Sample Sound Node
Name
Mangal Kushwah
Contact
Blender-chat: Mangal-Kushwah
Github: Link2324 (Mangal Kushwah) · GitHub
Twitter: @MangalK14
LinkedIn: https://www.linkedin.com/in/mangalk/
Synopsis
This project will add a Sample Sound Node, which will retrieve the volume data within a specific frequency range from the sound file at specific points in time.
With sample sound nodes artists will be able to create sound-driven animations, advanced spectral effects and more.
Benefits
- With this node, artists will not have to rely on external third party tools for sound related operations.
- It’ll pave the way for more future sound nodes in geometry nodes.
- With Sample Sound Node, creators will be able to manipulate animations using sound data enabling new animation, visualization and interaction possibilities within blender.
Deliverables
- Implement Audio Input node
- Implement optimized Sample Sound Node
- Implement More Sound nodes (After Discussing with mentors)
- End user and technical documentation and examples
Project Details
Mockups:
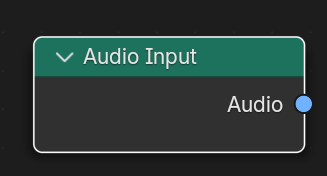
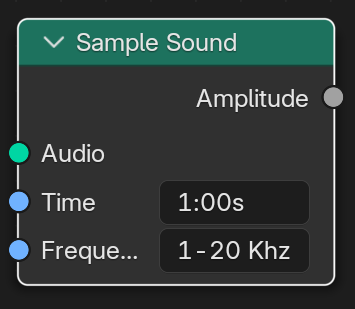
These mockups uses wrong sockets, this is just for visualization of node input/output final nodes will be much different from these
Audio Input:
Use audaspace for file reading, Since audaspace is already integrated in the blender build system so no external dependencies will be required.
All the necessary things for reading sound files are already in the BKE_sound.h header.
FFT Analysis:
For FFT audaspace have FFTPlan class which uses fftw, if more flexibility is required during development then FFTPlan could be modified or fftw can be directly used for FFT which is also included in blender dependencies.
Frequency Bin Selection: Provide controls to isolate specific frequency ranges (low, mid, high) or allow custom bin definition.
Caching and Optimization:
Frame-Based Sampling: Sample audio at specific frames, caching results for subsequent frames if the sound or animation has not changed.
Precomputed Analysis: Investigate if pre-calculated audio analysis can be loaded, especially for longer sounds.
Challenges:
- Performance: FFT-based analysis can be computationally expensive. Optimizations, caching, and potential multithreading will be vital.
Project Schedule
I don’t have any commitments. I have a keen interest in this project and I will be working on it throughout the summer. I will be giving an average of 4-6 hrs per day and during weekends if required will crank it up to 8 hrs easily. The total commitment time for each week will be around 35 hrs roughly.
Week 1 - 2:
- Sync with mentors to align on deliverables.
- Implement Input Audio Node (Deliverable 1)
Week 3 - 4:
- Implement Sample Sound Node (Deliverable 2)
Week 5:
- Sync with mentors on Deliverable 1 and 2
- Deliver a testable work-in-progress for people to try and give some early feedback or area of optimisations.
Week 6:
- Buffer time to accomodate any remaining tasks, additional issues that need to be addressed.
- Work on mid term evaluation
Week 7:
- Optimize Sample Sound Node (Deliverable 2)
Week 8 - 9 - 10:
- Deliver polished Sound Nodes for people to try and give feedback.
- Sync with mentors for discussing the issues and feedback
- Implement More Sound Node (Deliverable 3)
Week 11 - 12:
- Work on End users and technical documentation. (Deliverable 4)
- Work on final evaluation|
I have tried to give a rough estimate as the final timeline can be decided after discussion and finalising of the implementation.
Bio
I am Mangal Kushwah, currently in my final semester of Bachelors in Electronics and Communications Engineering from Madhav Institute of Technology (MITS), Gwalior, India.
I’ve experience in signal processing and FFT through my university courses.
I previously have used the fftw library for FFT in implementation of image processing related research papers.
I’m an open source enthusiast. And have a solid understanding of C, Java and Python. I also love mathematics.
While I learned C++ recently but i’ve excellent understanding of the OOP concept through Java.
I am currently spending my time contributing to opensource projects and learning more about compilers, computer graphics, Image processing and web development.
Below is a list of my contributions to Blender:
- Fix operators that affect hidden geometry
- Python API: ViewLayer.aovs.remove isn’t available (Partial) - 2 years ago
- Small Typo Fixes in Docs