Present: Brecht Van Lommel, Dalai Felinto, Jacques Lucke, Ton Roosendaal.
Workshop in Amsterdam from August 31 to September 11.
Dynamics Modifier
A modifier to handle more complex interaction. The logic is built with a node graph, owned by the modifier.
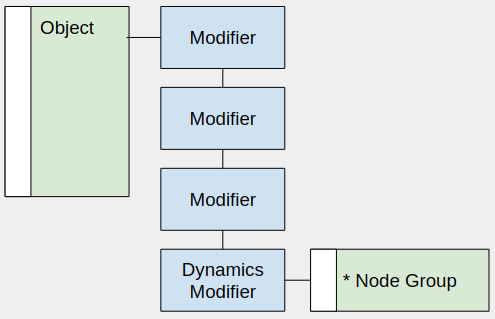
Dynamics Modifier inputs and outputs
The modifier input and output are explicit nodes that represent the flow of geometry in the modifier.

High level abstraction
Users should be able to use the system in a high level. Hand picked parameters are then exposed in the nodes.

The the building blocks of the system are kept inside the main node groups, abstracted away but for advanced usage. Properties connected to the Modifier Input can be exposed in the modifier stack.
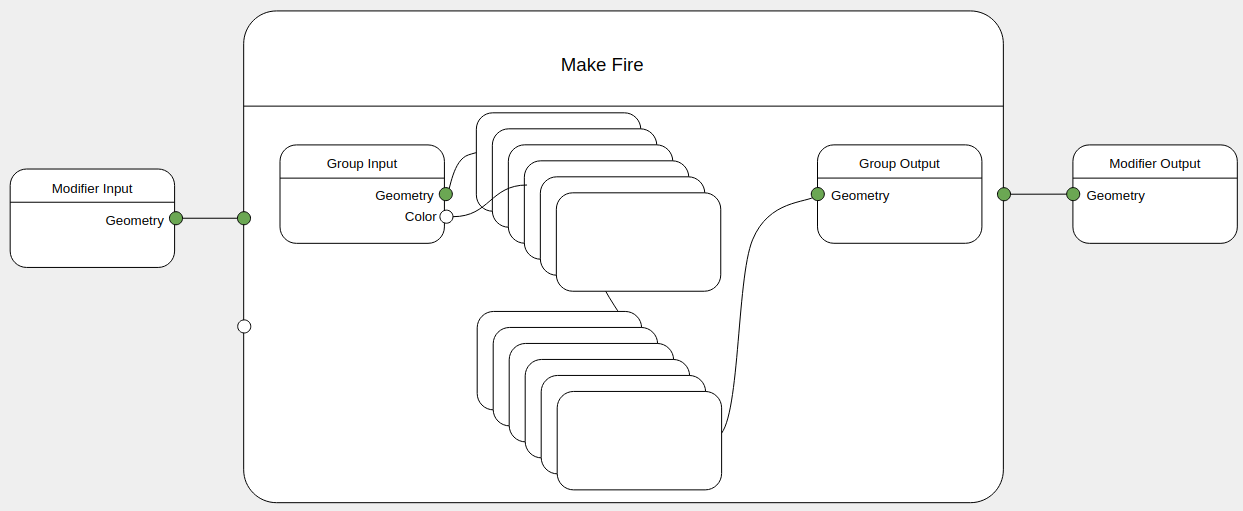
Data flow
The high level nodes operate in a clear dataflow of geometry. For events there is a need for a different representation for its callbacks. A few examples of design possibilities can be found in the UI Workshop notes.
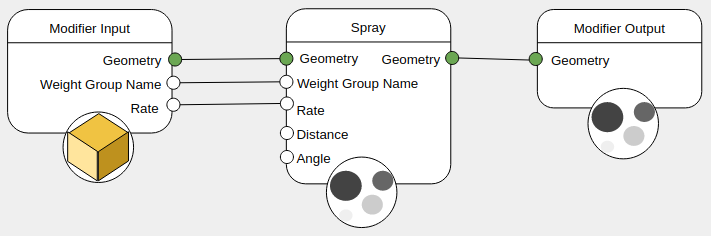
Geometry
Often, the simulation effects require a different input and output geometry types. For example, a spray gets the nozzle as input, and output foam particles.
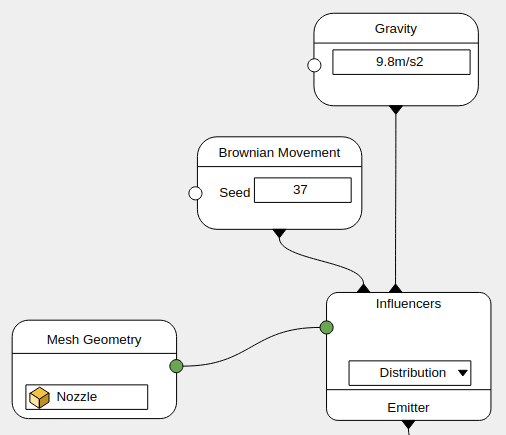
Solver Node
The solver node requires new kind of input, the influences.
The geometry is passed to the solver as the initial points (for the particles solver). The solver reaches out to its influences that can:
- Create or delete geometry
- Update settings (e.g., color)
- Execute operations on events such as on collision, on birth, on death.
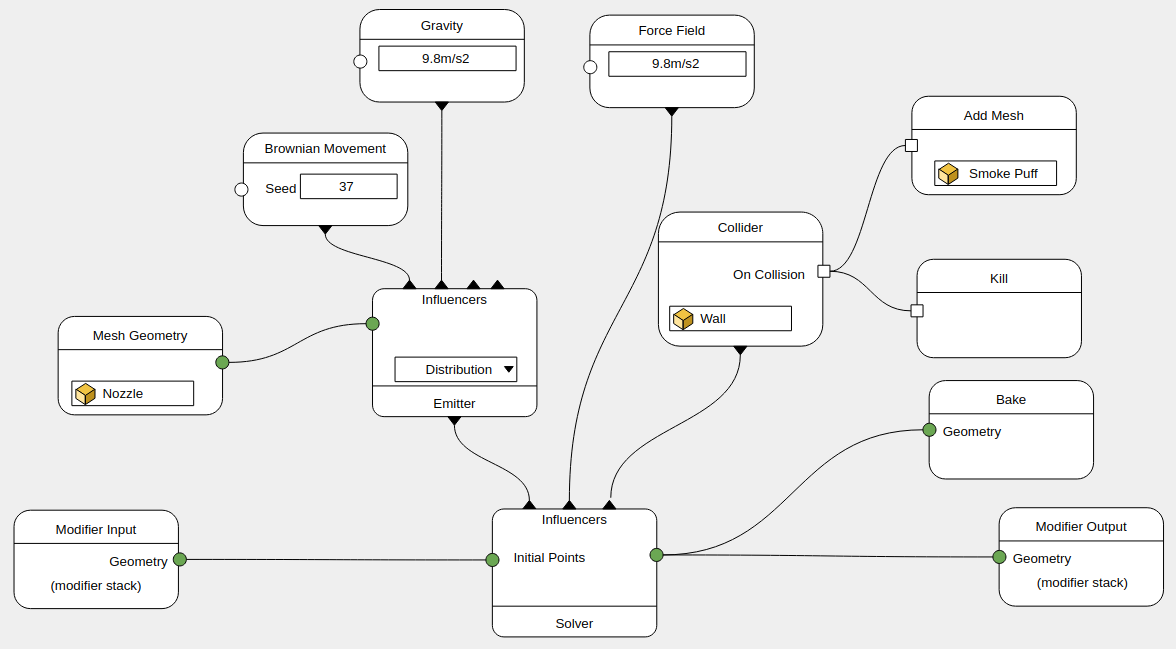

In this example the callbacks are represented as vertical lines, while the geometry dataflow is horizontal.
Emitter Node
The emitter node generates geometry in the simulation. It can receive its own set of influences that will operate locally. For instance, an artist can setup gravity to only affect a sub-set of particles.
Examples
Sintel
- Campfire with sparkles and some smoke
- Walking footsteps in snow
- Walking Dust puffs on steps
- Shaman cloth
- Sintel hairsim
Cosmos Laundromat
- Swirl effect in washing machine
- Sheep fur sim (also flock)
- Tornado setups (advanced)
Spring
- Breath vapour
- Smoke sims for alpha monsters (advanced)
Random ideas
- Animated creature duplication paths over animated body
- Melting (animated) objects
- Moss on trees
- Bark on trees (or is that shader?)
- Basic water sims (fountain, drop brick in water)
- Hair spray
Also
- Hair and fur systems
Next Steps
Define the subset of nodes required for the basic examples. Starting with the effects that can be done with particles, with a particular emphasis on object scattering for set dressing.
Start the UI changes to handle the different types of dataflow.
Implement the nodes required for each supported case, and re-iterate from there.
