As part of my internship at Unity I was given the task to focus on a caching prototype for Geometry Nodes. The goal was to create a prototype and share it with you all to help kickstart the conversation around the various design decisions that will be needed for a proper proposal to be made. While working on this prototype I ran into various edge cases that I will walk through in this post.
This work is purely an experimental prototype and not a design proposal in itself.
A patch against master for this prototype can be found here.
Introduction
Caching within Geometry Nodes has been a much requested and talked about feature. Working with large and complex node graphs can get very slow when running in real time and caching would largely solve this issue by allowing computed data to be reused. The original design proposal for geometry nodes discussed implementing a cache node and there are multiple rightclickselect posts asking for the same thing (here and here). A more recent discussion under this devtalk thread built further on this idea by proposing two separate caching implementations - manual and automatic.
Manual Caching would involve the user controlling what nodes or sections of the node graph are cached.
Automatic Caching would involve the node tree evaluator storing the result of every node such that only the required nodes would be recomputed when something is changed.
This prototype implements a manual caching approach, however many of the ideas, implementation details and questions raised would likely also apply to an automatic caching system.
Demo

This is a demo video showcasing the caching prototype and example use cases. As you can see, nodes which process geometry can be marked for caching via an icon in the node header. Once marked, the outputs of the node will be cached the next time it executes. The cached output data will then be used every time this node is re-executed thereafter.
Caching is not available for math, attribute, field input nodes etc. This is because they either don’t process geometry and so are always extremely fast or they aren’t actually “executed” such as the field input nodes. Note that these nodes also don’t show timings when enabled in current Blender.
More Demo GIFs
NOTE: Many of the GIFs in this post need to be opened in a new tab to view properly.
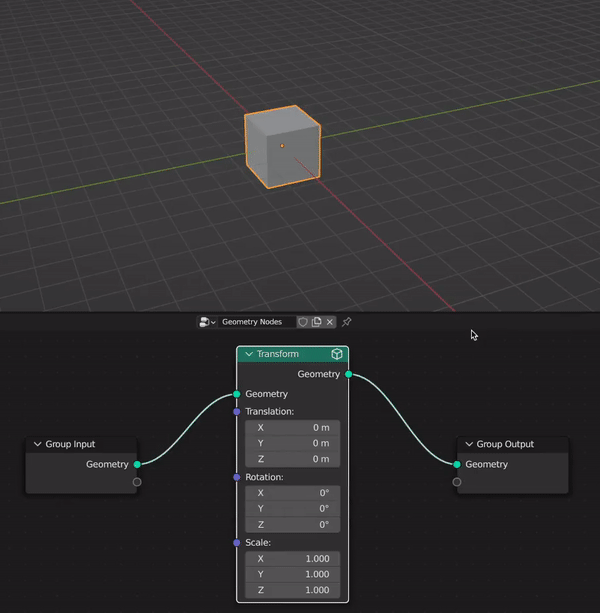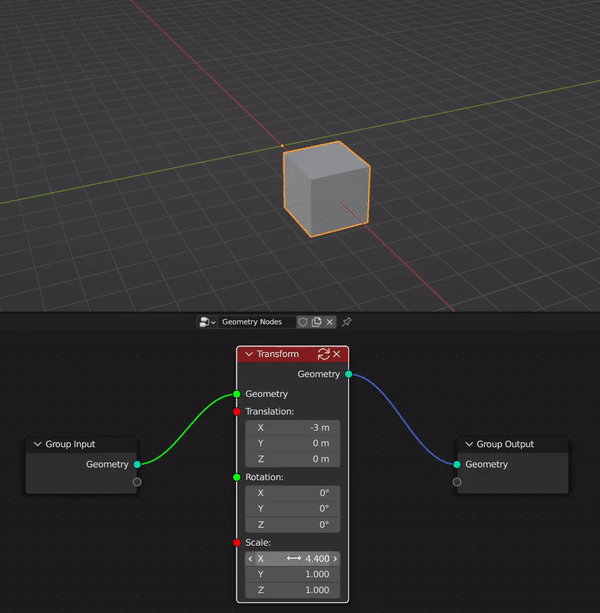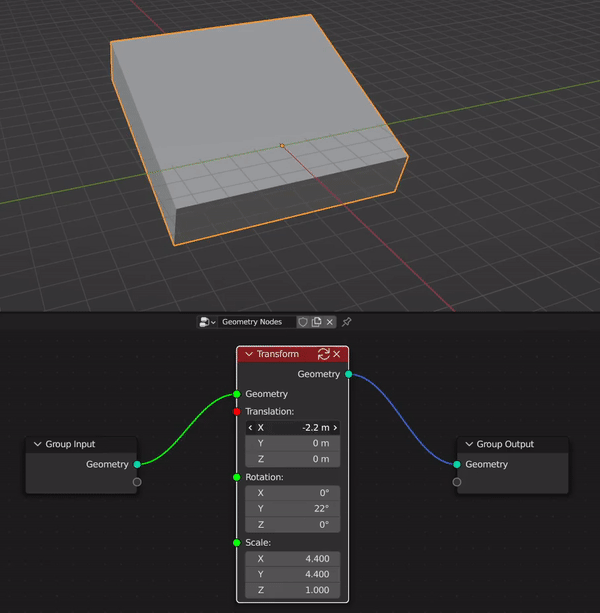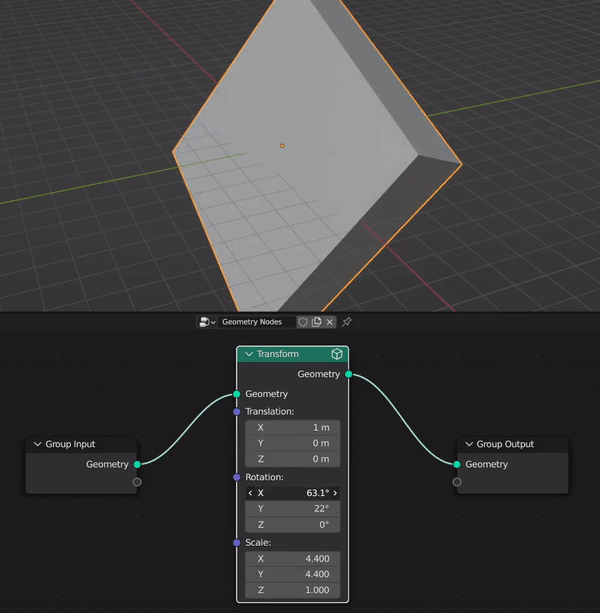
Benefits
In this prototype, a cached node usually takes between 0.1ms and 1.0ms. This is dependent on the size of the cached data and it scales linearly, therefore it can sometimes take even longer for large geometric data. Generally, a cached version of a node will always be faster for anything more than simple geometry.
This provides a massive speed up for slow nodes such as Boolean, Subdivision, etc.
As a result, boolean geometry can be manipulated in real time like so:
Nodes that are gated by a cache will not be executed when the tree is re-evaluated and also when those nodes are updated, such as by changing a socket value or link, it will not trigger a re-evaluation either.
This allows users to section off slow areas of their node graph using a cache to greatly improve performance when updating the graph and node parameters.
In this GIF you can see the nodes that create the bottle cap being gated by a cache from the rest of the node tree. This allows me to update them without causing the tree to re-evaluate. However, when I update the transform node, which is not behind the cache, the graph executes as it is updated, allowing us to see the changes in real time.
This benefit is only possible with manual caching. It ensures that no unnecessary updates occur that won’t change what the user sees in the viewport and allows them to easily make necessary changes without disconnecting links in the tree.
Also note how the bottle cap nodes blocked by the cache don’t execute when I update the transform, as it would be redundant. This benefit would also be seen with automatic caching.
Design
This section will discuss the various design decisions I made and why, as well as their flaws. I would be very interested to hear any feedback and/or ideas you may have around this.
Why not have a dedicated cache node?
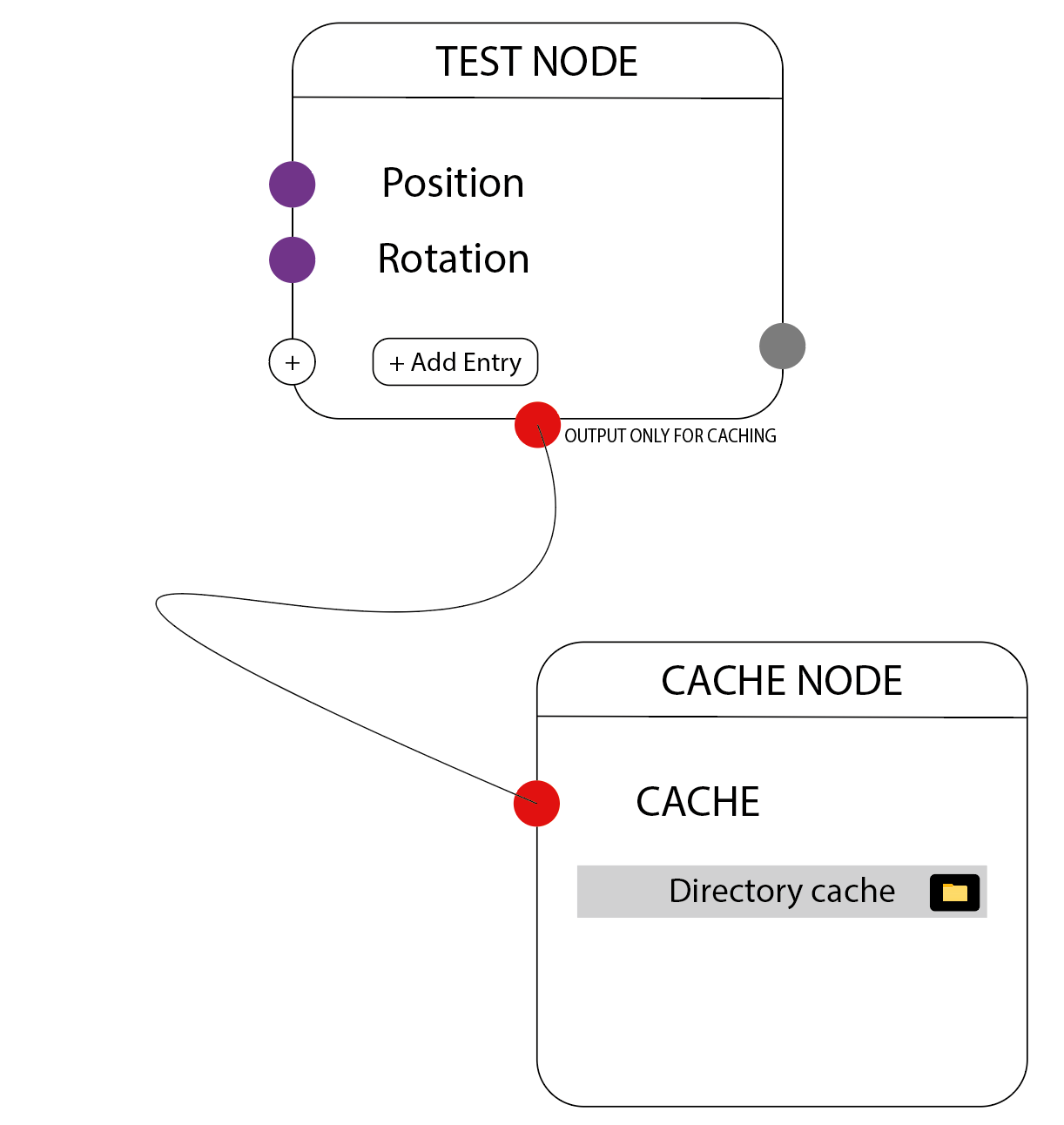
As mentioned above, previous ideas around caching discussed implementing a dedicated cache node. This prototype avoids the need for a dedicated cache node by giving every geometry node an implicit adjacent cache.
I implemented it this way after chatting with internal Unity artists who have significant experience in the VFX industry. They expressed that a dedicated cache node has been tried in the past in other tools and is a bad approach when working with large node graphs. It often results in users littering cache nodes throughout their graphs.
The main benefit of a dedicated cache node is that it could have a more detailed UI for more complex caching (such as a filepath for Alembic/USD). However, this could potentially be avoided if the generic node UI was extended.
Memory Cache
This prototype implements a “Memory Cache” in that it only ever stores the cached data in memory at runtime and never onto disk (either in the blend file or otherwise). This means that if a user saves their blend file with a cached node and then re-opens it, it will recompute the cache as the node graph is evaluated. The cache could be written to the blend file, but it arguably works fine either way in this prototype.
Another option is Alembic or USD caching, which would require specifying a file path and more parameters. These methods of caching also wouldn’t likely offer performance improvements, as they require writing to/reading from disk, and would be more useful for interoperability between applications. Different types of caching are discussed in this Blender Wiki article.
UI
By far the most important area to discuss with regards to a caching design would be the UI. This prototype’s UI breaks many of the geometry nodes UI conventions and is certainly not a good design. The reason for this is discussed here and in the next section.
Header Icons/Buttons
This prototype adds caching related icons to the header of each geometry node, similar to the nodegroup icon. When a node is not cached, a cube icon can be pressed to enable caching.

The cube icon is just a random one I chose as a placeholder. A specific cache icon would make sense to have.
Once cached, the cube becomes an X to disable caching and a refresh icon for recomputing the cache appears beside it.

This is the one area of the UI that I feel works well (aside from the icon choice), however other options could include placing the caching buttons/icons in the body of the node or on some kind of side panel.
Header Coloring
When cached, a node’s header changes color to green or red depending on whether the cache is clean or dirty.

This breaks the convention that node header color is used to indicate type. As discussed in the implementation issues section, I was limited by the current node UI code in this regard.
An alternative idea might be to do something more in line with muted nodes by indicating the node as “frozen” or “cached” using a colored outline and applying a tint/alpha to the node body.
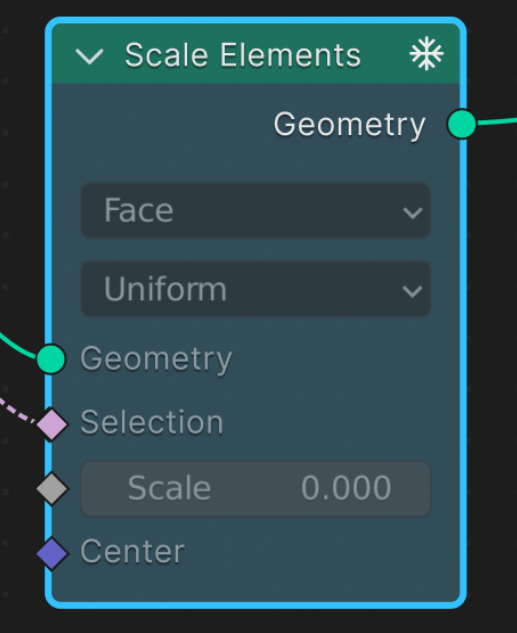
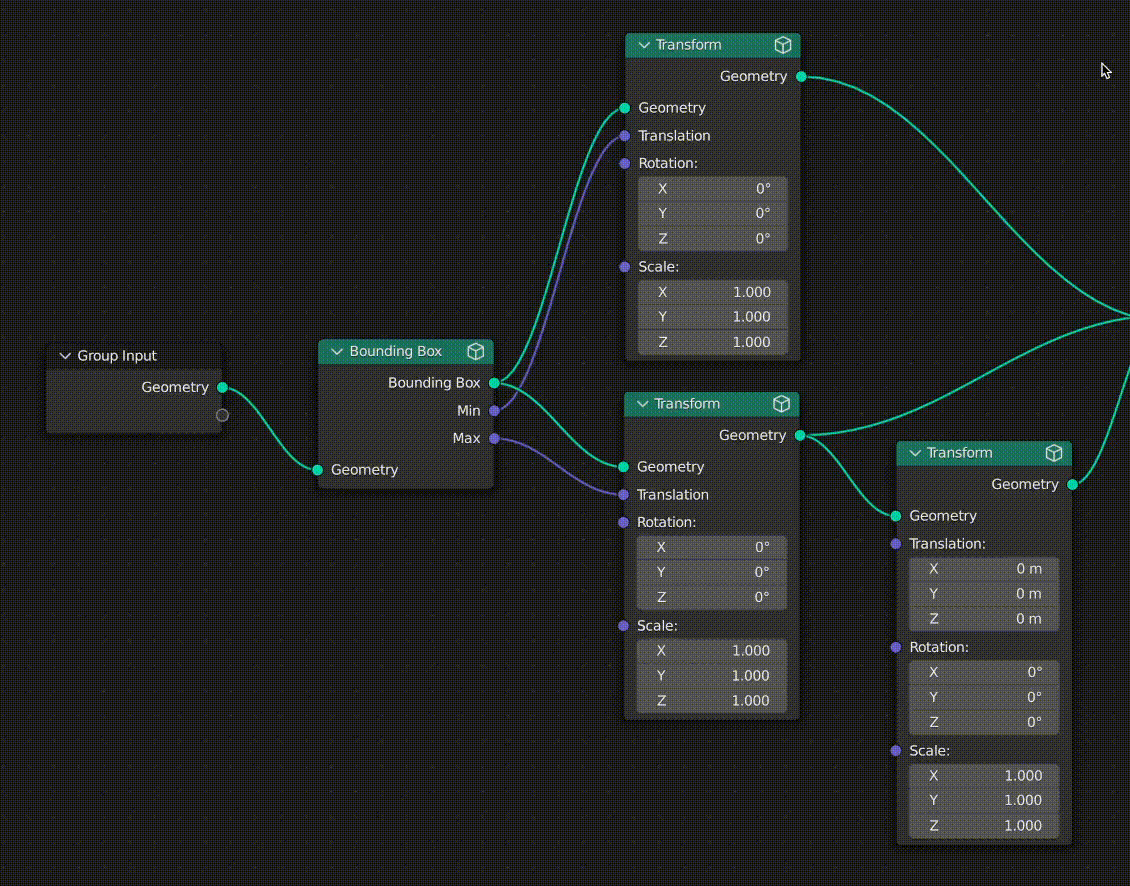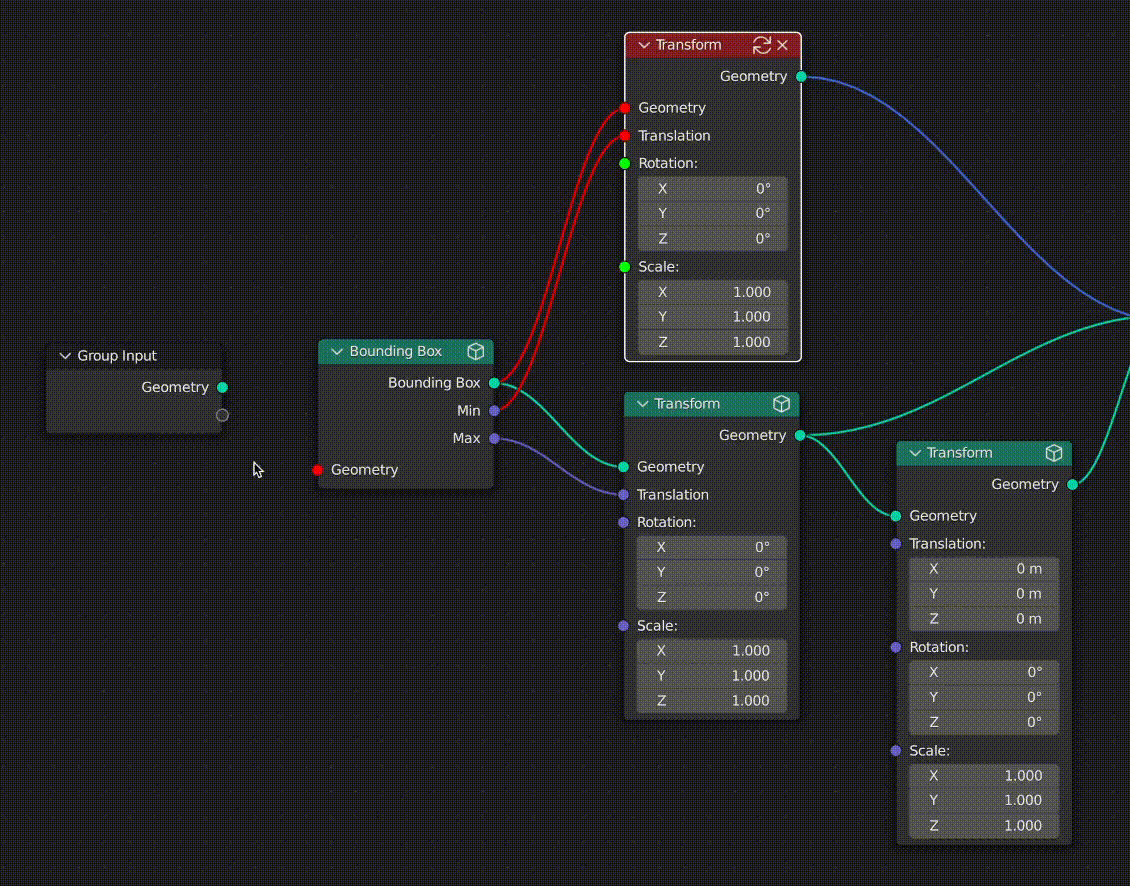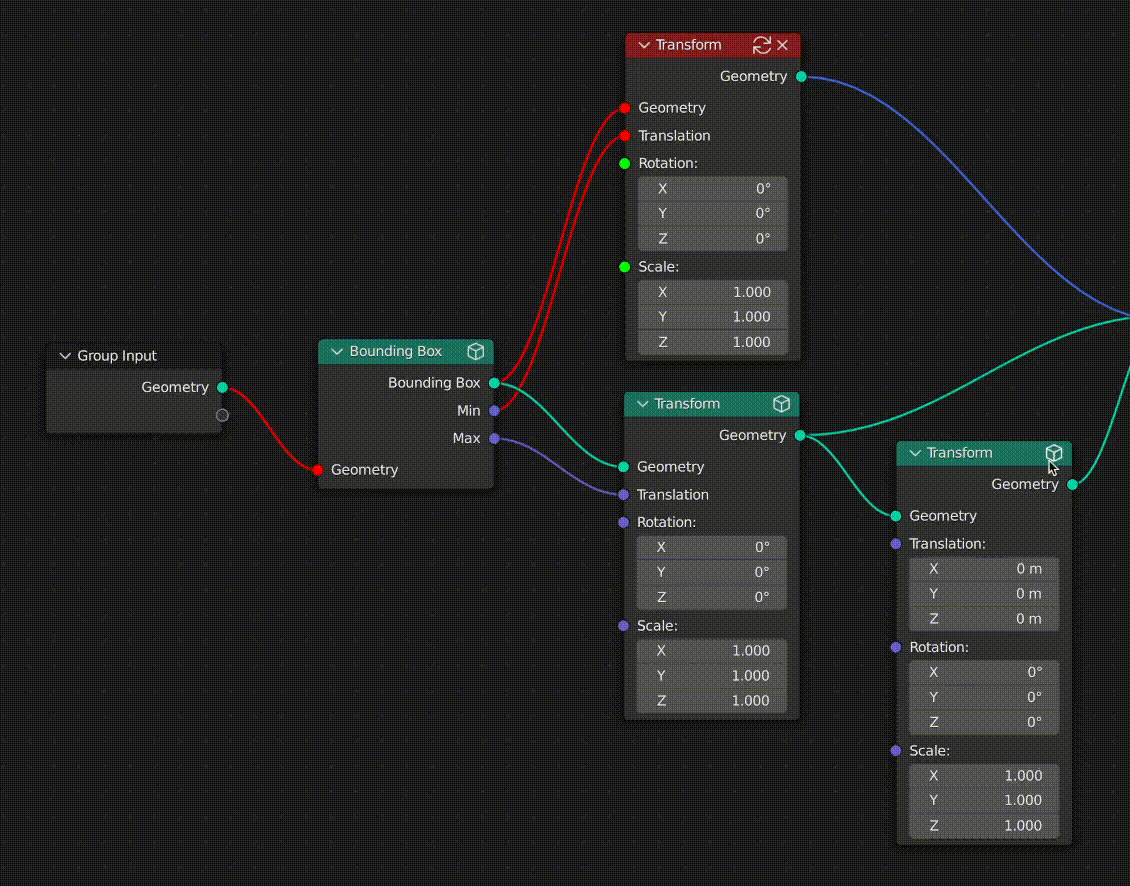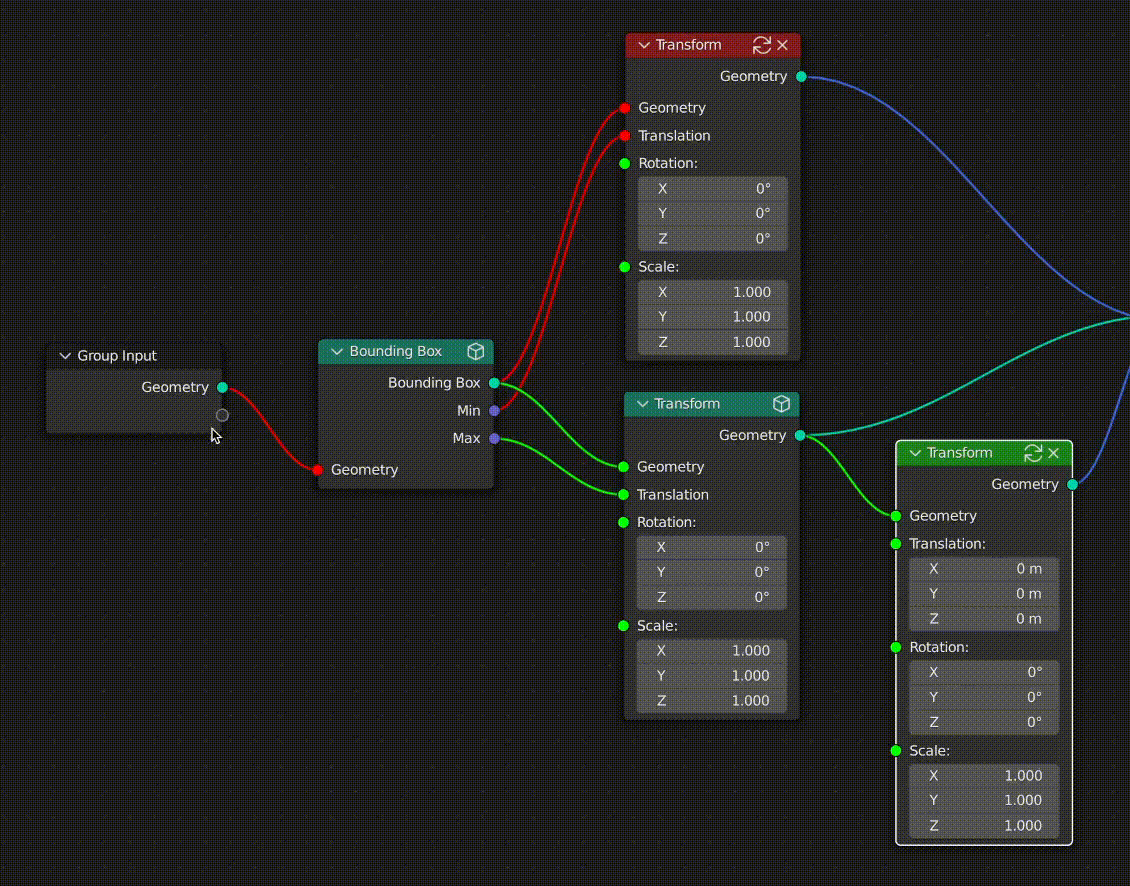
Socket & Link Coloring
To give the user a visual understanding of the state of caching in the graph, I also opted to color sockets and links with 3 states:
- Clean input sockets and links are colored green
- Dirty input sockets and links are colored red
- Cached output sockets and links are colored blue
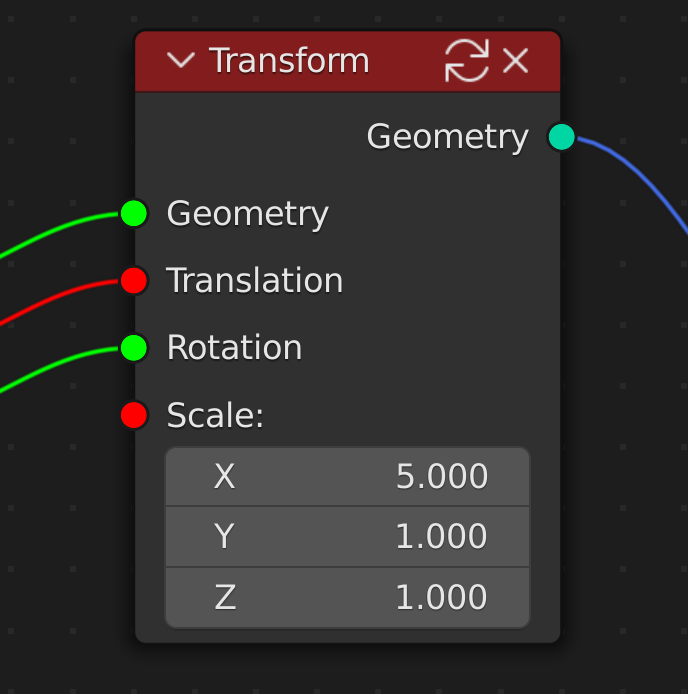
The state of cached links is propagated throughout the graph every time something changes upstream from a cached node. This makes it easy for users to see what data has changed since the node was cached.
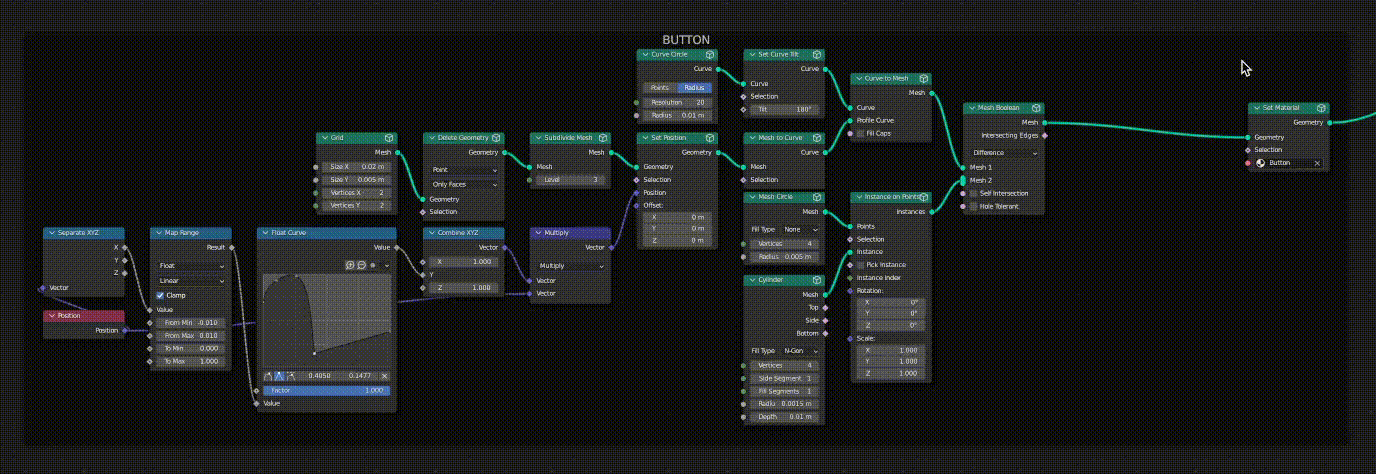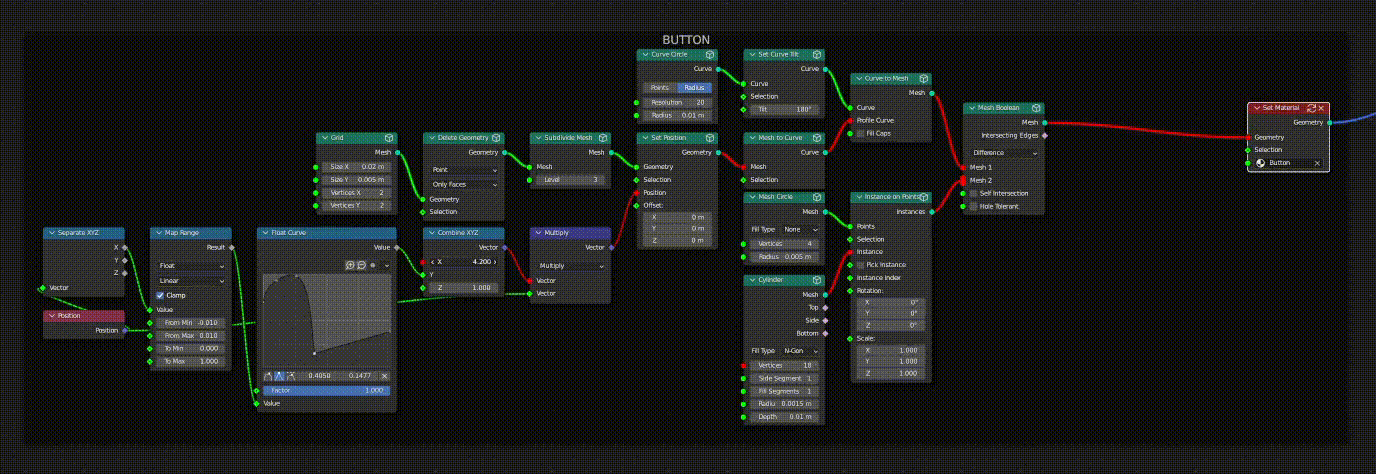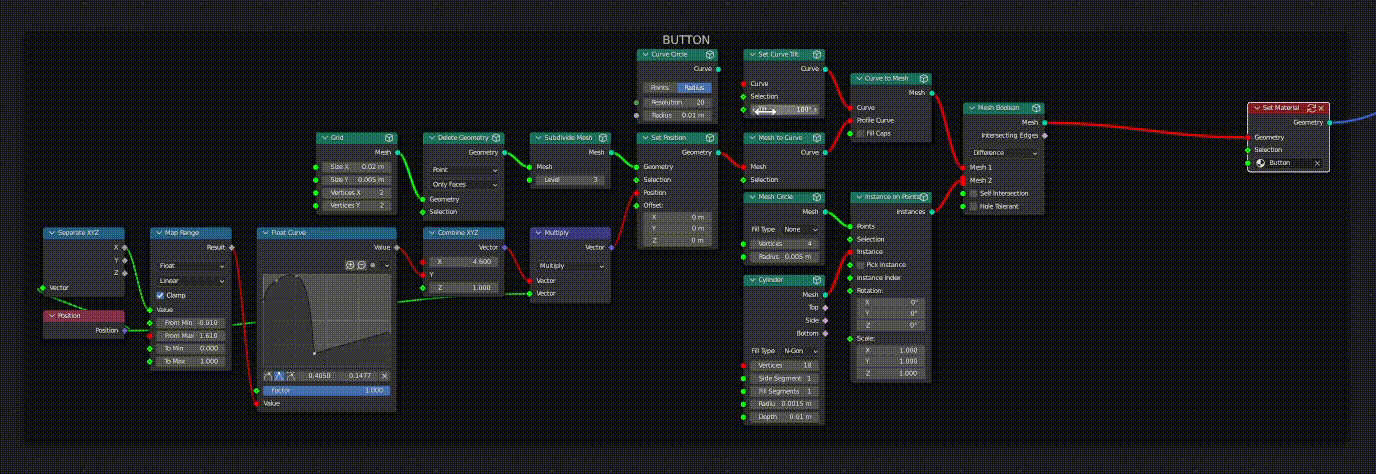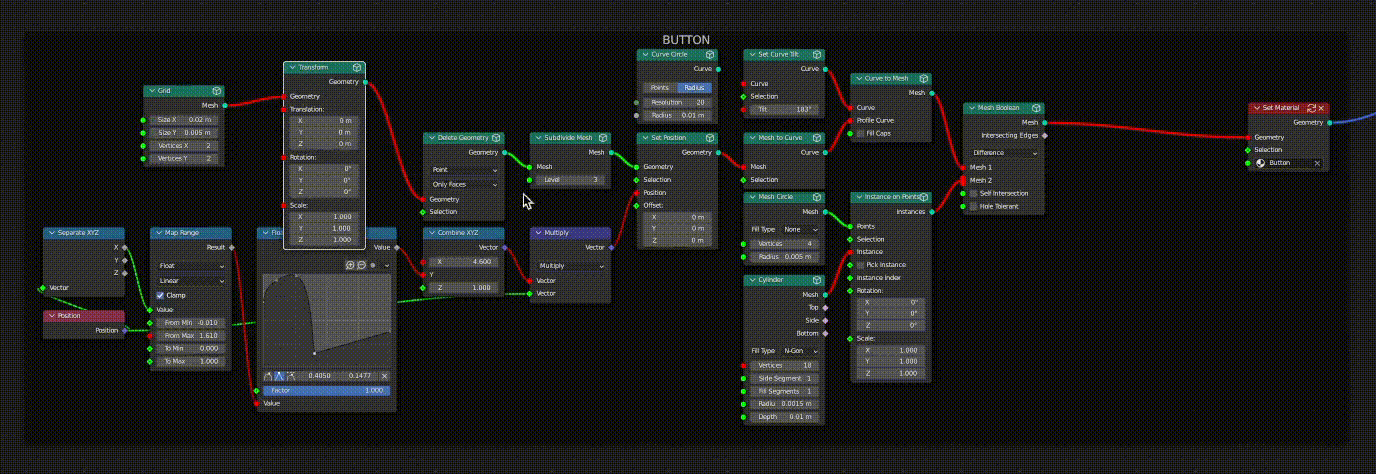
In the case where a given link or socket is associated with multiple downstream nodes, the dirty (red) status will always take priority over the clean status (green).
The main issue with this design is that it once again breaks the UI conventions. Link and socket color are typically used to indicate type and also red is already used for links between incompatible sockets and muted links.
One alternative idea might be to change a link’s style instead of color, similar to how it works for muted and field connections:
This is not particularly clear in larger graphs though and it doesn’t solve the issue for socket colors.
Another idea might be to outline the links and sockets or potentially tint their existing color.
Problematic Areas / Implementation Issues
UI
As discussed in the section above, the UI design in this prototype is very rough. To achieve any of the alternative ideas mentioned, a more complete design proposal would need the ability to express more information within node trees then what is currently possible. This would likely require larger / more drastic changes to the general node drawing and UI code, as well as potentially significant changes to the current style of Blender node graphs. See node_draw.cc.
Colors
The only components of a node that can have their color changed programmatically are the header, sockets and links. The body color is set by the user and the text and other UI is colored based on Blender theme settings for icons, text, etc.
To avoid making any large changes, I chose to simply color the header, sockets and links in the prototype.
Implementation
In this prototype, cache status is stored on the bNodeSocket DNA structure. Specifically, the variables is_cached_count and is_dirty.
is_cached_count tracks the number of paths from that socket to downstream cached nodes and is_dirty is simply a flag saying whether the socket is dirty or not.
These variables are only ever set on input sockets because output sockets can have multiple links connected to one socket. The reason they are not stored on links is because we need to be able to store when sockets with no link are dirty. This can happen if the user changed the socket value using the UI of the node.
However, multi-input sockets can have multiple links to one input socket and do not work correctly in this prototype.
Node Groups
Node group nodes cannot be cached in this prototype. (This is different to caching nodes within node groups which does work, discussed further down.)
If this were possible, it would provide much more control for users by enabling them to cache arbitrary sections of their geometry nodes graphs.
The reason this does not work is primarily an issue with the current Geometry Nodes Evaluator. The evaluator flattens the entire node tree before evaluation and this makes it difficult to determine where specific node group input and output data/sockets are in the tree for caching. It may have been possible to make this work but it would have been fairly messy and would benefit from some modifications to the evaluator. The Geometry Nodes Evaluator 3.0 looks like it will solve this as it mentions removing the need of inlining all nodegroups.
Storing the Cached Data
This is by far the biggest issue with implementing caching.
You would expect that when a node is cached, the cache can be stored on the bNode or bNodeSocket DNA structure (i.e on the node). However, the issue is that a given instance of a bNode is non unique (and by extension bNodeSocket’s have the same problem).
For example, if we create a tree with two duplicate node groups, it will now contain two instances of the same node:

The same situation can be found when you give two separate objects the same geometry node tree:

In both of these cases there are now two instances of the same transform bNode.
If we were to try caching the transform node, which geometry data would it store?
On the modifier
To solve this issue, I chose to store the cached data on the geometry nodes modifier instance. This is similar to how the logger works (see NOD_geometry_nodes_eval_log.hh) except with some differences.
The modifier stores one big cache structure which is essentially a mapping from sockets to caches. bNode’s and bNodeSocket’s are unique for a given tree level and so to uniquely identify sockets in the current modifier node tree hierarchy, it stores it’s own tree hierarchy consisting of TreeCache, NodeCache and SocketCache’s. (see NOD_geometry_nodes_cache.hh)
With this working, different cache data can then be stored for each instance of a geometry nodes modifier. This works well in a lot of cases. However, it also leads to some very unintuitive and broken situations, explained in the next subsections.
Multiple Objects with the same Geometry Nodes Tree
With the cache being stored on the modifier, this scenario does work but it is not very intuitive and the cache status UI does not work correctly. The reason for which is discussed under the “Disconnect between UI and cached data” section.
As you can see, enabling caching enables it for all instances of the node tree. Therefore, when the same node tree is added to the suzanne it only then caches the data. However, refreshing the cache will only refresh the singular cache. There are also many issues to do with invalidating cached data in these situations which are not solved in the prototype. For example, if you disable caching on a node in the tree, it will only clear the cache on the currently selected modifier.
Nodes within Node Groups
Caching nodes within node groups works, but it is also not intuitive.

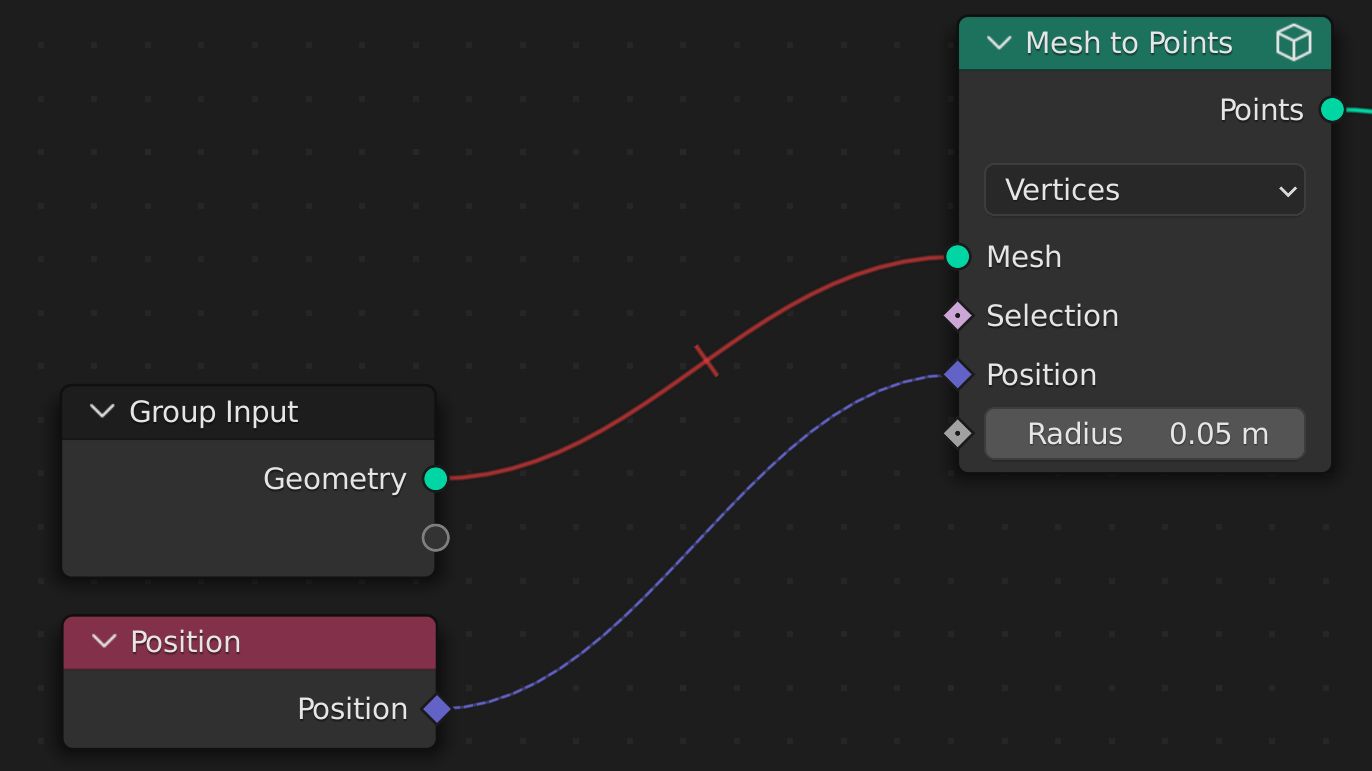
Here you can see I enable caching on the “Mesh to Points” node within the node group. Remember that the evaluator flattens the entire tree before evaluation. Therefore, the “Mesh to Points” node is the last node before the output and so when I change either of the transform nodes nothing happens. This case works as you would expect, the main issue is that the colored links and sockets UI is missing.
However, what if you try to duplicate a node group which has caching enabled for a node?:
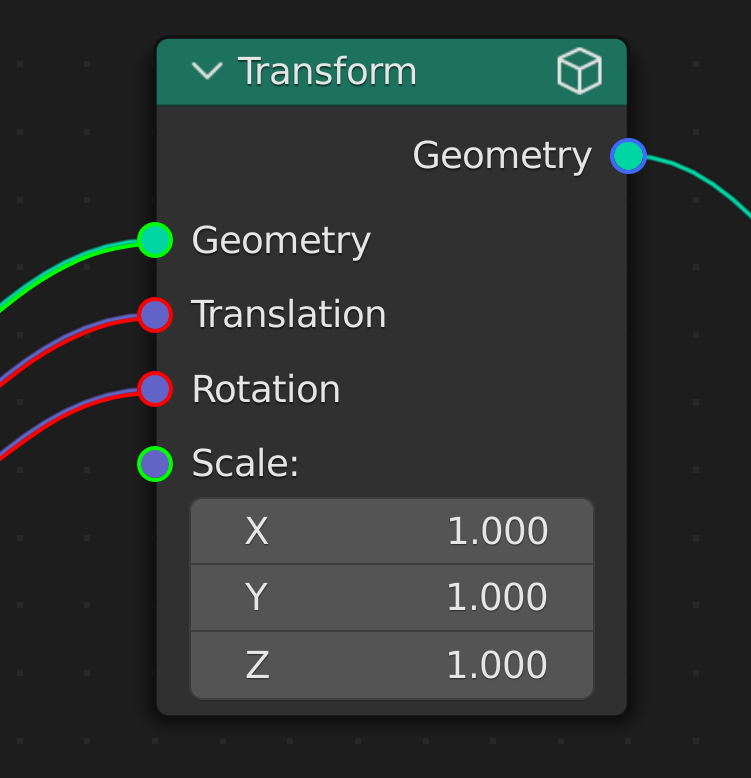
In this GIF I create a node group out of a transform node and then click to enable caching on the transform node within the nodegroup. I then duplicate the nodegroup and place it downstream in the graph.
In this case, the cache for the duplicate instance of the node group is only stored when it gets dropped into the tree. Then both caches are cleared when caching is disabled for the transform node. This is not intuitive at all.
The reason that the colored links and sockets UI is missing for node groups is because of the fact that bNodeSocket’s are non-unique across node groups and the UI status is stored on the bNodeSocket’s.
Disconnect between UI and Cached Data
Both of the above subsection issues stem from two places.
Firstly, the ability to use a single node tree data block in multiple places.
Secondly, the fact that the data for storing and controlling cache state for the UI is stored in the DNA structures like bNode (see use_cache flag), bNodeSocket, etc which is disconnected from the actual state of the cache stored on the modifier.
This leads to the clean vs dirty status of the tree being incorrect in situations like this:
Potential Solution
A potential solution to this issue of a “disconnect” would be to store the UI status on the modifier as well. From reading the spreadsheet code, it seems possible to retrieve the data from the currently selected modifier and draw a different UI depending on it.
This would ensure that the UI is always directly synced with the current state of the cache. It would also allow for separate UI for duplicate instances of the same nodes/trees.
Capture Attribute Node
The capture attribute node does not work correctly with caching in this prototype.
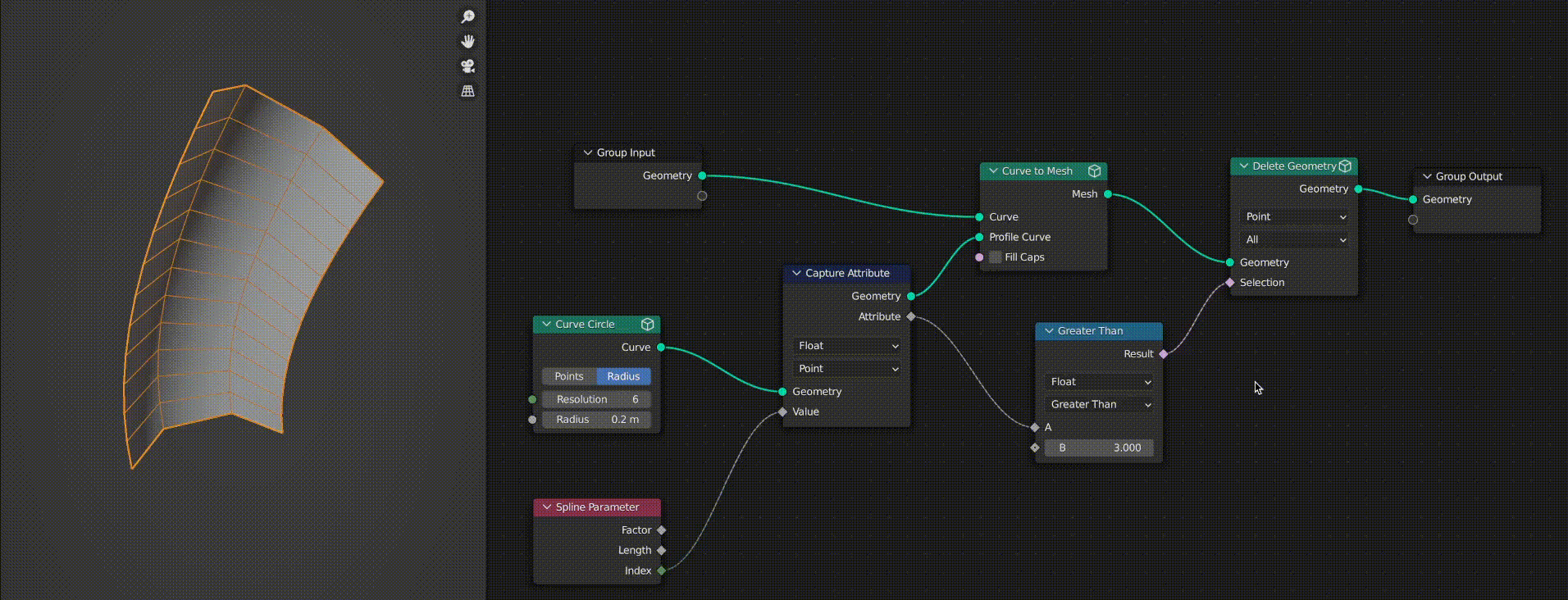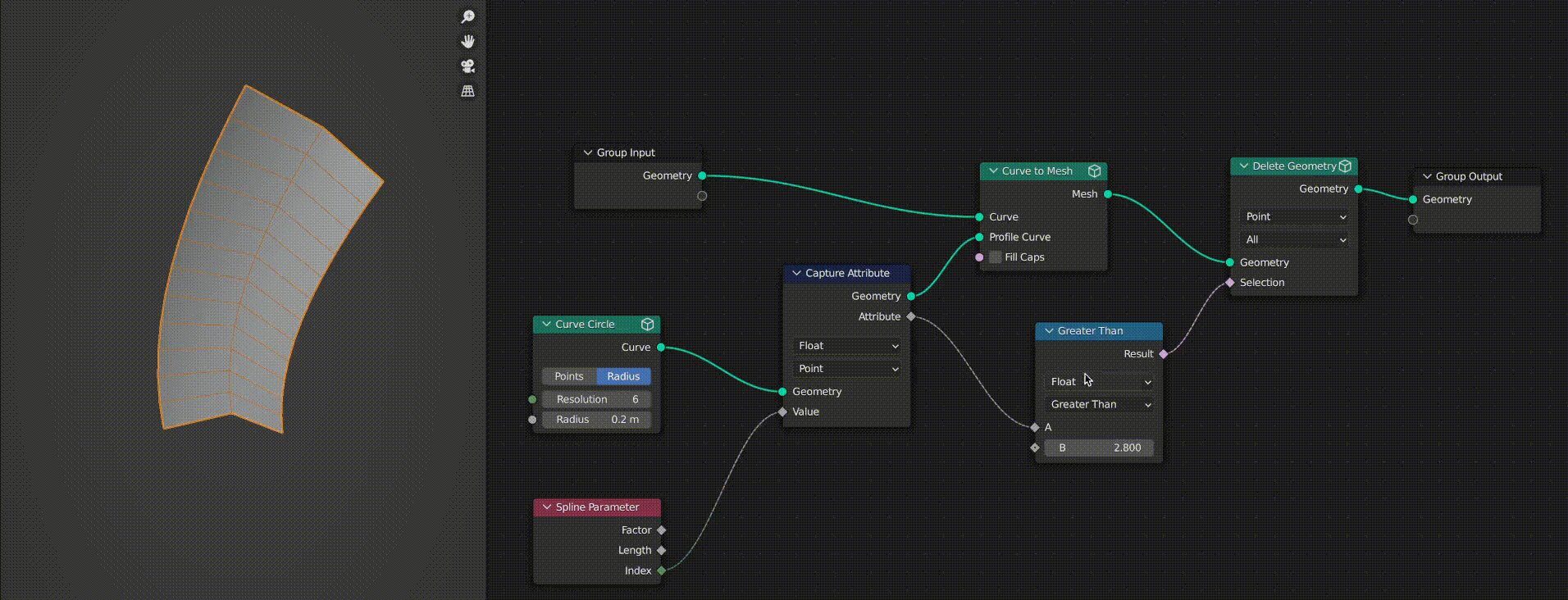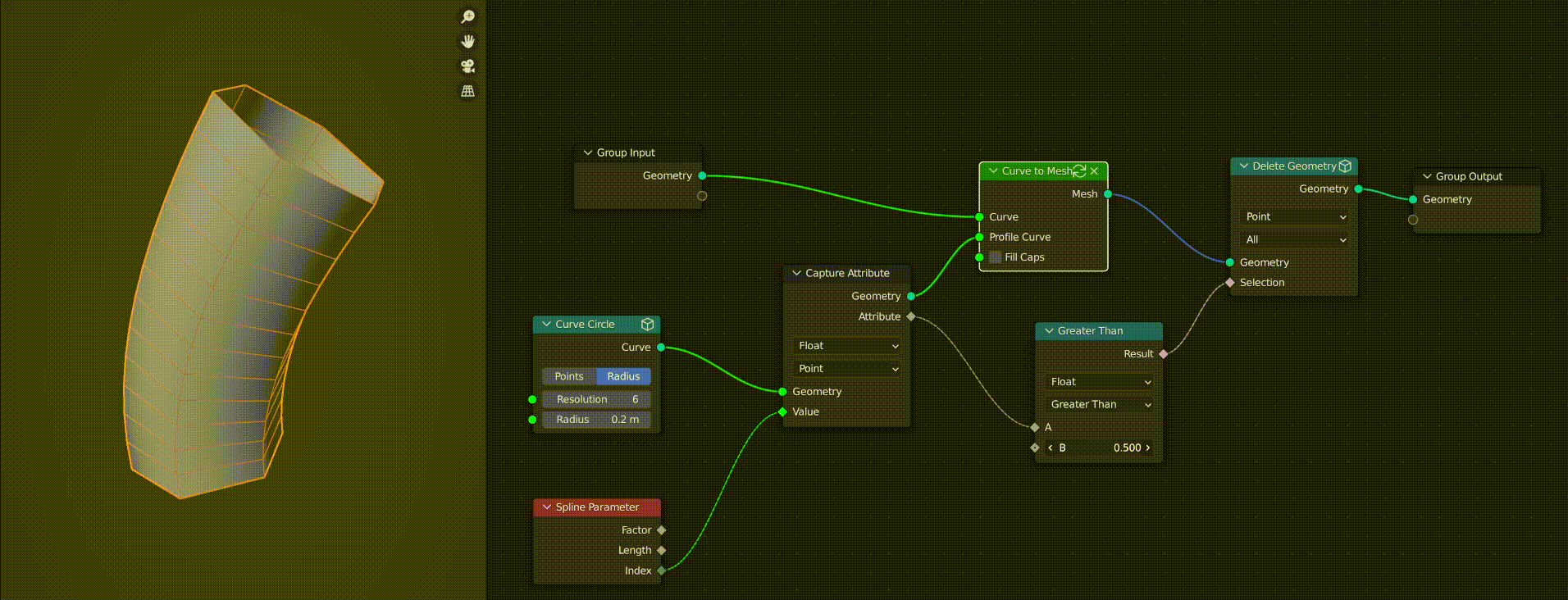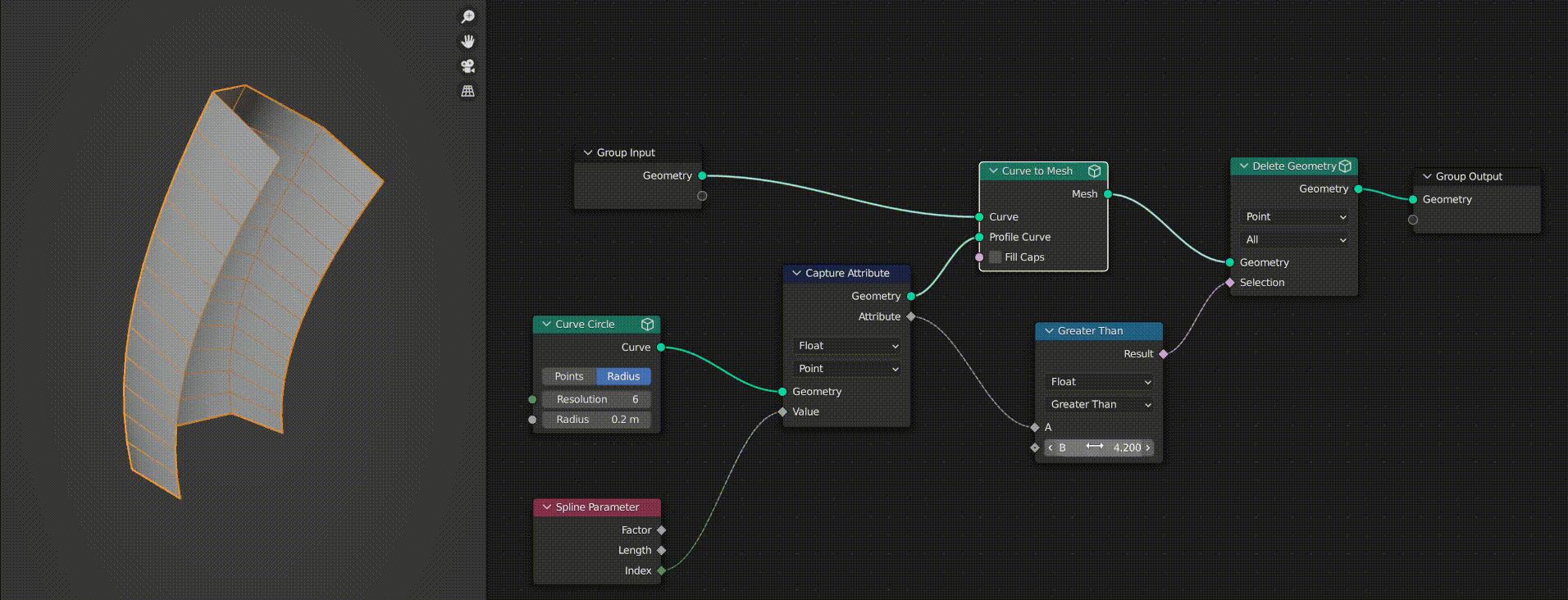
As you can see in this GIF, when the “Curve to Mesh” node is cached the “Delete Geometry” node stops working correctly. This is because the selection field evaluation becomes incorrect as it relies on an attribute captured from the curve circle.
As a user you might expect this to work fine, because you may think that “Capture Attribute” does not affect the geometry passed through it. This had me confused for quite a while.
However, it turns out that capture attribute actually stores a new attribute on the geometry passed through it and then it passes a reference to this attribute out on the “Attribute” output. The cached geometry does have the new attribute, however when the tree is re-evaluated (as I change the math node) the capture attribute creates a new attribute reference and outputs it. As a result, the reference does not match up with the cached geometry’s attribute and it fails to evaluate the field correctly.
I didn’t spend enough time digging into this to see if it could be fixed but it is definitely a major bug.
Future
Apologies for such a massive post, a big thank you if you made it this far!
I am finishing my internship at Unity this week, however I plan to engage in discussion under this post and may be interested to contribute personally in the future.
That being said, a dedicated team at Unity is investigating potential work around this topic and are interested in potentially aligning on a future design proposal.
I look forward to hearing everyone’s thoughts on caching in geometry nodes and the various designs/issues discussed here! If you have any alternative ideas please share them.