For cache size, a size_in_bytes_approximate() method would be added to the GeometryComponent base class which will be implemented by on the sub-classes and another similar method added to GeometrySet would aggregate the size of all added components on the geometry set.
A default cache size (let’s say 250mb, this would be configurable and the default value could be user system dependant) would drive the eviction policy in the LRU cache.
Some of these things can be manipulated by chaining nodes after the import node (e.g scale) but somethings might need to be passed to the importer like collection separator.
In a perfect world I wish some geometry nodes could have toggled dropdowns like in the principled shader, but until then for this many options maybe just the N panel would suffice, thought it might feel hidden. I think people will want these nodes small
PLY import node could serve as the basis of a 3DGS renderer but to get acceptable performance (for large scenes) you would need GPU based sorting. I am not sure if there is anyway as of now to run compute shaders in geometry nodes.
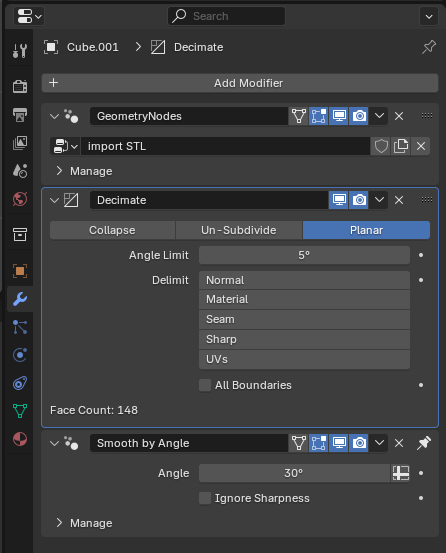
when importing STL files it is always preferrable to use limited dissolve on the mesh or using a decimate modifier, do you think it would be possible to add “limited dissolve” operation to the import STL node?
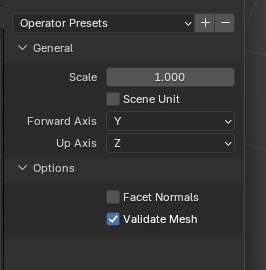
additionally, is it also possible to include the STL import settings as shown below
for example, I genereated this gear model, exported from Blender as STL, then used the import STL node to import it back. You can see that the important mesh is triangulated, and the shading is wrong.
Any such features have to be user-made node groups, all such import nodes should not do any additional work like change space coordinated or clear topology.
I have been thinking about this for a while, I think it’s about time I get started. sharing a rough outline on how this node would function, for the first implementation I’ll be keeping it simple.
Output of the node
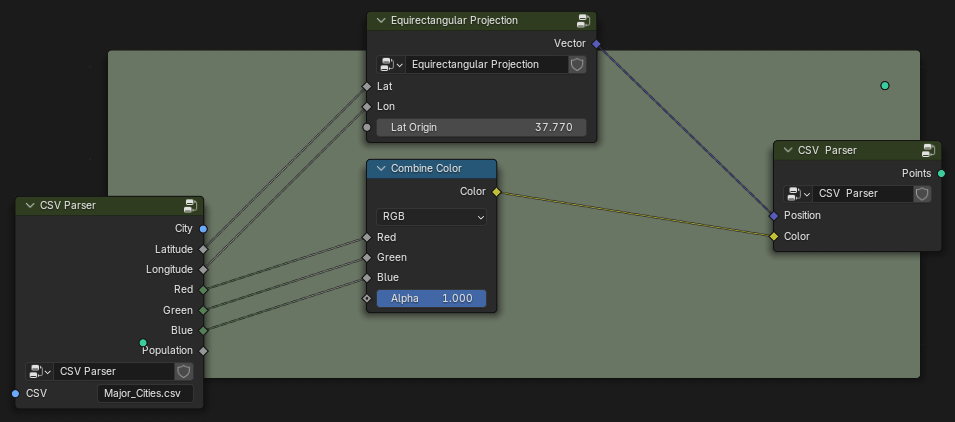
A bit weird starting directly with the output but by nailing this down first it makes things clear. The CSV Import node would output a PointCloud where the headers (first row) will signify the attributes of a point and each row (except the first row) would be individual points in the point cloud. Geometry Nodes have a good support of point clouds and point cloud operations can naturally be chained after the import CSV node.
Columns and their data type
Before parsing the full CSV, a pre-parse step would go over the first row, to figure out the headers/attributes. the second row would be parsed to figure out the data type where the we will try to parse the value, following a precedence order of supported data types.
supported data types (I just came up with this list while writing this post out, nothing is concrete, need to figure out required data types)
int 8/16/32/64
float 32/64
string
precedence order (similarly need to figure out a ‘good’ precedence order)
this would be order in which we will try data types and break on the first successful pass
User overrides
Looking at the above parsing logic the first question that comes to the mind, “what if I want to use float64 but float32 has higher precedence”. well for this the CSV import nodes would allow overrides (most probably from the n-panel for the node).
Essentially the user overrides would be a map of column name → data type, during parsing the second row we will check this map before trying to figure out the data type. if the column name is there in the map the parser would only try that single data type and fail by notifying the user if there is an error.
I also thought of adding null/void as a data type telling the parser to ignore that column and not import the data for that column . this can be helpful when working with large csv files and save up on processing time and memory
I believe this implementation is simple and straightforward and can function as a good starting point. looking for feedback and any other ideas
I think however after experimenting with this that a PointCloud will fit more then 90% of the use cases.
So yeah I think having a PointCloud as you proposed is a good choice.
#Columns and their data type
Instead of a pre-parse I think doing all things manual would be better.
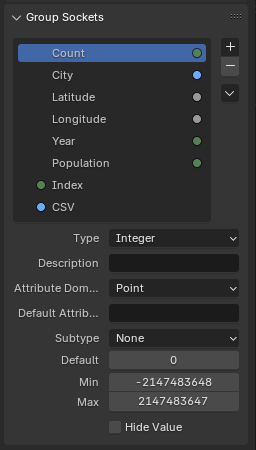
Just like how we have group sockets now it will be perfect I guess (with minor adjustments).
There is a field for default value which is great for if a cell would be empty.
A few things about pre-parsing:
Some CSV’s are filled in sparse, e.g. a row would look like: ;;;4;;;;;;2;;;;;;14;;
This will be problematic guessing the data-type
For the above, they might look like integers, but they could still be floats but just happen to be a round number on the 2nd row of the csv.
For the data-types you mentioned, I don’t know what’s all under the hood with Geometry Nodes but so far we have support for float, integer and 8-bit integer.
I guess String will be the hardest to implement since it has to be a pointer to the String and a lot of the nodes we have so far don’t work with String (yet). So to keep things moving I really hope your initial release doesn’t support String.
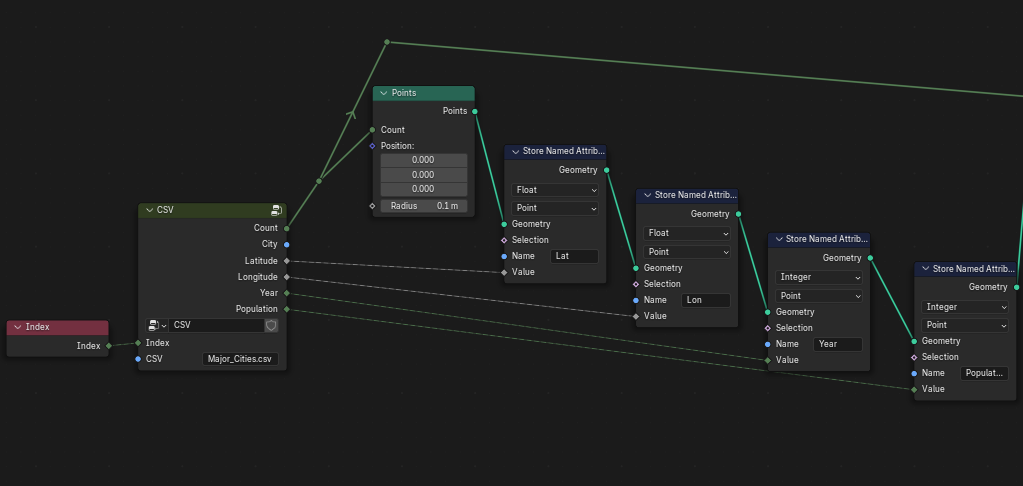
Ok while typing out this post, I thought maybe it should be a bit like the Repeat Zone and Simulation Zone where it comes with two nodes, in and out, I call it CSV Parser in the screenshot.
The first node will have the columns of the CSV specified by the user and the second will be the output.
User overrides
Well in some sense I talk about that above, but to continue:
I think instead of adding a null/void data type it should be a checkbox or something to disable the column. In case of the Zone thing, it will just be a matter of the column not contributing to the output.
Hello, I wanted to share with you that since day one I read about your Import Nodes on Blender Artists Forum I was really amazed.I already worked a lot with the OBJ import node.
I wanted to ask if by any chance there will be a USD import node? I can only write python by now, but have the strong desire to try this myself soon.
Actually there is no option that is similar to Limited dissolve and there is no way of building a node group that behaves like the limited dissolve in edit mode.
A node that could do just that would be really usefull for simple remeshing in workflows like that while using probably less computing power than a remesh or decimate modifyer.