This proposal is intended to provide a unified vision for multiple changes necessary for the introduction of explicit data management in Blender and eventual deprecation of the controversial Fake User workflow.
The Fake User workflow has been a significant pain point for a large portion of the Blender community throughout the entire history of Blender’s existence. Despite this history being over a couple of decades-long, the Fake User workflow has failed to prove itself as a superior, or at least comparable alternative to more conventional data management workflows found in other CG-related software. If anything it’s proven itself to be worse.
My proposal for addressing the entire issue is comprised of four major steps, which are only going to be effective if they are all implemented together, as lack of any of these steps will negate the effectiveness of all the other steps.
- Categorizing datablock types into two categories, Persistent and Expendable, based on user expectations.
- Making changes to the datablock selector UI elements and Renaming the Fake User feature to “Mark as Persistent”.
- Adding “Data Manager” mode to Asset Browser
- (Optionally) Removing dependence of editors on viewport selection
1: Categorizing datablock types into two categories, Persistent and Expendable, based on user expectations:
One of the most important factors in getting this right is acknowledging the existence of such things as common user expectations. They are not a myth. There are many different examples of CG software out there that save some types of data even when the data is not referenced by any aspects of the scene while discarding others. Yet, userbases of these software packages do not seem to be longing for an ability to to manually determine how different types of data is discarded nearly as much as Blender userbase is longing for not having to make this determination manually.
When searching for the source of these expectations, it appears that the categorization of persistent versus expendable data types is mostly based on whether the given data type has its dedicated editor, or whether the data type can be edited only inside the viewport. It appears that whether it is conscious or not, the users generally expect the data, which are editable exclusively in the viewport to be expendable as soon as they are gone from the scene (deleted, not just hidden).
Applying the following logic to the plethora of Blender’s datablock types, we arrive at something like this:
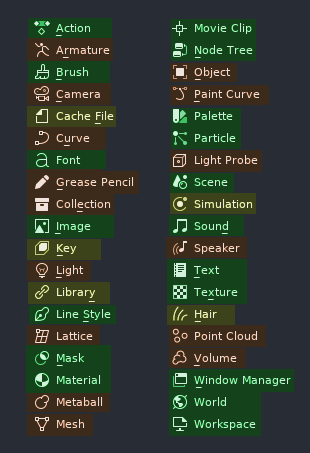
- Marked Green are the datablocks I am fairly certain to have their distinct place for creation and editing.
- Marked Orange are the datablocks I am fairly certain can only be edited/interacted with in a viewport
- Marked Yellow are the datablocks I was not certain about. I could not find for sure if they are the type of datablock someone would want to store for later use.
Since Blender indeed has quite a lot of unique datablocks, while I would suggest generally using the logic above as the reference for categorization, I am not sure it would be wise to do this categorization all at once. I propose to start at the current state of Blender, where all datablocks are considered expendable, and gradually start moving the most obvious candidates into the persistent category. I would start with Materials, Images, Node Trees, Textures, Text, Masks, Palettes, Scenes, Worlds, and Sounds.
Datablocks present in the “Persistent” category would never be automatically discarded by Blender.
2: Making changes to the datablock selector UI elements and Renaming the Fake User feature to “Mark as Persistent”.
I will be using the material datablock selector UI element as an example below since losing materials seems to be by far the most common example of fake user workflow shortcomings. But I expect the equivalent changes to be applied to all datablocks. (For example, renaming “New Material” to “Duplicate Material” would be handled by an equivalent change in the node editor, not renamed literally the same).
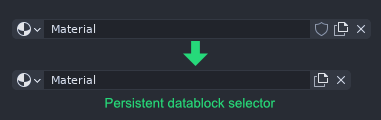
A: The fake user button would be removed from any Persistent datablock selector UI elements:
The Persistent datablocks will always be saved, no matter what. There must be no element present in the UI, which could cast any doubt on this holy rule:
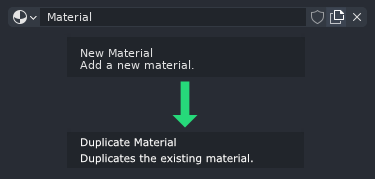
B: The “New Material” button would be renamed to the “Duplicate Material” button:
Since the premise of this proposal is that users will now be explicitly in charge of the data management, we need to make any data-related operators as clear as possible. We can not lie to users by labeling a feature such that it implies the creation of the new datablock with default data, when what it actually does is make a copy of the currently selected datablock with all its modified data.
C: The “Unlink data-block” would be renamed to “Clear data-block slot”:
At the first glance, this may sound like a synonym. One could argue that the meaning does not change. The issue here is that the “Unlink” word carries a bit of scene data dependency connotation, and idea of breaking the link therefore implies some modifications to the scene dependency structure. This connotation is valid in most of the areas where Blender uses datablock selector UI, but not in all of them. A good example of where it can introduce a bit of uncertainty is the Image Editor:
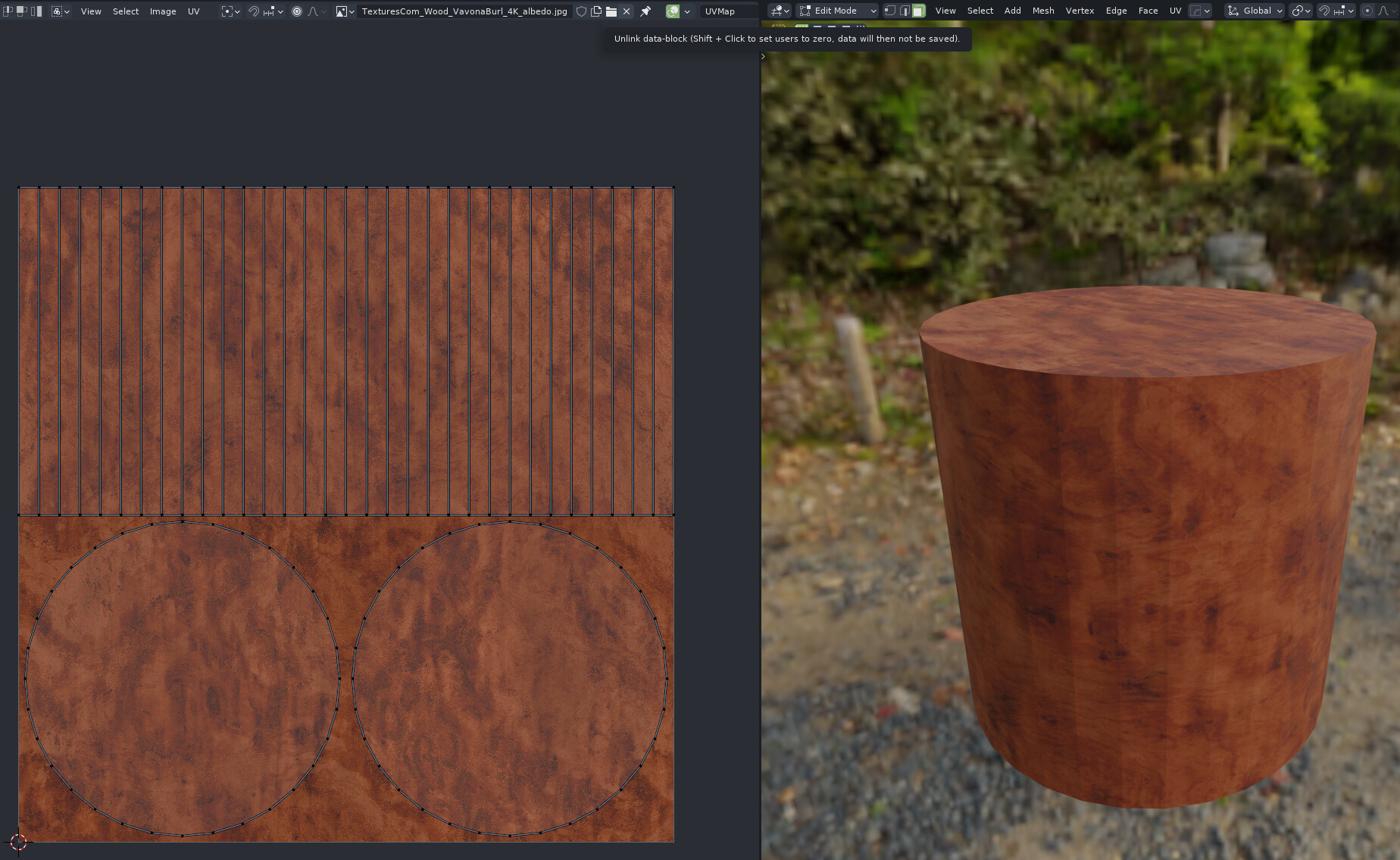
When user gets into a situation of UV mapping a textured object, it’s not often uncommon requirement to temporarily disable display of the texture in the UV editor, especially if the texture has strong visual features, making the topology of the UV map hard to see. At this point, if the texture displayed in the UV editor is the same as the texture on the 3D object itself, the wording “Unlink” can introduce a degree of uncertainty of the result of the action.
It’s not immediately clear if clicking the button will affect just the UV editor viewport display, or break some data link on the object itself, such as unlinking texture from the material. The user’s uncertainty is justified, since in case of the Shader Editor, that’s what the button would do.
Renaming the operator to “Clear data-block slot” would make the description of the operator still valid in cases where actual data links between the scene data blocks are broken, but would make the operator less worrisomely ambiguous in cases where what’s being broken is just a link between the datablock and the editor editing it.
This leaves us with the elephant in the room. Two options, both having pros and cons. It would be up to the community which outcome they prefer:
D1: The Fake User button would be kept on any Expendable datablock selector UI elements, and renamed to “Mark as Persistent”:
The naming of the Fake User feature itself has always been at the center of the Fake User workflow controversy. It was confusing to new users unfamiliar with the Blender jargon, and in such a critical area as data management and possible data loss, confusing nomenclature just can not be excused.
Since this proposal introduces self explanatory concepts of Persistent and Expendable datablock types, functionality of which can be inferred by the naming itself, renaming the “Fake User” function to “Mark as Persistent” would alleviate one of the main pain points.
Pros:
- Users could choose to keep around certain Expendable datablocks, which aren’t generally excepted to be kept around, such as mesh. You could have the flexibility of keeping a mesh in your .blend file without the mesh being used by any object present in the 3D scene.
Cons: - It’s a partial defeat and makes the whole solution less elegant. If Camera and Light datablock types was moved from Expendable to Persistent category, we would have “Mark as Persistent” button on all expendable datablocks while it would probably really make sense to use it only on meshes and only in very rare, creative scenarios.
D2: The Fake User button would be removed altogether:
Going with the “If it can only exist and be edited in the 3D scene, not another editor, and is not present in the 3D scene, it should be discarded” philosophy would allow to remove the Fake User button completely.
Pros:
- Very clean and elegant solution. The users are freed from the chore of explicitly marking the data blocks they don’t want to be discarded.
Cons: - You can not choose mesh datablocks to not be discarded.
- Controversial in terms of datablocks like Camera or Light. If we deem Cameras and Lights to be Persistent datablocks, then users will have cleanup duty to manually, explicitly delete Light and Camera datablocks created by lights and cameras which were created in the scene at any point in time. If we deem Cameras and Lights to be Expendable datablocks, the users will lose the ability to store Light or Camera properties without having Lights or Cameras present somewhere in the 3D scene.
3: Adding “Data Manager” mode to Asset Browser:
While thanks to the concept of Persistent datablock types, users no longer need to anxiously worry about most of the datablock types they create in Blender disappearing because they forget to explicitly click a button, they now also receive a new duty of cleaning up these Persistent data blocks themselves.
Right now, with the tools Blender has available in its current state, this duty would more often than not feel like a frustrating chore, and perhaps even a step back for some of the users who have learned to utilize the burden of Fake User workflow to their advantage. Only tool Blender currently has for explicit datablock management is the “Blender File” mode of the Outliner editor. This tool is insufficient as a means for effective explicit datablock management.
Thankfully, in recent versions, Blender has introduced Asset Browser, which provides a solid basis for extending it into an effective solution for creation, management, editing and deletion of Persistent datablocks.
Asset Browser would gain “Data Manager” mode:
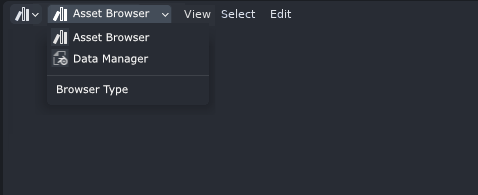
In the Data Manager mode, user would not have any option to change or rename the folder structure of the datablocks. In the similar way to how Blender uses predefined folder structure when appending datablocks from other .blend files:

…the Data Manager mode would simply display a list of all the Persistent datablock types on the left sidebar:
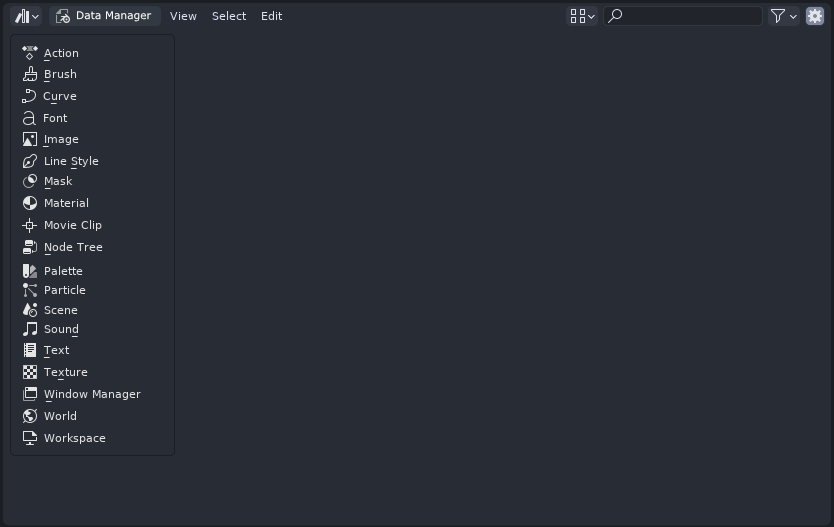
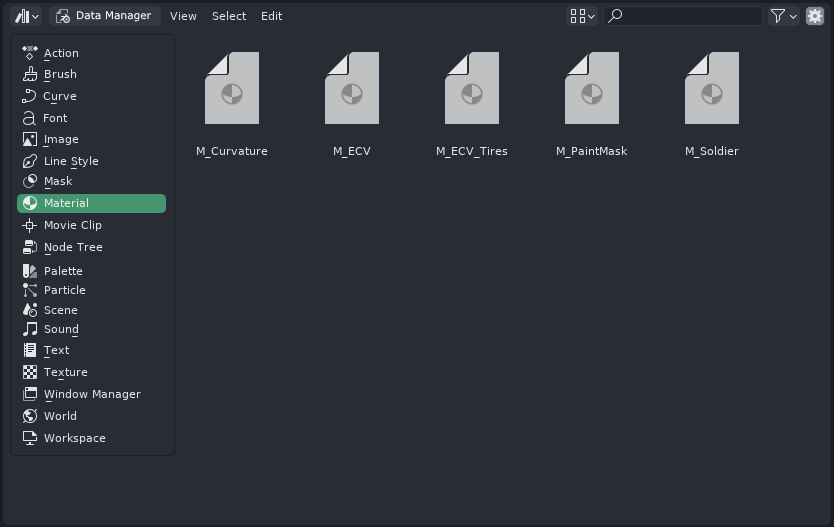
Upon selection of any of the datablock type on the left sidebar, the Data Manager simply lists all the datablocks of the given type stored in the file:
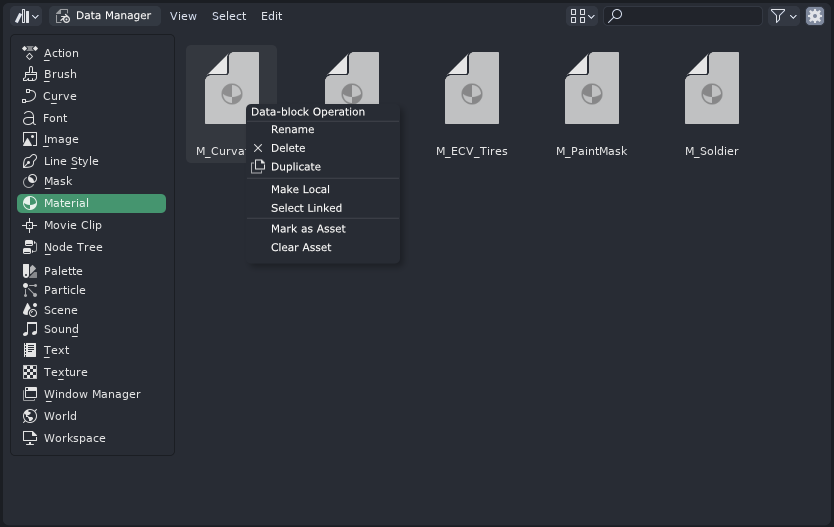
Right clicking selected datablock(s) would present user with convenient context menu crafted for most common datablock management operations:
Right clicking empty area in any datablock type will present user with an option to create new datablock of given type:
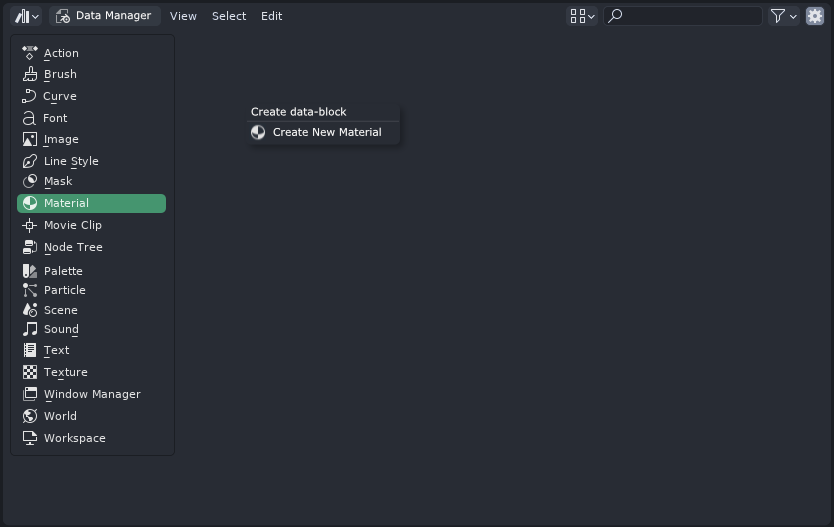
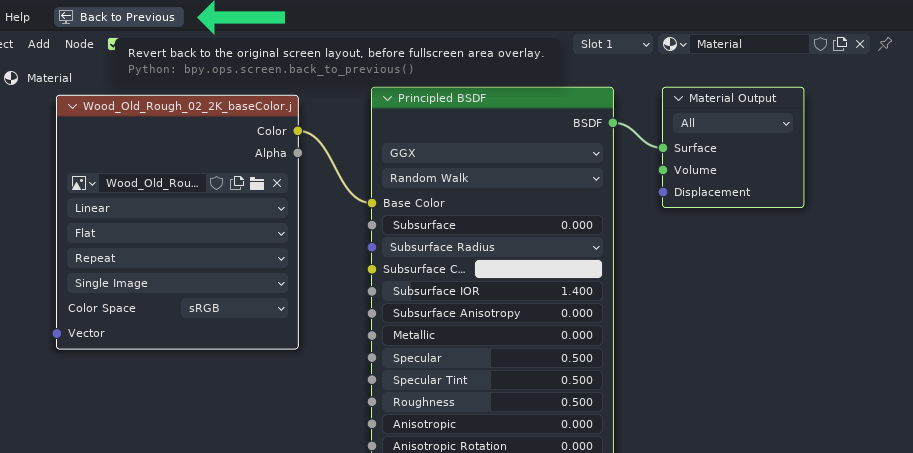
Blender has a great “Maximized View” overlay functionality, which can open any editor in a temporary for overlaying everything with a quick “Back to Previous” button, which closes the overlaid editor and returns user back to his workspace. This can be utilized perfectly here. Double clicking any datablock in the Data Manager window would open the double-clicked datablock in an overlay editor, giving the user ability to view/edit it immediately. For example double clicking the material would immediately open it in a overlay editor with a quick way to exit it:
Double clicking most of other datablock types would open them in their appropriate editors, if they have any, for example:
Action->Action Editor
Image->Image Editor
Mask->Image Editor
Material->Shader Editor
Geometry Nodes->Geometry Nodes Editor
Text->Text Editor
etc…
Lastly, of course, we still need to make the actual clean up of the unused data easy for the user. For this purpose, I will take a liberty of expanding on the idea by Harley Acheson: ⚙ D14030 UI WIP: User-Managed Unused Data
The Data Manager would get a single button, functionally similar to “Clean Up Recursive Unused Datablocks” operator.
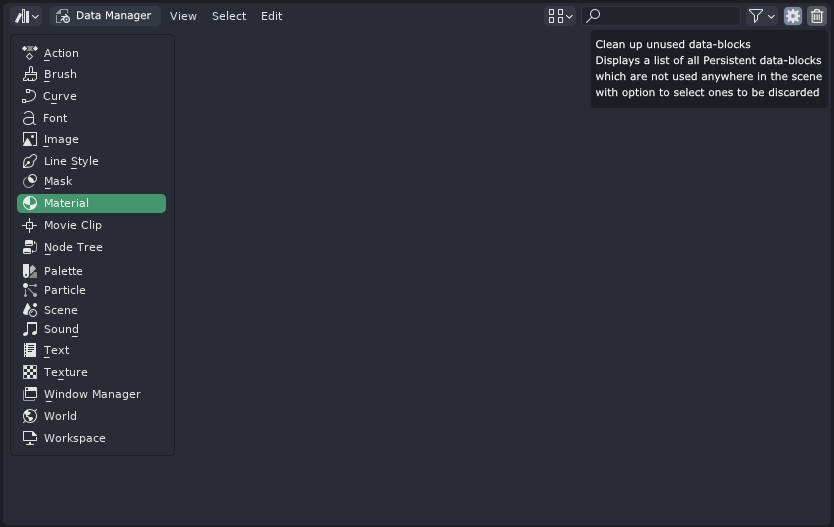
Once clicked, it will spawn a pop up window listing all the Persistent datablocks without any users in the scene with checkboxes, allowing the user to determine which ones to keep and which ones will be discarded:
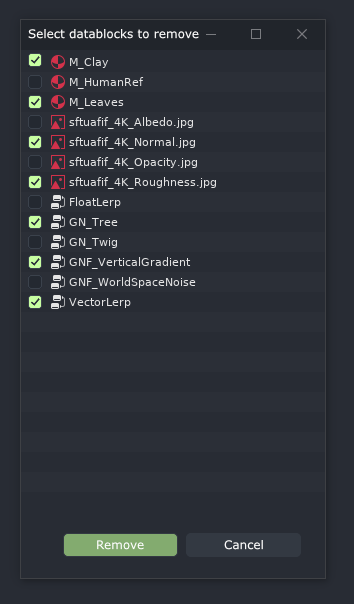
This new cleanup operator with the confirmation list of datablocks to be removed would also replace both Clean Up → Unused data-blocks and Recursive unused data-blocks in the File menu. Therefore, it would be accessible both from the File menu as well as Data Manager.
So when it comes to managing accumulation of the Persistent datablocks in the scene, all it takes now is to open the Data Manager from time to time, click a single button, review all the datablocks to be removed, uncheck those user wants to keep, and click remove. Unlike the current cleanup operator, you will actually know what you will be removing before it happens, which is quite important.
The last thing on the table for the Data Manager proposal are D1 and D2 options from the step #2. If it was decided to go with D1 option, and keeping the ability to Mark Expendable datablocks as Persistent, the Data Manager would also have to show the categories for Expendable datablocks on the left sidebar. In this case, I would propose to show Expendable datablock types only if the given Expendable datablock category contains at least 1 existing Expendable datablock which has “Mark as Persistent” flag enabled.
4: (Optionally) Removing dependence of editors on viewport selection:
The convenient ability to just double click any datablock in the Data Manager and having it immediately opened in the appropriate editor in overlay mode is currently a bit tricky to do, because for the most part, Blender ties editing of the certain datablocks to viewport selection. There is a pin button in the Shader, Geometry Nodes and Image editor, allowing to temporarily decouple the contents of the editor from the active viewport object, but it’s very limited and insufficient.
I will be using Shader Editor in this example, but these changes would once again apply to all the editors working in the similar manner.
Current way things work in regards to editing datablocks cause multiple issues:
- It’s not possible to edit unassigned material. If you want to edit material which is currently not assigned to anything, you have to create a new temporary object, such as cube, assign the material to it, edit it, and delete the temporary cube. The pin button does not suffice here as while the editor is in the pin mode, it does not allow you to change which material is being selected.
- In the similar manner, if you want to edit material which is used in the scene, but object can not be selected, because it has disabled selectability, for scene management purposes, you need to temporarily make the object selectable just to edit its material. That should not be necessary.
- In a quite unexpected and confusing manner, the datablock selector in some of the editors, such as Shader Editor, is actually an instance of the active slot on the selected viewport object. While common sense would assume this datablock selector works in the same way as it does in the image editor (it select the data block the editor is currently editing), in Shader Editor the datablock actually changes the material assigned to the given slot on the mesh. This often leads to a lot of frustration from both new as well as experienced users. It’s very difficult to get used to due to this behavior changing between different editors in the very same software.
I propose a new paradigm: Changes in the datablock editors, such as shader editor, should only be able to change the state of the datablock they are editing, not the parent objects which utilize the edited datablock.
Here’s how it will work in practice:
The default mode of the Shader Editor gets rid of the Slot selector and Pin button:
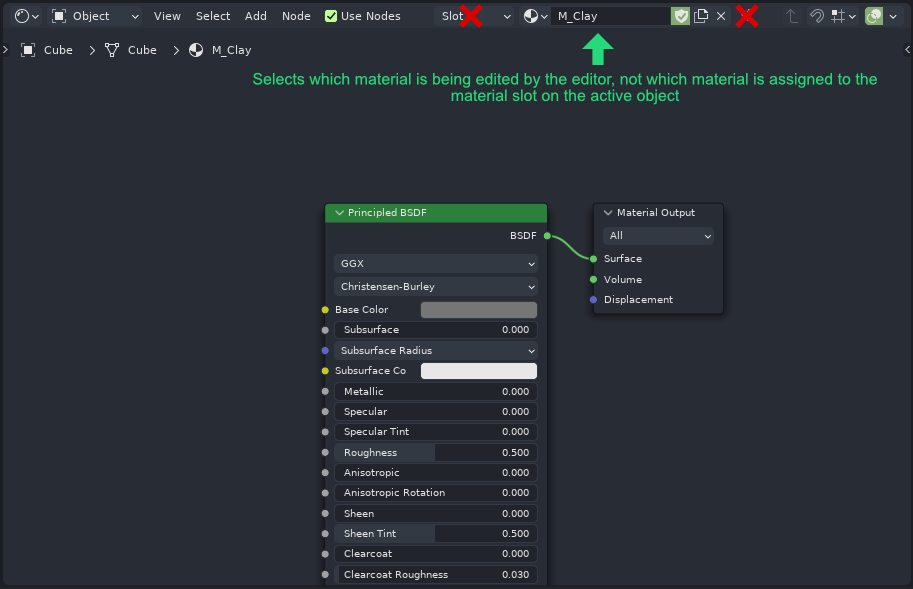
…and the datablock selector in the shader editor will no longer be affecting which material is assigned in the active material slot on the active object in the viewport. Instead, the datablock selector will be selecting the material which is currently being edited, in the same way Image Editor datablock selector does.
This allows users to edit any material at any time, without need to create temporary objects to put unused materials on before editing. It also reduces the issues where user accidentally changes the material assigned on the object by intending to just edit another material.
However, this does not mean that the idea of synchronization between the active objects and the editor is wrong. It was just executed wrong, and it can be done better:
In place of the Pin button, the Shader Editor will gain synchronize button, similarly to the one which can already be found in the UV Editor:

When this button is activated, the material currently edited by editor is synchronized with the material in the active slot of the active object. This is similar to current behavior, but has some key differences:
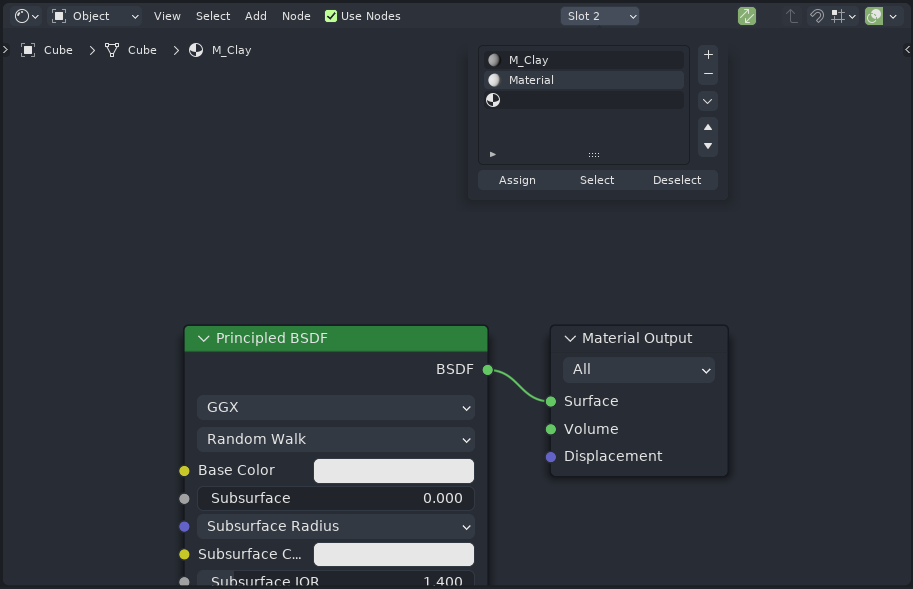
- When the sync mode is activated, the datablock selector is gone. What determines which material is edited is now the active material slot of the active object. So users can no longer accidentally change the material on their object. Assignment of the materials should not be done by the datablock editor, but by the object editor (properties panel).
- In the sync mode, the datablock selector is replaced by the Slot selector, which was removed from the “main” mode. This means that users using the sync mode can still change which of the materials assigned on the active object they are editing, even if they currently do not have the material tab of the properties editor available in their workspace, and do not need to leave the editor area to do so.
I believe this can give us the best of the both worlds. We can gain the ability to easily edit any datablock we want, regardless of what’s selected in the viewport. At the same time, we can still enjoy the benefits of the synchronization between the editor and active viewport objects, while eliminating the confusing and inconsistent behavior of some editors having ability to modify datablock assignments.
5: Stretch Goals:
Ability to drag and drop datablocks directly from the Data Manager onto compatible datablock selectors across the UI would be nice 
If you managed to get through this entire wall of text, you have my admiration Thank you for reading.