This proposal explores one option for the future of explicitly named attributes in geometry nodes. It is part of T90864.
Background
In the fields proposal the need for typing explicit attribute names is significantly reduced compared to what we have in master. However, explicit attribute names are still required for interoperability with different systems.
- Access attributes that are available on the original geometry (e.g. vertex groups and uv maps).
- Access attributes on “external” geometries (e.g. other objects or geometries imported from files).
- Make attributes available for other systems (e.g. other objects, render engines or external software)
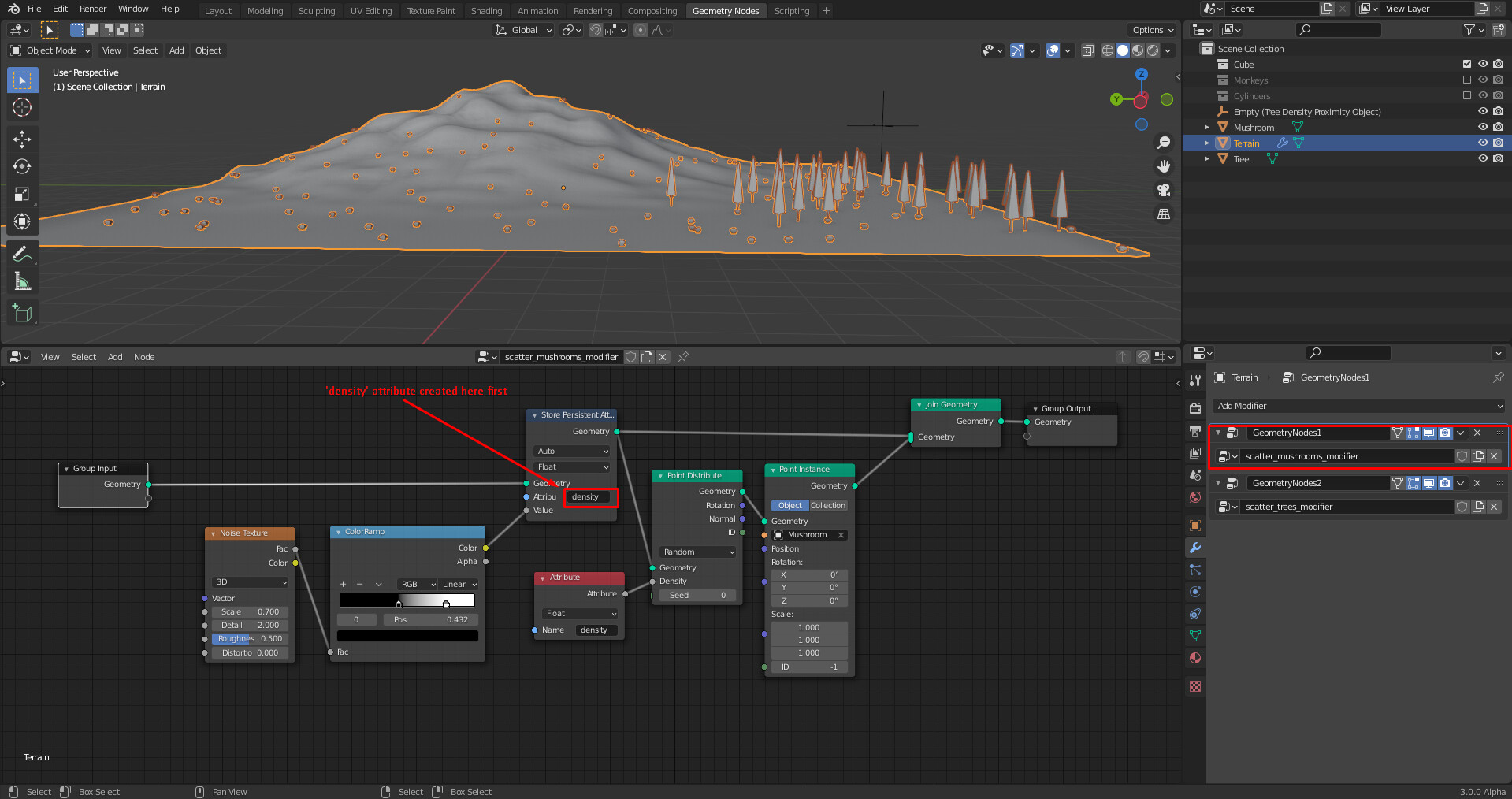
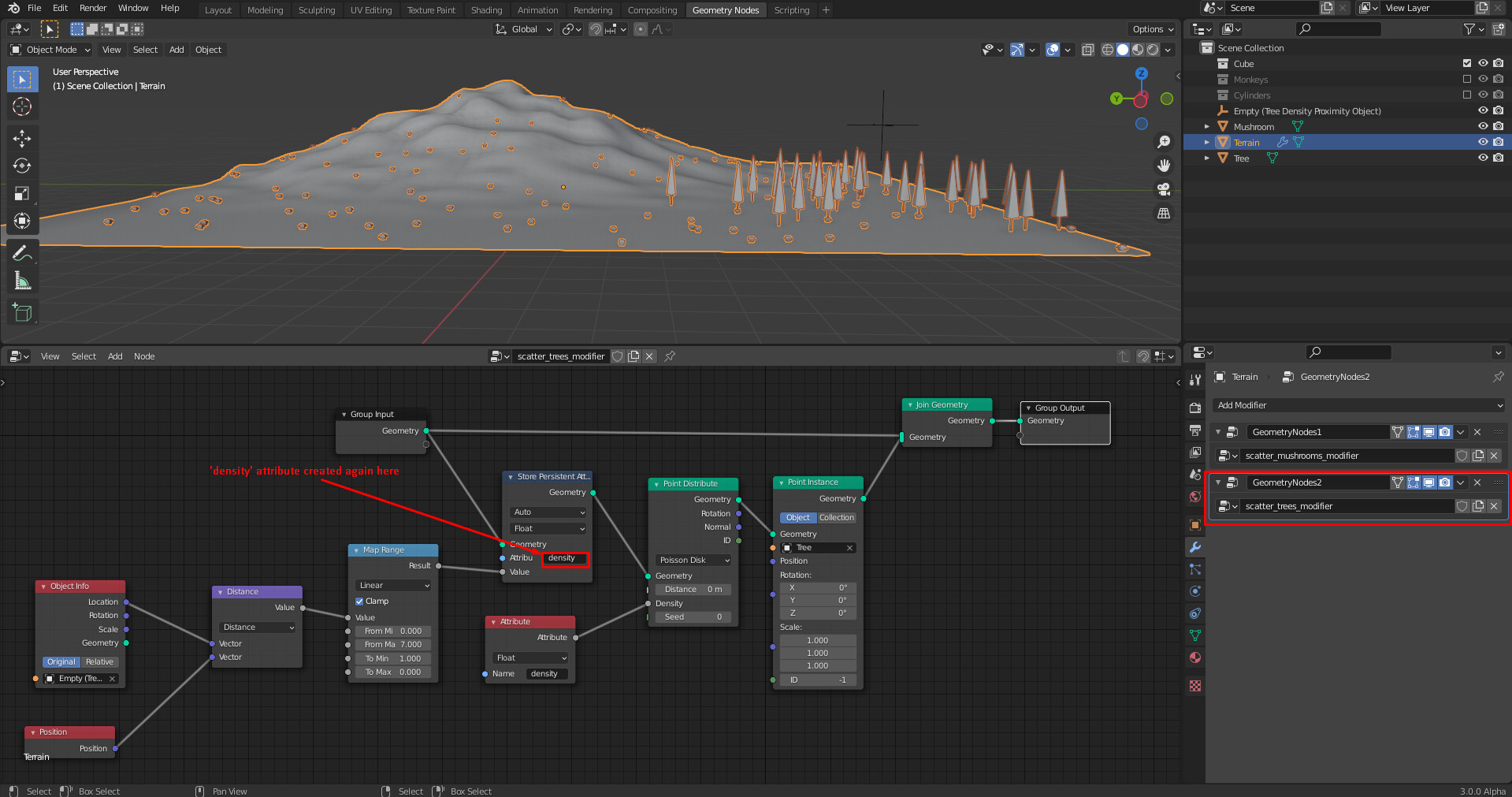
The main question is: Where should users specify attribute names? For reference, in Blender 2.93 attribute names had to be specified in many nodes. In the current fields prototype, one would mainly access named attributes with the Attribute and Store Persistent Attribute node (which have a string input). In both cases, attribute names could be specified everywhere in geometry nodes.
A Different Answer
This proposal has a different answer to the question: Attribute names should only be specified where geometry enters geometry nodes and where it exits geometry nodes.
The main advantage of not allowing nodes to access named attributes everywhere is that node groups become easier to compose. One does not have to fear name collisions inside of geometry nodes.
Geometry can enter geometry nodes in a few places:
- Geometry that is passed in by a modifier.
- Object Info node.
- Collection Info node.
- Nodes that read a geometry from a files (in the future).
Currently, geometry only exits geometry nodes only through the modifier. In the future we might be able to write geometries to a file on disk with a node.
Implications
This different approach to attribute names has a few implications for the design of geometry nodes.
Object/Collection Info
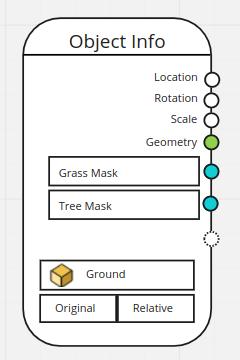
The Object Info and Collection Info import new geometry into geometry nodes. Therefore, both nodes also have to allow the user to specify attribute names. Besides the already existing outputs, users have to be able to dynamically add field outputs. Each of these outputs would have an editable attribute name and socket type.
Object/Collection Socket
The object/collection input sockets in these nodes have to be removed as well. They allowed separating the place where the geometry source is specified from where the attribute names are defined. Instead, the nodes get an object/collection input directly in the node, without a socket.
Exposing Objects and Collections
Obviously, now we’ve lost the ability to expose the object to the parent node group or modifier. So that functionality has to be added back. This can be done by adding an “Expose” operator to the Info nodes. Executing this operator would do a few things:
- Copy the Info node right before every Group node that calls the current node group.
- Create a new group input for every output of the Info node that is used.
- Remove the Info node from the current node group.
- Link the newly created sockets in all modified node groups.
- If the node group was used by a modifier, also update the modifier inputs accordingly. More about that below.
Note, the current node group will not have an object input, it will have a geometry input instead. The conversion from object to geometry happens one level higher now.
Point Instance
Besides the Info nodes, the Point Instance node is the only one that also uses object and collection sockets. Since those sockets are removed, the node has to get a second geometry input instead. One geometry determines where to instance and one determines what to instance.
Just this change would not be enough to get all functionality back though. What is missing is the ability to instance a different geometry on every point. Fortunately, there is a rather nice solution to that, which would also solve an additional problem. The solution is to allow instancing the instances in the second geometry separately.
The nice benefit of this solution is that instances in a geometry are actually ordered properly and therefore they can be identified by an index. Objects and sub-collections inside a collection do not have a well defined order that this node could depend on. Note, the separate ID input is still necessary, but maybe it should be renamed to “Stable ID”. It’s important for proper motion blur etc.
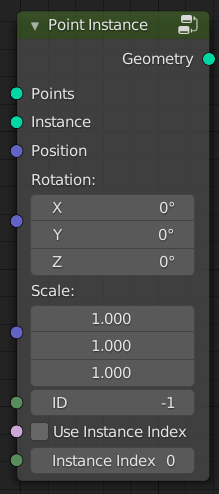
Both the “Use Instance Index” and “Instance Index” inputs can also be fields. Instead of having two separate inputs, one could also say that an instance index of -1 means that the entire geometry should be instanced (which would be the default then).
In order to use this, the collection info node should have a new boolean input that specifies whether the collection becomes a single instance in the output geometry, or whether all sub-elements in the collection should become their own instance.
Modifier
The modifier ui has to become a bit more complex/flexible as well.
- Every time one had exposed an object to the modifier before, one now has to expose a geometry socket. Therefore, the modifier has to be able to provide multiple geometries to the node group. Furthermore, one would have to choose between original/relative in the modifier (same as in the Info nodes).
- Also it has to be possible to pass the position of another object to the modifier. Again, either in original or relative space.
- The modifier is a place where geometry enters and exits geometry nodes. So one also has to be able to specify attribute names for inputs and outputs in the modifier.
Evaluation
As can be seen, it is possible to only specify attribute names where geometry enters and exits geometry nodes. This design would make attribute name collisions practically impossible and therefore forces users to create node groups that are more reuseable and composable.
There are also some downsides to this approach, because it does add a new limitation to enforce the guarantee mentioned above.
- Doing versioning for geometry nodes node groups created in Blender 2.93 becomes significantly harder and maybe impossible to do well. We could add some special nodes that deal with named attributes, that can only be added by versioning code and not by users. However, these nodes break the guarantee, even if they are just created by versioning code.
- This proposal might lead to more attribute name duplication in a .blend file, because the same attribute name might have to be specified in multiple modifiers instead of once in a node group. I makes assumptions about where it makes sense to specify attribute names that might not be correct for all use cases.
- Exposing objects and collections to the parent node group becomes different from exposing other data.
- It becomes impossible to remove named attributes in geometry, which might be important for optimization purposes (since all named attributes on a geometry are propagated in most nodes).
I should note that we can get the nice aspects of this proposal (except for the guarantee that no node group will use hardcoded attribute names on geometry passed in from somewhere else), without any of the downsides. It is possible to statically analyze a node group to see if it uses nodes that might lead to attribute name collisions. We could somehow show in the ui when a specific node group is guaranteed not to use hardcoded attribute names (i.e. it is “side effect free” in some sense).