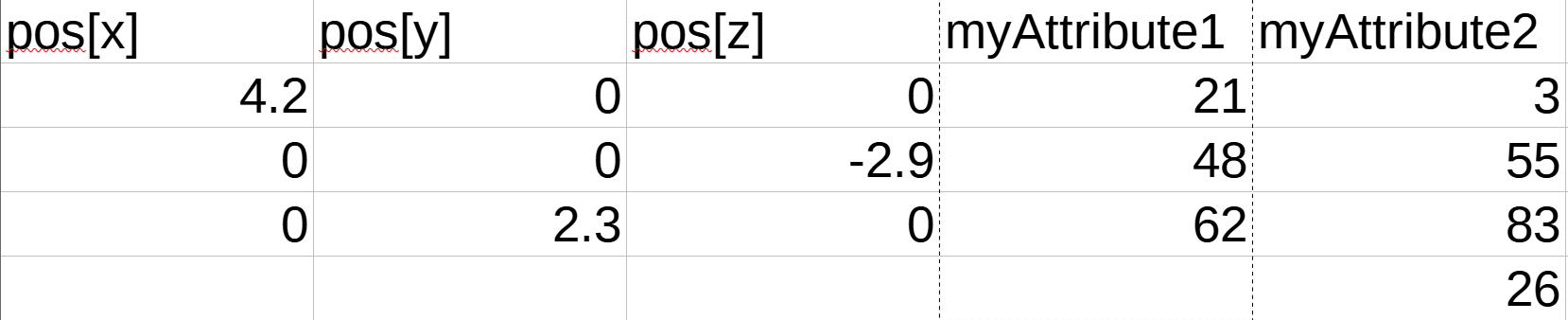Okay, It’s not that low level nodes can’t exist. And low level nodes already exist in geometry nodes, those are the attribute math nodes. It’s that attributes cannot be separated from geometry cleanly, thus certain constraints are enforced by design. I shall try to explain it:
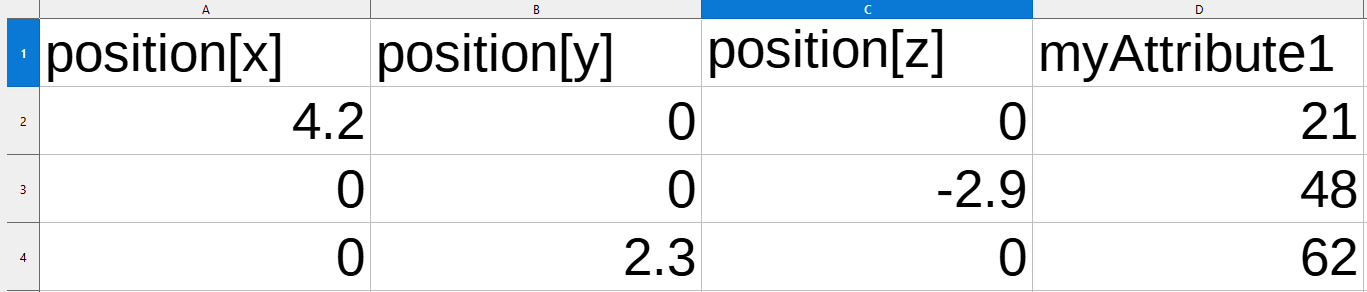
This is a spreadsheet that represents the incoming vertices in a geometry set (the socket called geometry)… It only contains a position attribute (vec3) and a custom integer attribute called “myAttribute1”. There are 3 vertices in this model. The constraints of the geometry set is that each column (container of attributes) there must not be any blank spaces, they are a continuous array of data attached to each point/face/etc. (THIS IS A VERY IMPORTANT CONSTRAINT WE WILL COME BACK TO LATER)
If we wanted to perform math on one of these then we would do this with an attribute math node, and we would tell the math node to perform this operation with the name of an attribute to search for as it’s input.
Let’s look at another socket’s contents…
Alright, it also has a position attribute but an “myAttribute2” attribute… But it has 4 points instead of 3, this has a different topology…
If we could seperate the attribute from the second container and add it into the contents of the first one:
That doesn’t make much sense, not only has the topology changed but the entire visual context of the geometry has changed as well with the position. We cannot default out the remaining blank space, that would be appending a new vertex along with the data… Such a splice would be unreasonable! If the topology of the geometry was identical such a copy would be possible but it rarely ever is and a data transfer should be smarter than that.
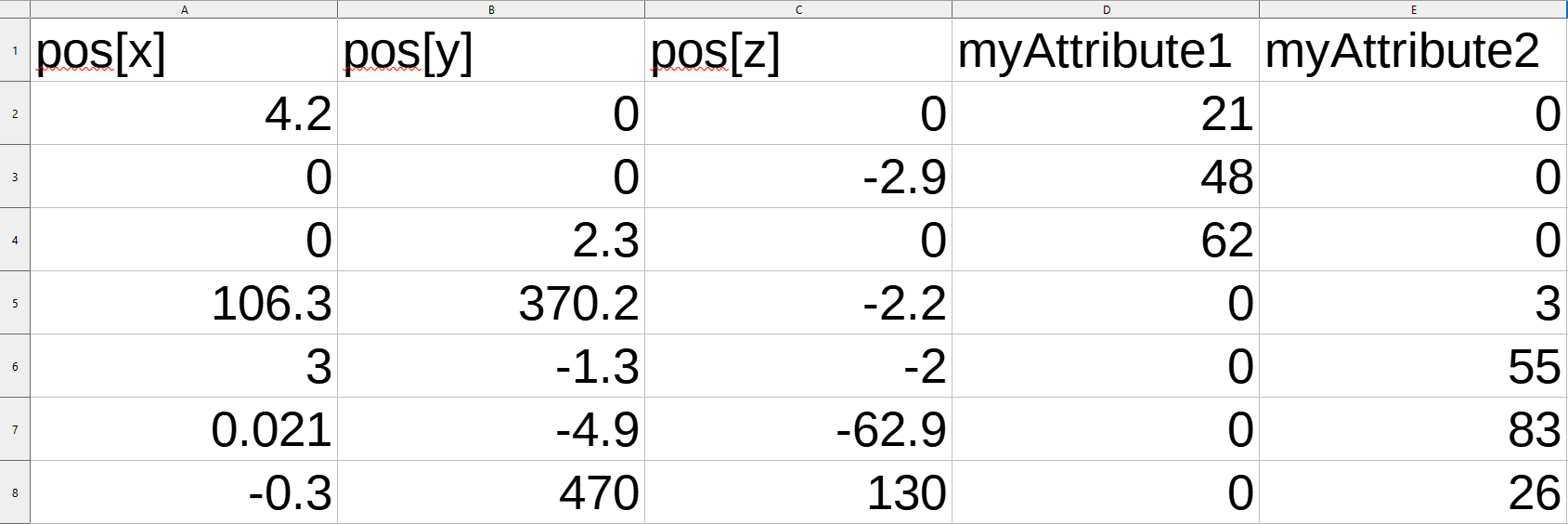
But wait, then how do we merge geometry (with a join node) without causing this issue? Well notice what happens:
We have created a new geometry set which combines the attributes from both, the interpretation of the data (what vertex attribute data is associated with) is preserved and defaulted out fields which were not occupied in order to satisfy the continuous data constraint. The resulting merge operation of vertices but not stray attributes therefore makes perfect sense and doesn’t result in a corrupted result.
Hopefully this explains why attributes are bucketed together to keep this constraint in-sync. It should not be up to the user to enforce these requirements or else risk broken geometry. And once the spreadsheet viewer becomes a thing, working with attributes will likely become second nature.