could you show us an example of users abusing cache(s)?
Because it really seems like a bad habit problem, from these user(s) side
why do these users need so many caches checkpoint?
perhaps they simply need to place them more cleverly
could you show us an example of users abusing cache(s)?
Because it really seems like a bad habit problem, from these user(s) side
why do these users need so many caches checkpoint?
perhaps they simply need to place them more cleverly
Maybe have the built in cache on every node be a quick approach when you need to freeze unfreeze quickly without the need to export but when you have to export it aka houdini style for VFX or what not, then you’d use a dedicated node with all the options you desire.
I personally wouldn’t need such a node so i myself would use the ui freeze button while people who need all the control over the cache would use the node version.
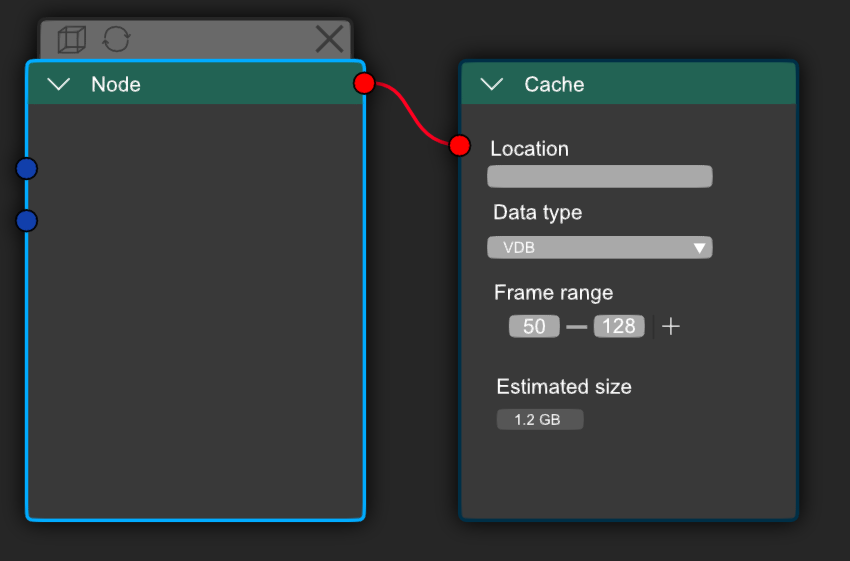
Here is an example of both systems, for quick caching there’s the UI element and for complex /complete control you have the node.
In this case i added a new socket type which i put at the top of the window as a exit socket which would only connect to a cache node type, the idea is that the cache node is unique and it would have to be differently positioned than the rest of the nodes, you could position it above the tree which would make it obvious what the node is. But this is a rough visual sketch ![]()
we did the cache nodes on lotr w shake for compositing. users were “in the flow” of creating and liked the interactive feedback so they made them everywhere. I did it too. but, by comparison the old compositing tool from softimage eddie had caching built in per node and the same comps I did for the balrog fire sprites were half as many nodes.
Conclusion both system is welcome… one for export and one for the COMPACT compréhension… But i’m stay in my position… at this state blender has a few node… one more is not a bad idea stay in this idea the all options are a NODE … sorry but the main idea great is a node for the cache like my idea… but i agree your system is cool ! But not perfect and a button like auto-update cache is an idea too take it !
But i agree with more talking and more practice i can accept your system is like simple and cool i’ll admit it ! i can’t say is a negative point ! i want see more ![]() You have my chance is true i like the idea “Compact” and available in all nodes ! i want see more
You have my chance is true i like the idea “Compact” and available in all nodes ! i want see more ![]()
But in visibility is an horrible design your idea…
A dedicated Cache node would be better in terms of UI and visibility.
Also would be good to be able to Freeze / Chache a Geometry Nodes modifier as a whole.
This one is more the idea like i take it for build a real system  i like it but he need a different way to put the output position of the node not like a traditionnal node because he produce an other generation from the bottom of the node is more simple i thinks and is clearly a different compute
i like it but he need a different way to put the output position of the node not like a traditionnal node because he produce an other generation from the bottom of the node is more simple i thinks and is clearly a different compute
There are some really interesting points here, that we hadn’t considered at all.
The first point that I think is coming out of this discussion is that there are really two use cases that need to be addressed: Caching vs Freezing. Maybe a specific naming convention needs to be determined to distinguish between the two (Disk Cache vs Interactive Cache?), but these are the two terms I’ve seen used in this thread so far.
The freezing use case is to address performance and workflow issues that an artist would have when working with a large node tree. We wanted to give an artist the ability to just store the results of a slow node/section of a node tree so it wouldn’t constantly execute, and give the user a much more interactive experience when editing the tree.
The caching use case, as I understand it here, is for a larger production pipeline.
This is definitely a use case we didn’t think about during the this work, as we didn’t have a user requesting that type of caching. Certainly this use case will require some kind of disk storage.
Obviously any solution will need to take both cases into account, but I think it’s worth distinguishing the two as they have quite different users and needs.
The use case that we were addressing with our internal users was freezing. If I’m an artist just building stuff with geometry nodes, I want an easy and seamless experience that doesn’t interrupt my workflow.
I really like this idea by @Dragosh - something simple and convenient for those who don’t need a disk-backed cache, but giving production sized projects a node for more comprehensive cache storage.
Some interesting points that we didn’t address for the freezing use case:
Can’t we just update only what’s needed? instead of recalculating everything?
edit* I was wrong, the problem cannot be fixed with a better evaluator it seems? i was confused because Houdini can avoid useless recalculation, but as @JskJ explained below, they do implicit caching behind the scenes! they do it so well users do not even notice, I did not know about this!
It is impossible not to call update.
You can store data in a node and say that if nothing has been updated before it, then the cache is used, not the input. And here the appraiser may not calculate the data right now, as a switching node. But there is no information about whether the update happened before or after the node.
I think Houdini handle this problem with implicit caching just like @modmoderVAAAA suggested.
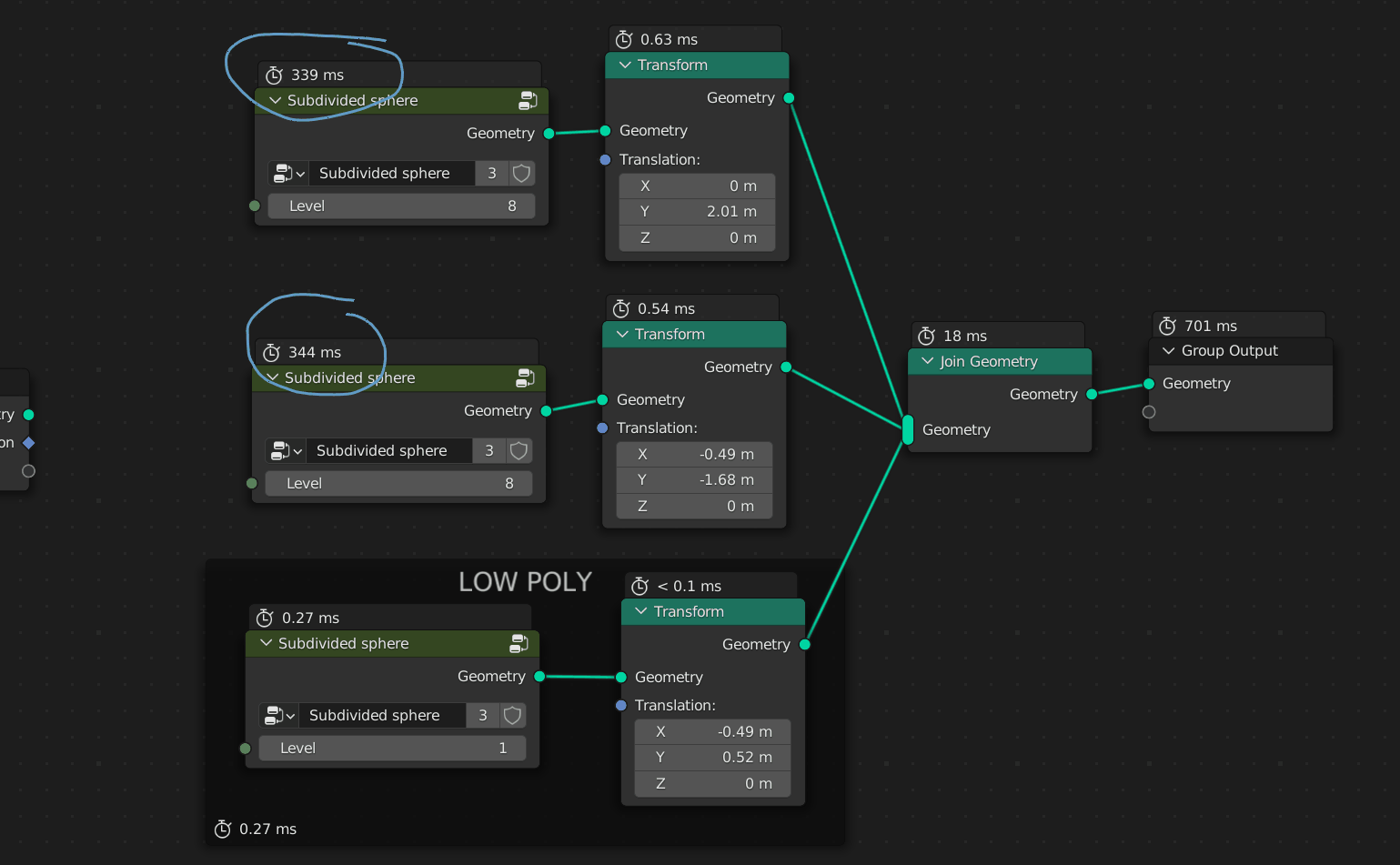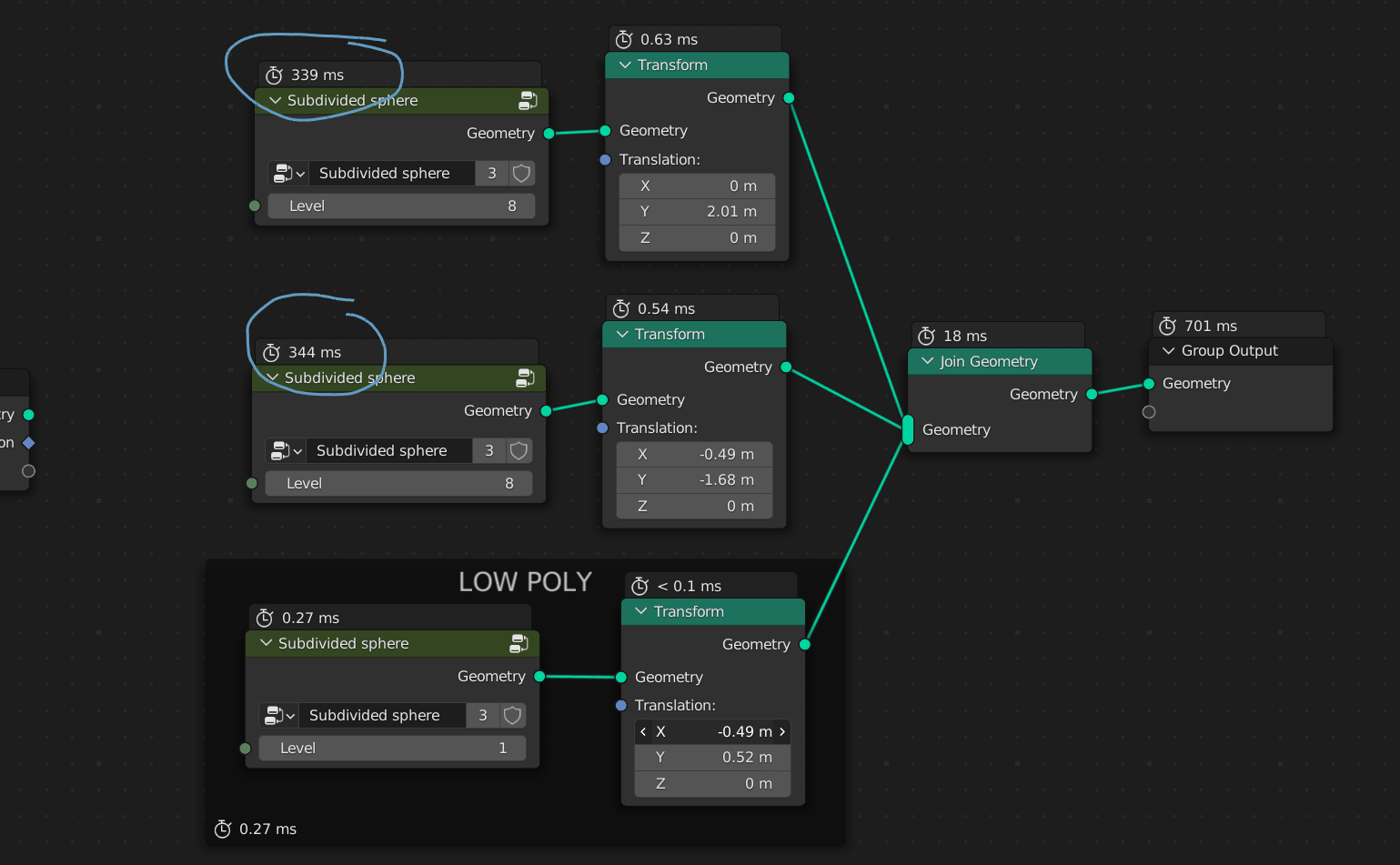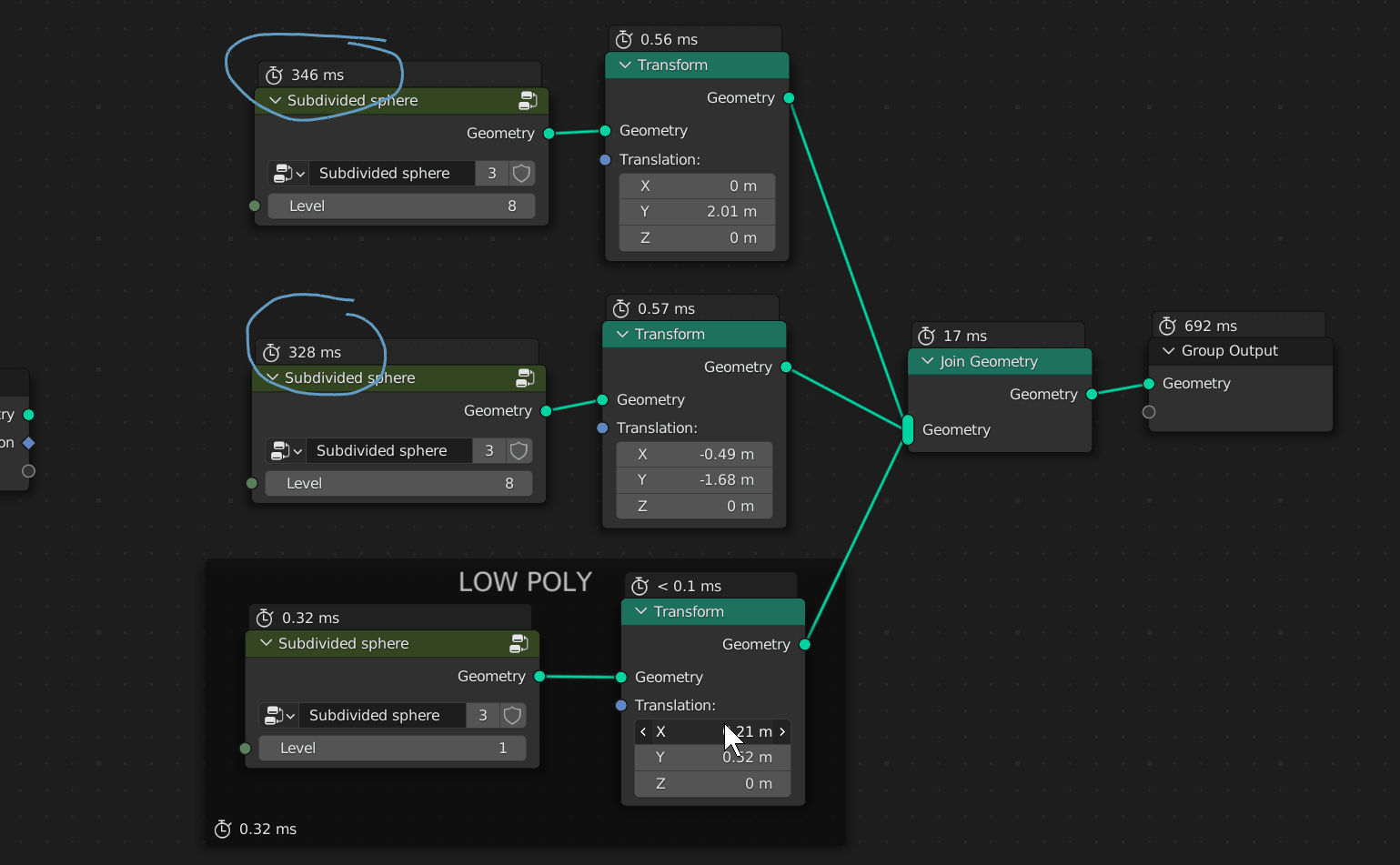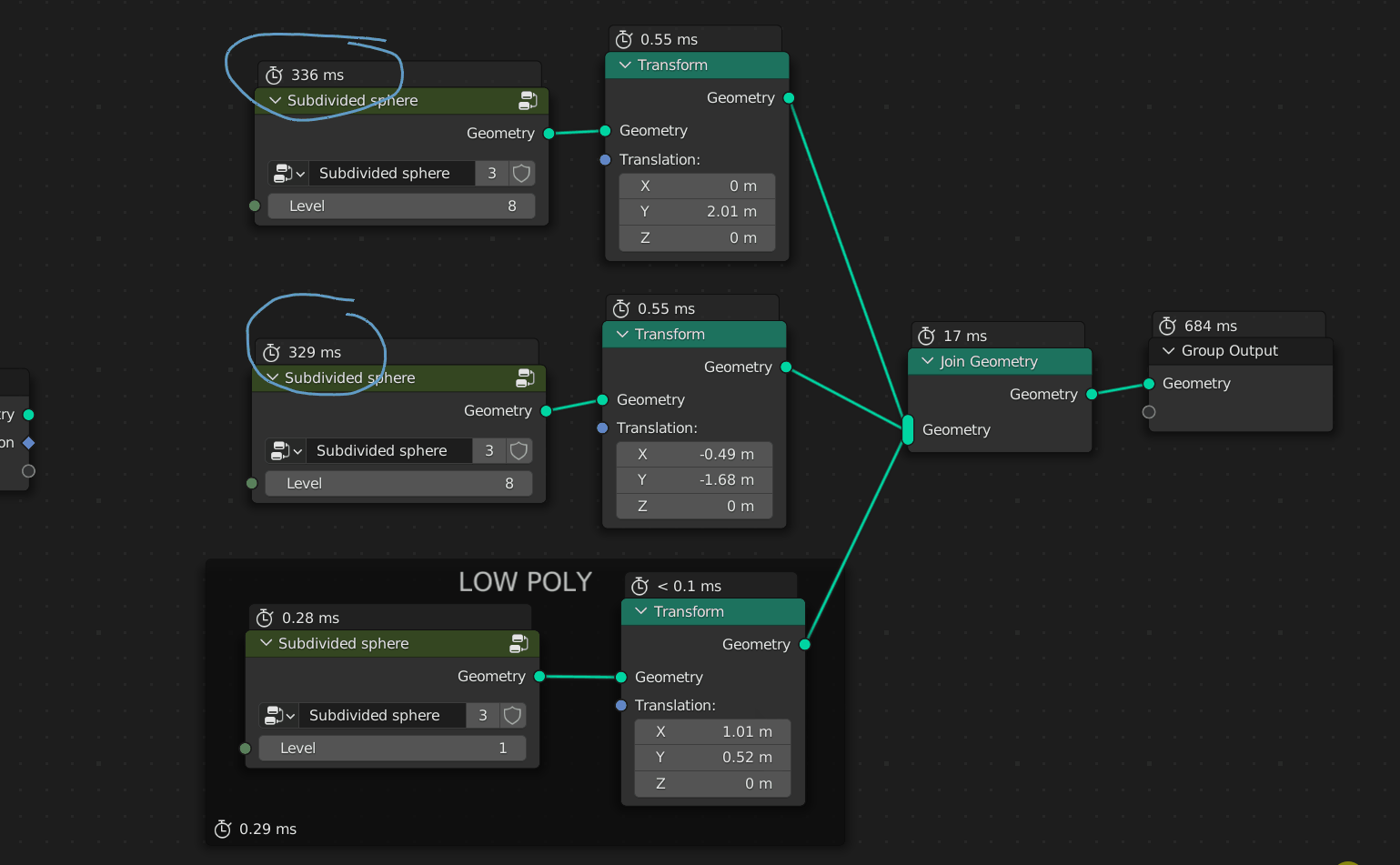
In H, we can see that each nodes can hold XX mb of data
We need to be carreful, not mixing up two type of caching needs
we can easily mix up caching as a “freezing” behavior, keeping the info that we already calculated in ram, it could be done automatically like H, and caching for “baking” an animation or something really heavy into disk
Please correct me if i’m wrong
It sounds like the practicality of implicit caching depends on how partial updates are handled. There are plenty of situations where you could reduce a cache down to a single attribute column, or skip caching entirely by applying changes in-place, delta-updating attributes in a span of indexes in the final mesh, but those kinds of optimizations would need to be deeply integrated into the evaluator.
On the flip side, memoizing and delta-updating just non-field inputs might cover enough of the common bottlenecks to serve as a practical starting point. And approaching the topic of caching in general from the perspective of incremental computation could make it easier to identify where full-state caching is genuinely needed.
This is an amazing proposal. I hope this will be considered seriously. Thanks to the Unity team for going forward with implementing the idea.
I personally think that we need all the options mentioned, like the automated caching, the implicit caching and the manual caching. However, the manual caching should be shifted to a node called a bake node, instead of a caching node. That way the user can stop the tree processing by adding an explicit geometry bake node to cache all the upcoming stream to a node and disable the upstream processing.
Thanks for your work on this prototype. Caching is a much needed feature indeed. It’s kind of sad that Geometry Nodes currently has to recompute everything after every change.
As mentioned in the thread before, there are different kinds of caches which are also summarized here. I’m looking at this discussion mostly from the perspective of memory (and maybe compile) caches, which intend to make working with Blender faster by doing less redundant work. I do believe it will be better to make this kind of caching transparent to the user, i.e. the user does not have to decide what to cache explicitely. It should “just work”. Giving hints to Blender about what should be cached can always be implemented on top of that if necessary. Other kinds of caches and freezing operations will need user interaction.
There are some key challenges when implementing automated caching, some of which you started to address already:
I have some ideas on how to deal with these challenges, but more technical work has to be done if we want to end up with a good automated caching solution. Caching and especially cache invalidation is a hard problem and will require the use of heuristics.
Some notes on how the challenges above can be addressed:
Even if we just had manual caching as in this prototype, the problems with detecting when the cached value is outdated and how to deal with anonymous attributes would have to be solved. Additionally, manual caching needs more work on the UI.
The reason this does not work is primarily an issue with the current Geometry Nodes Evaluator. The evaluator flattens the entire node tree before evaluation and this makes it difficult to determine where specific node group input and output data/sockets are in the tree for caching.
Right, this should become more doable with the refactored geometry nodes evaluation system.
You would expect that when a node is cached, the cache can be stored on the bNode or bNodeSocket DNA structure (i.e on the node). However, the issue is that a given instance of a bNode is non unique (and by extension bNodeSocket’s have the same problem).
Storing cached data on bNode or bNodeSocket is unlikely to be the right solution. It’s not really the node tree that contains the cache (but the modifier or some global entity). Different node instances will also be less of a problem with the new geometry nodes evaluator, because there will be a unique identifier for every such instance.
You said all… conclusion this works… need more works and research. But is a good beginning.
Thanks for working on this!
Regarding automatic vs. manual caching, I think it’s better to implement this transparently as Jacques mentioned. The most common need for caching I’ve seen is to avoid re-computation when something changes in the node tree. We shouldn’t need many user visible options to make that work. It’s interesting to see all the UI controls in the prototype, but I think they would end up being more confusing than helpful. IMO a benefit of Blender’s node design is its use simple UI concepts; spreading caching controls everywhere complicates that. A node overlay could provide debug information about what is cached, but maybe even that isn’t necessary for users.
When users need more control over what is cached, where it’s stored, and for how long, it would be better to concentrate those controls in a single place, along the lines of the designs in this thread above and the “checkpoint” designs that have been around for a while.
Also, it probably makes sense to implement automatic caching before manual caching, since it places less burden on the UX, and leaves us with only the places that the complication of a more manual approach is actually necessary.
perhaps a ‘cache’ could be a collection ?

this way we seperate playback from simulation and simulation can be open ended,
I am using upbge to do this here
Hey everyone, thanks so much for all the feedback, really happy to see all the discussion this thread has started! Apologies for my very late response, I took a bit of a break this past week.
As was mentioned by others, it seems there are various types of caching being jumbled up in the discussion, and if possible the ideal final implementation would provide all types:
It seems as @jacqueslucke and @HooglyBoogly say, it would make sense to implement implicit/automatic memory caching first. Presumably, the work done for that would make it very easy to then add an explicit “freezing” functionality for better control.
Thinking in terms of implicit caching then, some immediate thoughts that come to mind are
It seems implicit caching would not guarantee a performance improvement for any specific node or section of the tree? It would only provide a general performance improvement.
For example, consider the case where a user is working with a slow boolean node in a large tree and they want to be able to transform the result of it in real time. It seems that regardless of how you implement implicit caching, the user can’t be guaranteed that the boolean node is ever cached as at it may have been evicted due to memory budget, heuristic, etc.
I feel like this issue would actually be a detriment to usability, because a user would randomly see different performance when editing values within the tree depending on if the cache clears something behind the scenes as they bounce between sections. (in extreme cases the difference being real time updates vs multiple second freeze)
Maybe this is just a limitation of implicit caching though, and is an example of why explicit freezing would be needed after implicit caching is added.
How would implicit caching work across key frames/timeline?
Just a random thought from what @LukasTonne said in this thread. This is something I never really considered with my original prototype. Since it was manually controlled, if something was cached then any changes to values in the tree by keyframes simply wouldn’t affect it.
However, with implicit caching, I suppose keyframed values would be the same as if a user was just updating the value themselves so maybe this is not an issue.
Will the evaluator 3.0 work greatly help or be necessary to implement implicit caching?
Essentially a question for @jacqueslucke, is there value in starting on implicit caching work soon or better to work towards the evaluator 3.0 first?
I think this prototype could be quickly transformed into an implicit version at the moment, except presuming we don’t want to cache the output of every node on every run, the biggest issue would be your point number 3 as you say. (of course, anonymous attributes would also not work)
Actually, maybe an explicit file cache solution would make sense to implement before implicit caching?
Considering all of the issues with implicit caching that would need to be addressed, it almost seems like it could be much easier to implement “explicit caching for cross software needs and/or large data” such as an explicit cache to file node (or other) first?
The only major issue I see is how to handle reading from vs writing to the cache in the UI, because of course you wouldn’t want it to do that every time the node tree executes. But maybe a manual button which reads the data into memory / writes the data to disk would suffice?
Would like to hear everyone elses thoughts on this too!
I don’t think you can implement implicit caching now, as Jacques already said, the program simply doesn’t know that an update has taken place. So, in addition to the new infrastructure for evaluating 3.0, it also makes sense to have a plan to change the update logic throughout the program or within nodes specifically for improved processing.
any thoughts on forming a collection and dumping copies of the geometry into it?
each frame = collection index
this way EVERYTHING is cached / its data.
I agree ‘freezing the stack’ is important, but I think we need to either have it happen in the modifier stack and the geometry node tree, or get rid of the modifiers all together then do it only in geonodes.
(we can mimic all the modifiers now in geometry nodes?)
The person who designs a GN node tree is not necessary the same person who use it in his workflow.
To be direct, I have a mixed feeling if an end user (someone who just want to use it, without caring about its implementation) has to put his nose inside a complicated GN node tree to control caching manually.