Hello,
One of the uses of Blender is like a “simple but well integrated with the rest of the application” video editor, through VSE. But I think that the sound has been left particularly behind.
I would like to suggest / discuss the minor improvements that would make sound more useful.
One of the first ideas I had was to add support for VST plugins, but in Blender’s guidelines they say that binary plugins are a no-no.
So I thought, what would be the minimum tools required to last minute sound editing? Equalizer? Some kind of filter perhaps?
Moreover, if you are going to edit something, you would need a visualization of if, so that would need VUMeter, or frequency visualizer,…
As a developer, I would not like to reinvent the wheel again:
I was “a little happy” to see that Audaspace, which is a library included in Blender, had several filters included, but it looks very “3d space / game oriented”. Would it remain in Blender? Has it continuation plans?
Other way would be to use the “complex filters” defined in ffmpeg, would it be possible?
And other option would be to include some well maintained library like “sox”.
What do you think would be the minimum improvements and the way to achieve them?
But more important: What would be possible to get integrated in Blender?
Since Blender supports jack/pipewire you can just connect a suitable DAW or what have you. Why put work into audio in Blender when we have great tools available?
Sorry for late answer, there have been a lot of discussion on this topic, and I will try to remember what has been said.
First of all, I think @sergey mentioned, that current system should be re-evaluated and perhaps redesigned. I don’t think there are concrete plans for this and I am not sure if this will have negative weight on contributions in this area.
As far as missing features, I think that VU meter is mostly requested and very useful one. Ultimately this would have to be implemented in Audaspace to return information about buffer in particular time period. There may be some difficulties, for example how to handle gramularity and synchronization.
Next highly requested one is better mixing capability. This stems from how data is currently organized. In VSE it would be useful if you could group sounds and adjust their volume as one block for example.
Having for example modifiers for sound should be possible to implement relatively easily last time I checked, but question is if and how this is needed. Particular processing methods have to be implemented in Audaspace, so I can’t tell how difficult it would be to use ffmpeg filters, or if this would be wanted feature.
I am not absolutely sure. I don’t think anybody would be against well working VU meter. Having better mixing options would require some basic design at least. I also wouldn’t say no to processing. But question often is do we need this and should this be job of Blender?
For example: I was reviewing awful lot of videos with sound track that had quite loud 8KHz whine. It was quite pain to render audio import it to audacity and use curve filter to get rid of it. But thing is, even if Blender had sound equalizer, it would probably be much much more simpler and won’t work for this particular case.
So not sure if there are some quick and easy improvements to be done. If you propose radical improvement, then I think there would still need to be demand so this could be prioritized.
It’s unclear if there would be a mayor re-engineering of the sound treatment
any major sound editing should be done in a “sound editing application”
So, any change / feature should be very simple in order to get something usefull and at the same time, do not compromise future changes in architecture.
So, in order to get simple improvements, we could forget about any “real-time visualizers” and complex sound operators. Perhaps:
2 new modifiers (to add to pan, volume and mono)
band equalizer / parametric equalizer
compressor
along the strip, show when the sound is saturated (some kind of “red marks” showing sound above certain thresholds)
nowadays a sound strip can show a static waveform. It could change to show waveform / show spectogram
I’m drawing attention to this subject because I would like to code some features for the VSE. In my little experience, VSE in Blender is the most stable video editor in the FOSS world.
Blender’s source code and architecture are complex. Analizing, coding, testing any feature are difficult, so I would like that any work done would be usefull in the long term.
Changes as you propose (audio processing) don’t rely on stability of current architecture (at least too much).
Maybe I have mixed in unrelated topic of potential changes in sound system - these would mostly address evaluation and animation since there are some limitations.
With what you propose, I think biggest problem would be priority. I hear requests for more audio features, but not sure if users themselves would prioritize these over other features. This is especially if current features are quite limited or buggy.
I feel that adding more audio processing options would essentially mean, that Blender now should be able to do advanced audio editing and I think it woud be best if such decision was made among admins with particular plans and developers that would create features and maintain the code in longer term. This could be only my feeling though and audio features could be added as needed or as they are contributed. but still I think it should be discussed if there is need for these features. Personally I wouldn’t say no, but I am not admin and wouldn’t use these features very often, so I don’t want to have much say in this matter.
Yes this is implemented on waveform data, which is not perfectly precise.
This should be possible to implement on VSE level. I have calculated memory requirements for 4 hour strip - waveform takes 14MB in memory, while spectrogram would use 10-20x more. It’s not much, I say it could be acceptable, but much more memory would be required for processing - more than 1GB which is bit questionable. Sure most strips aren’t 4 hours long, but I like to think of edge cases when implementing features with possibility to be resource intensive. VSE doesn’t have random access to samples so drawing portions is not really an option (it would be too glitchy anyway) Also this is assuming monochromatic texture and it would require false color shader possibly. So while not impossible it looks quite challenging. Not sure how math for FFT works out, perhaps it is possible to decimate sound data to 1 byte instead of using float with such small vertical resolution and also you could have 4KHz limit, so you can resample sound to 8KHz which is what most editors do by default I think. This would drastically reduce requirements for memory storage at which point it would be best to store raw data probably, which would make waveform more precise too. Not sure what is more efficient though whether it’s doing FFT or caching processed data.
Hello,
in order to continue with something little but achievable, the list of possible improvements in VSE, sound related could be:
band equalizer / parametric equalizer
compressor
[PERHAPS] show waveform / show spectogram per sound strip
[EXTRA] improve control over mixing of channels / strips
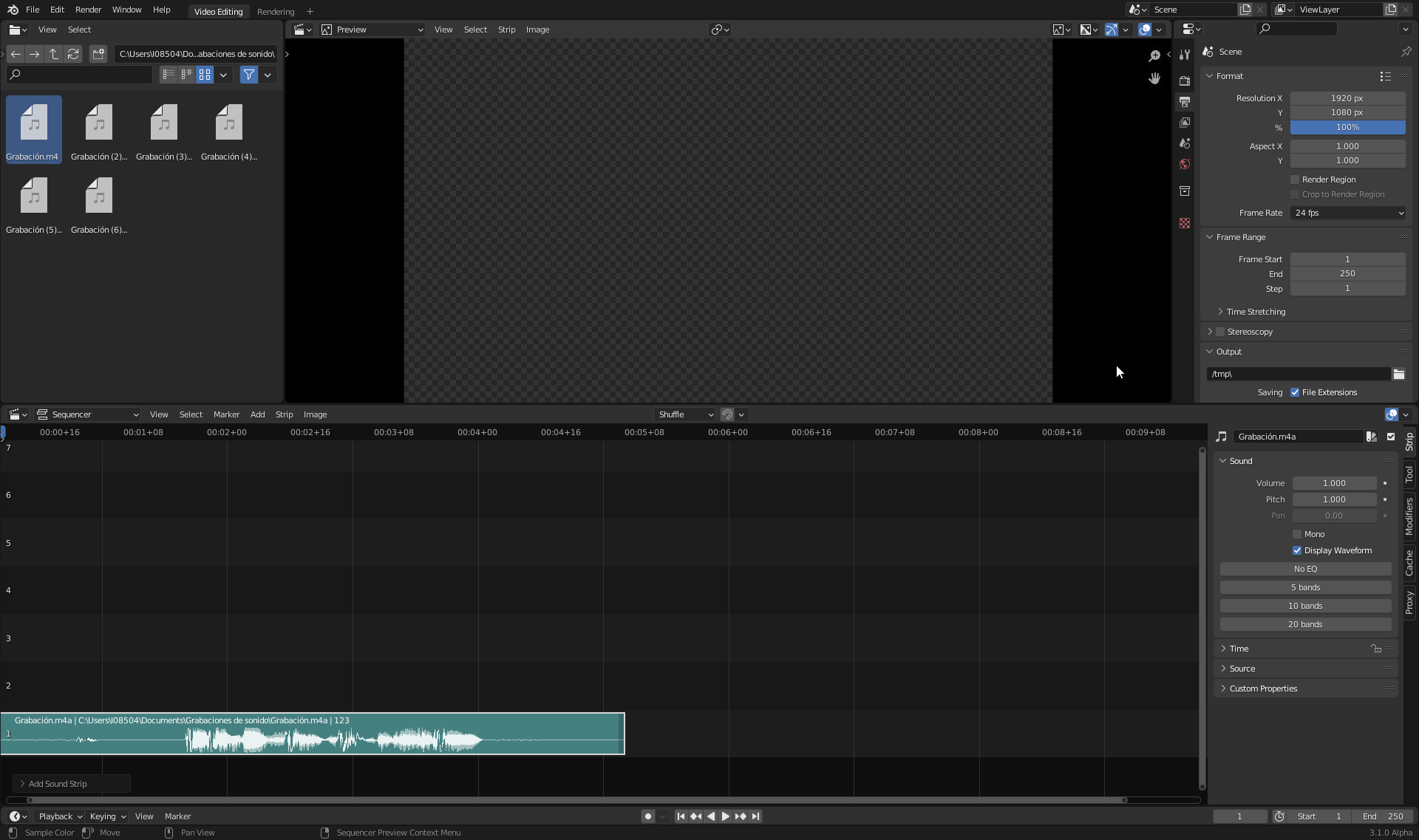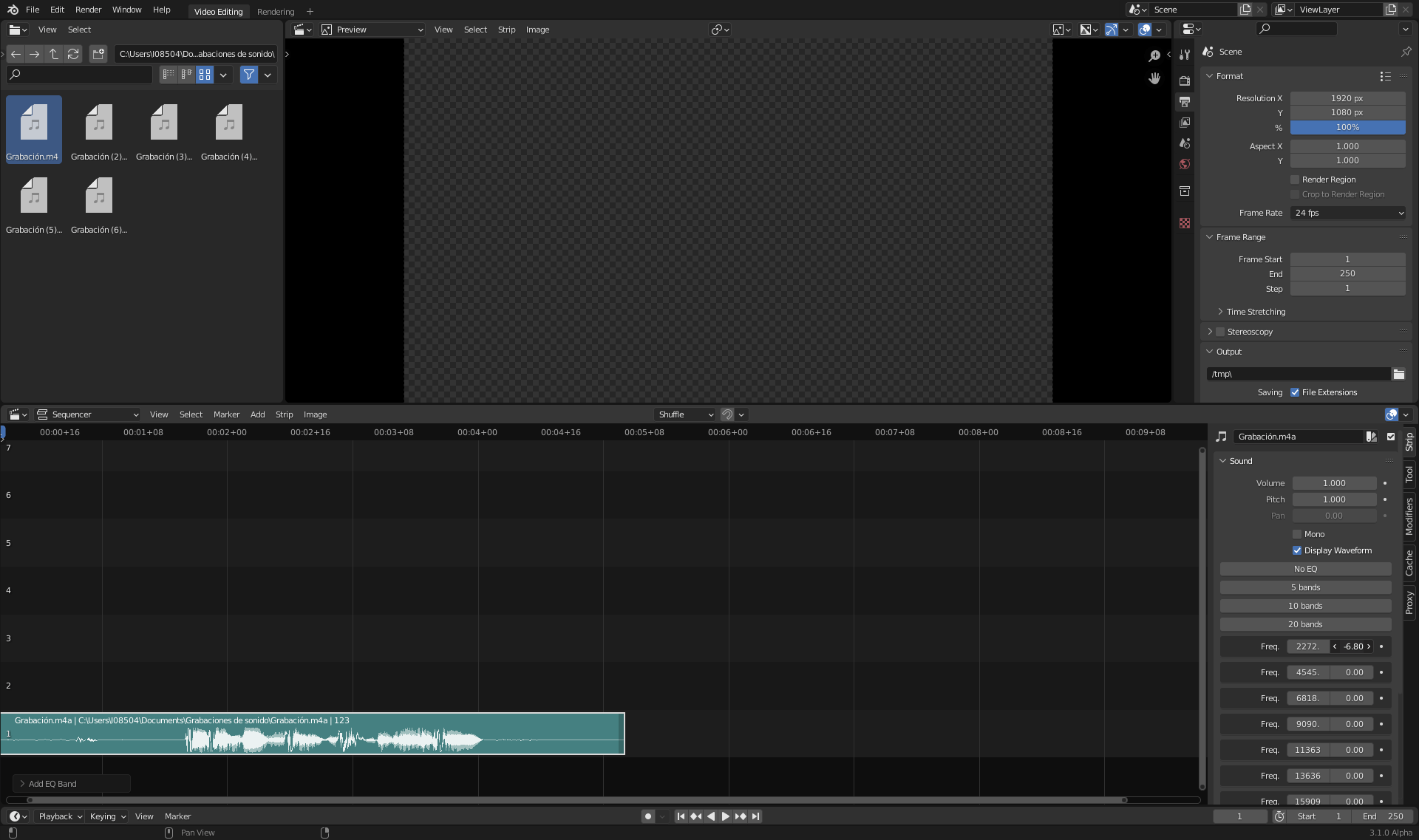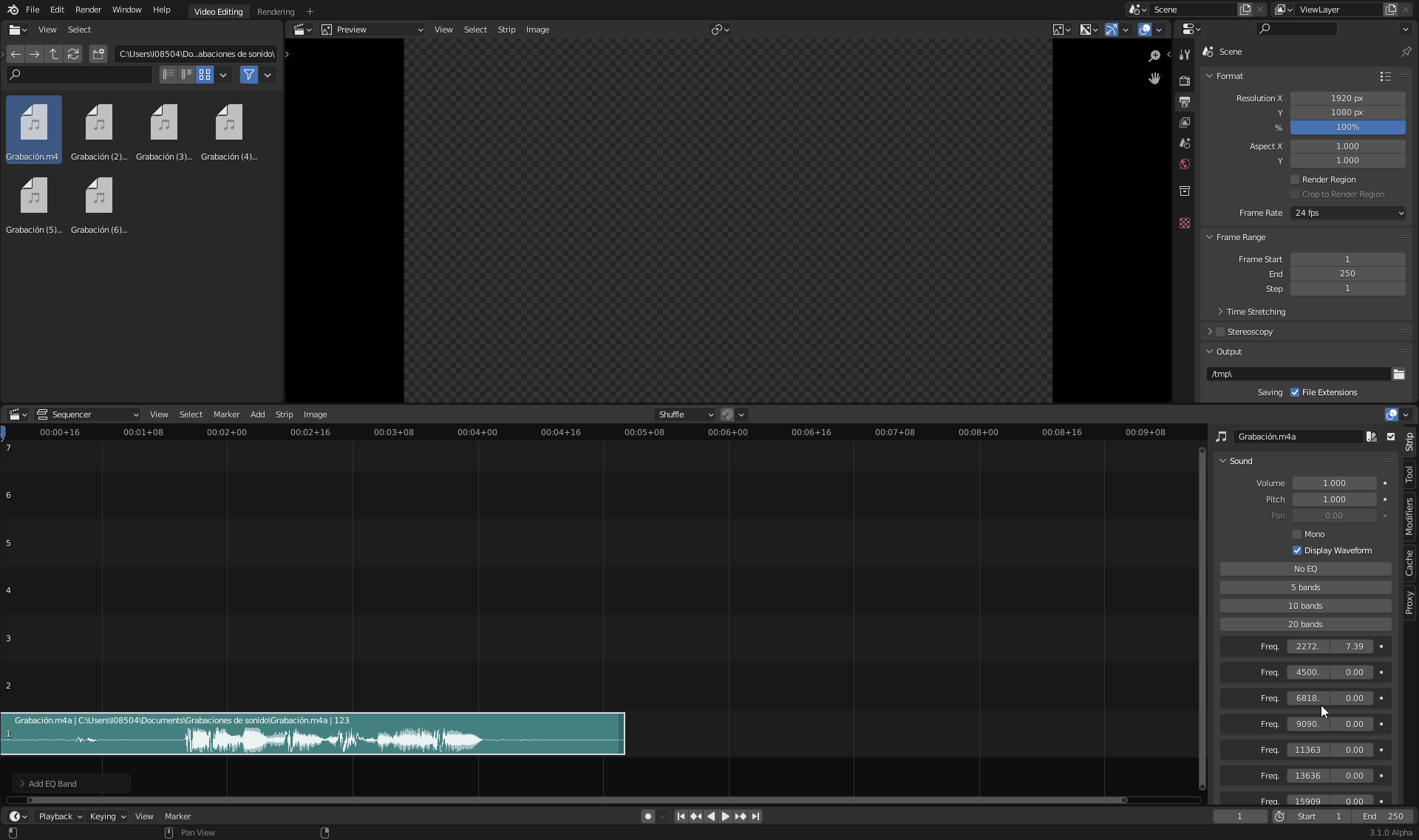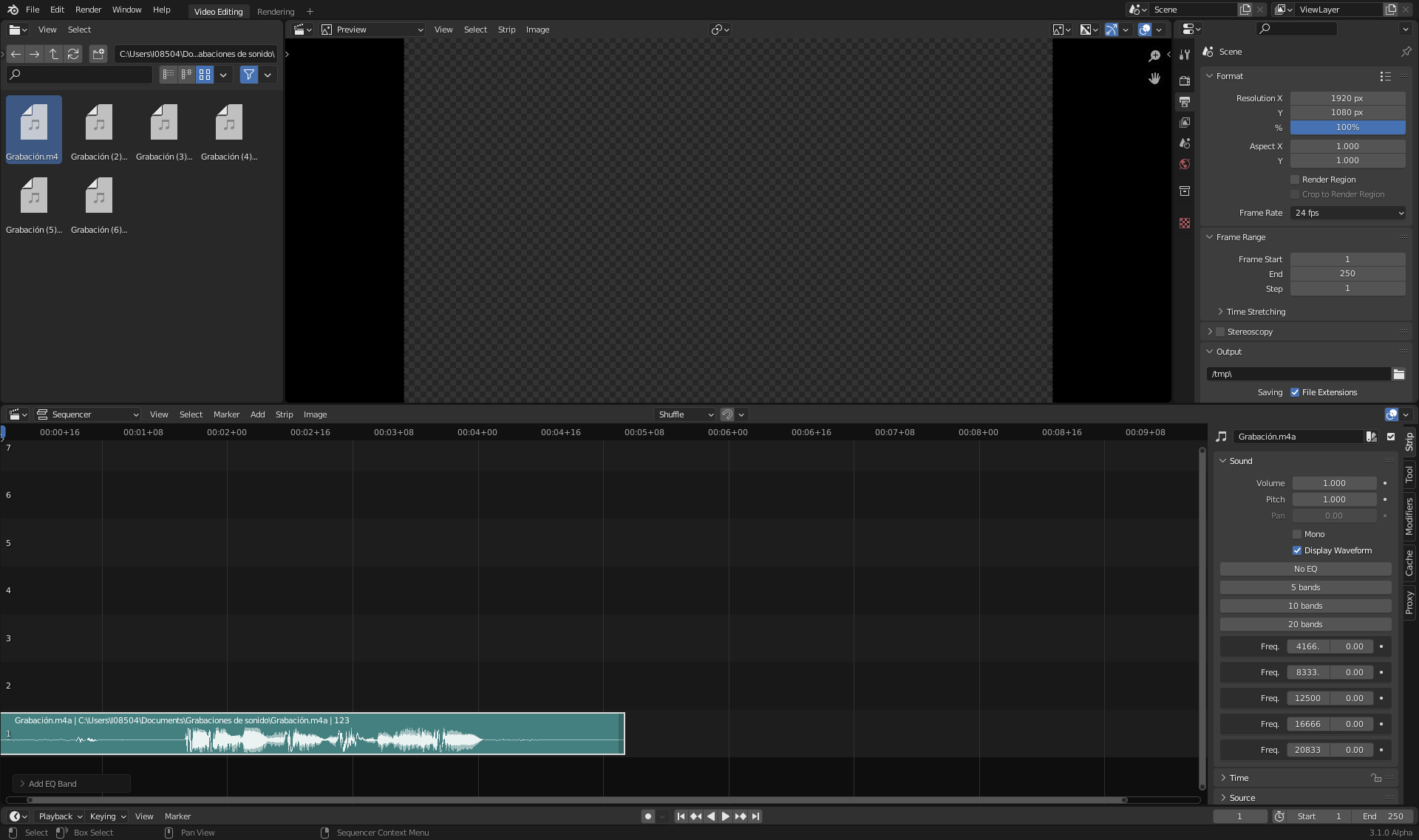
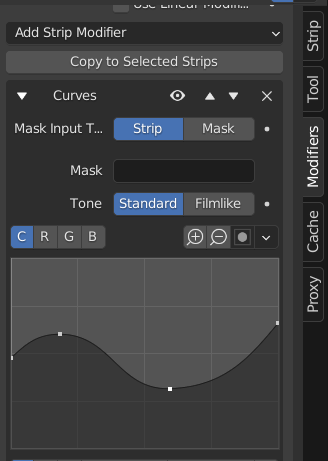
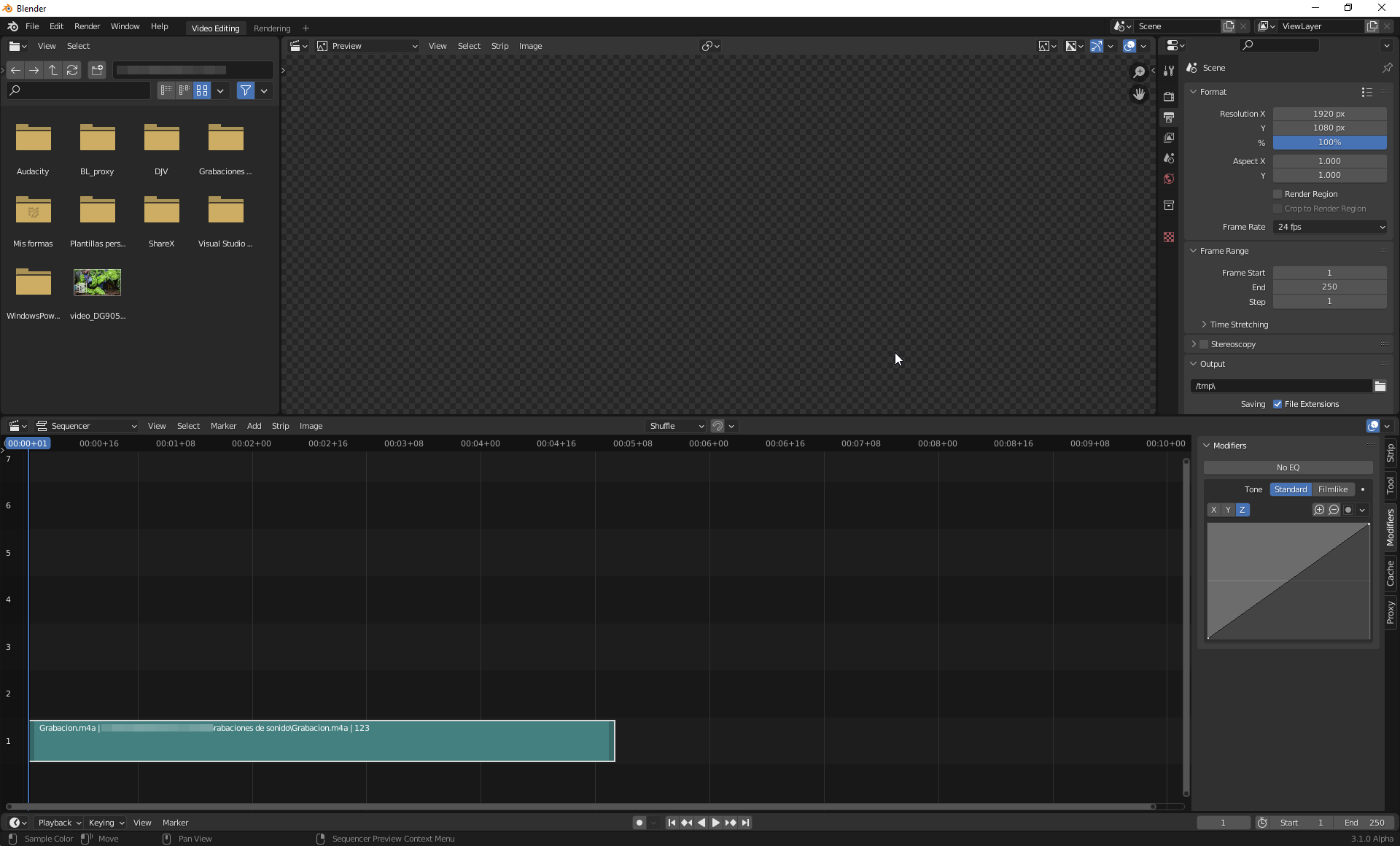
I’ve started developing a parametric equalizer. Now I have done the data model (structs, RNA,…), in order to get an idea of what to get.
As you can see, I’ve started with the idea of different number of bands, and that you can choose some band if you like. I haven’t found any standard about which bands should be created. Audacity uses some bands, VLC uses others,… any suggestion?
Now, I wouldl start implementing the real filter en Audaspace. The real stuff.
Looks interesting. Maybe it’s too early to discuss the UI, but I think the EQ should be a submenu of sound, and the No EQ, 5 bands, etc. should be in an enum. If you want to make a curve for the bands, you should check out the Modifiers. Some of them are using a drawn curve UI.
It seems that Audaspace already comes with some filters not exposed in Blender:
filters like low-/highpass and effects like delay, reverse or fading
Let me know if you want to share a diff, so I can try it out.
You’re right that the UI is ugly. I’ve changed it to a selector. But, the change to a curve I think that it would be difficult for the internal complexity generated for creating a right filter.
Is there any standard in sound equalizer video oriented? In order to create something useful…
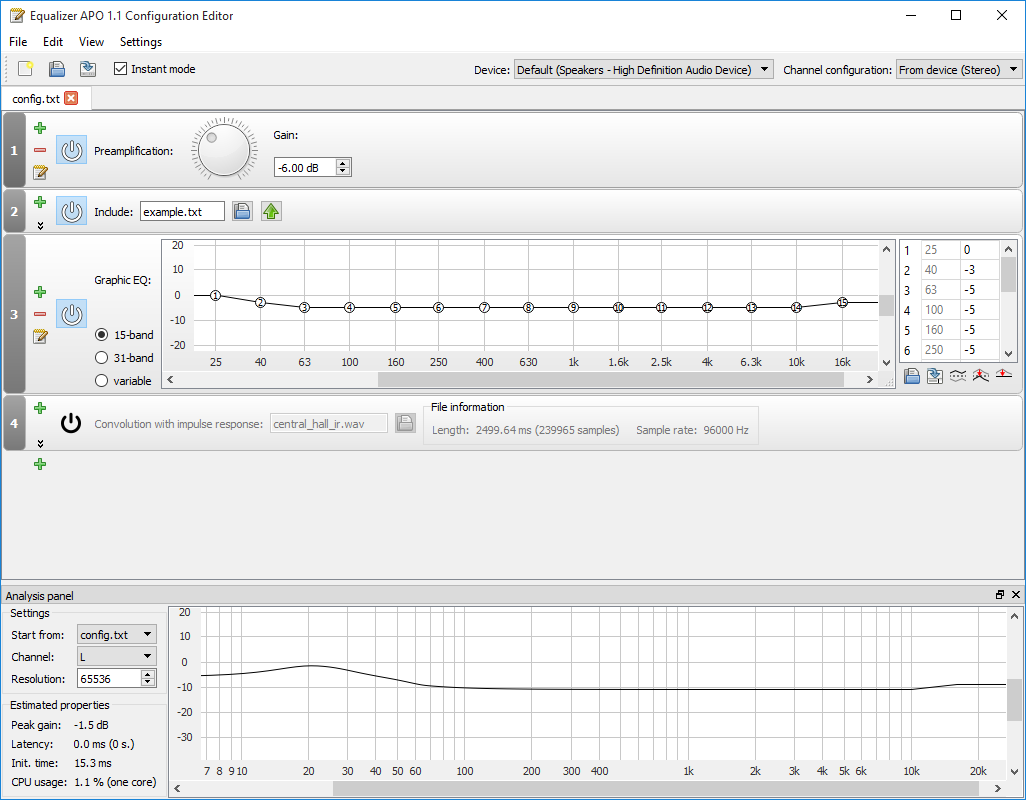
On UI, the main thing for the Blender Devs is that it is consistent with existing UI elements. I haven’t looked up the UI for digital EQs, but I guess they are imitating hardware mixer consoles with vertical potters or using curves. However, Blender does not have vertical value sliders, only horizontal. As for using a curve, this opensource project(devtalk forum only allows linking to non-commercial software as reference), is using curves: Equalizer APO download | SourceForge.net
This is another audio related limitation in Blender:
This could be solved as an import option(checkbox) to split multi-channel audio into separate strips. For surround, it is actually possible pan strips in mono into surround channels though this is a well-hidden feature: https://developer.blender.org/D11933
Or when changing an audio strip into mono, then an enum to select the channel could be visible.