the data type, just the attribute reference.
With this, Join Geometry could just have a variable number of multi-inputs. The given attribute names are then combined into a single attribute in the output. There is no field evaluation involved since we work directly on the attributes. The new attribute is only created on the sub-geometries that also had an attribute originally. Fields would generally be evaluated on all sub-geometries.
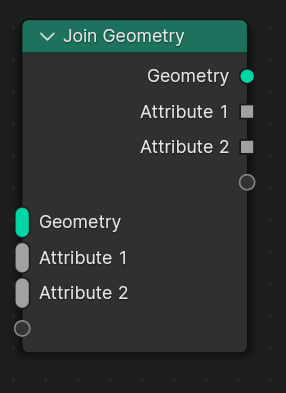
Nodes that create new anonymous attributes also output the new socket type. The new socket type implicitly converts to a field. The new socket shape mainly indicates that this references a single specific attribute. Passing this to a Store Named Attribute directly, would create the named attribute only on the parts of the geometry that had the anonymous attributes.
Field Attribute References
The idea here is to extend the definition of a field socket in geometry nodes to also capture the idea explicit attribute references. For context, currently a field is defined to be a function that outputs a value of the corresponding data type based on a context (the corresponding data type is e.g. float or integer). This also means that the only thing that can be done with fields is to compose and evaluate them.
The definition currently does not allow extracting extra information from a field (on a user level). We currently only allow that to simplify debugging with the viewer node which automatically derives the “preferred domain” from a field. That is ok because the output of the viewer node is not used for other procedural operations.
The definition of a field could be extended like so: A field is a function that outputs a value of the corresponding data type based on a context. Optionally, it can be a reference to exactly one attribute.
Most nodes stay exactly the same with this updated definition. However, the behavior of some nodes could change given the additional knowledge about a field. For example, the Store Named Attribute node could (maybe optionally) only create the named attribute for sub-geometries that have the attribute referenced by the field. The For-Each Zone Output node could just rename all anonymous attributes to have the same name instead of using field evaluation.
The main question that remains here is if any other visualization is necessary to communicate the difference between attribute references and normal fields to the user, or if socket inspection and warnings in nodes are good enough. For example, there could be a warning if a field input expects an attribute reference, but an arbitrary field is passed in.