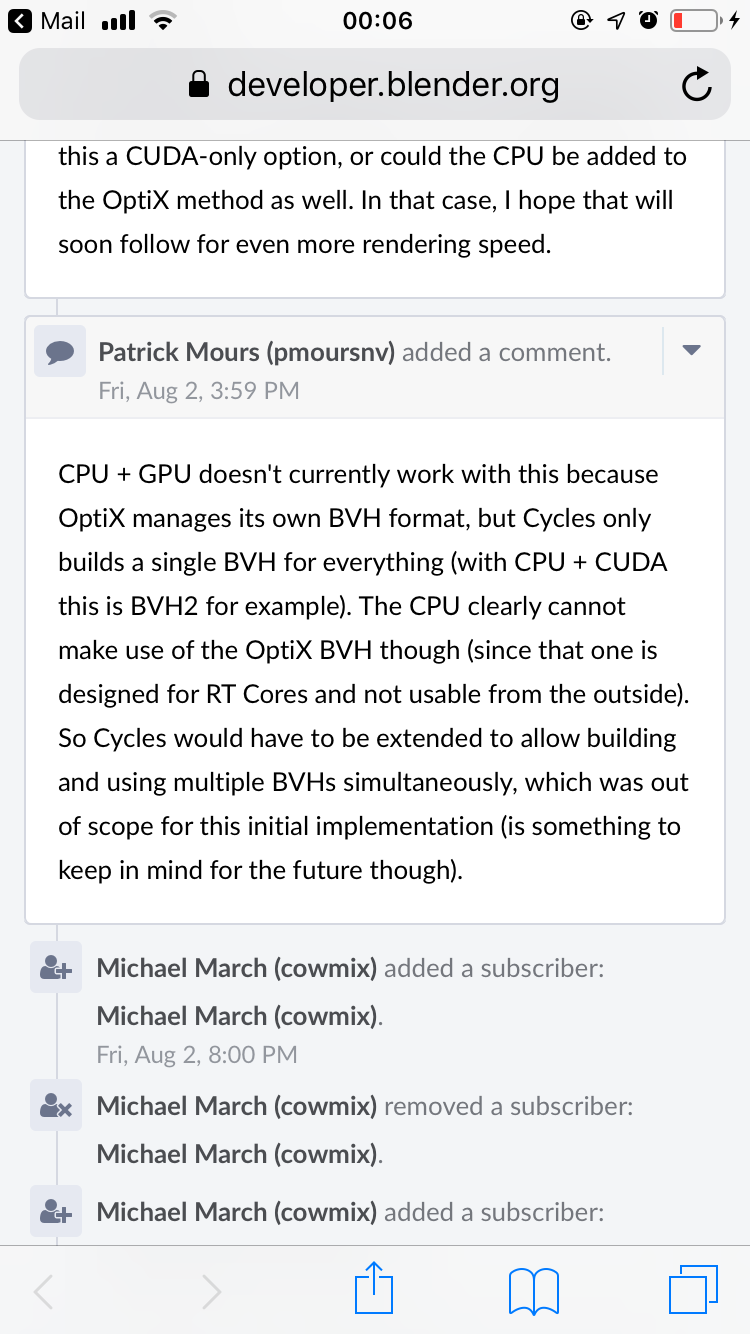
The problem seems to be the type of BVH, Optix uses an specific BVH system, Optix BVH, while with CUDA we have to use BVH2 and with CPU alone we can use BVH2, BVH4 or even BVH8.
So I think the fundamental problem here is how the rendering is implemented.
@brecht now that you are more focused on Cycles, could you consider as a possibility to change the way Cycles makes the renders?
I mean, right now each device renders a tile, so they need to have the BVH in sync and use the same BVH, could it be possible to allow each device to render the whole scene alone and sum up the results afterwards?
So let’s think that we have a render with 12 tiles, and we want to render with CPU and GPU at a quality of 20 samples (this is an oversimplification for explanation), could be possible to start the whole 12 tiles rendering with the two devices separately, each device would render on each pass lets say 5 samples per tile, once both devices have rendered the whole picture we would get 10 full samples, of course the GPU could be 3 times faster than the CPU so in the end in the time the CPU has rendered 5 samples the GPU could be able to render 15 samples, so after 1 CPU pass we got 3 GPU passes and the whole 20 samples image.
This could ease the mixing of devices and systems (like Optix with a completely different BVH) and it will also allow to mix BVH types (BVH8 for a threadripper for example, BVH2 for CUDA or OpenCL and Optix BVH for RTX) and it could ease also other features like noise analysis for adaptive sampling based on passes, etc…
Right now this can be done by handl we can render in three separated Blender instances and mix them afterwards, we may not end with an exact passes amount, I mean, we could get 855 pases when we explicitly defined 850 or 860, that could happen possibly, but it’s a minor issue compared to the benefits of having true GPU + true CPU + true Optix or Hardware RT.
What do you think @brecht
What