File Input Node
Name: Divyam Maru
Contact:
- I am active on [email protected] .
- You can reach out to me on my WhatsApp contact no.: +919909977177
- Alternatively, one can contact me on blender.chat, where I go by @Divyam-Maru
Synopsis
The main motive of the project is to make one or more than one node/s that dynamically load 3D files, such as STL, OBJ, Alembic, CSV, and 3D. This node would take inputs of files and would output a Geometry-type object.
Benefits
Geometry nodes undoubtedly form a major part of 3D design functionality in blender with their versatility. It would however feel even more complete with the addition of a 3D file importing node that would remove the need to import an object in the .blend file for it to be usable by the geometry node system. This would reduce the size of the .blend file saved on disk. Not to mention this might also allow for the usage of more robust 3D assets for usage in content creation as opposed to before the same.
Deliverables
- At least one new node type that dynamically imports files to use in Blender. This node will have the option to load up a 3D file and output a Geometry Data Type.
- For STL, Alembic and OBJ files, the determination of output is quite obvious
- For CSV files, one can visualise it as a representation of the mesh as it happens in the spreadsheet. Incase the CSV file is an invalid type, where there are not 3 columns, an error in the node will be thrown.
- Usage of existing parsing code to introduce a new datatype: File. Image will become a special case for this datatype. Also python API integration for the same datatype.
- User Documentation
- Potential Tasks
- Developer Documentation for the new datatype if implemented
Project Details
Introduction of a new Datatype: File
- Data Structure of File
A file essentially is everything that can be programmed about the contents and nature of a file. The File datatype will store the following attributes:-
- Filename: std::string
- Path: std::string
- Size: float
- Type: struct:-
- 3D Object
- Python Script
- CSV-like Files (Excel, CSV, etc)
- Usage of the File Data Type
The File datatype is primarily going to be used for the File Input Node. Using the information parsed in the popup box like the one used for image selection, one can set the data of a File and then utilise it in the node, or for any other future purposes.
I will also work on design of a python API to handle the File Type and to make it easy to integrate it into future add-ons.
File Input Node
- Basic Appearance and Function:
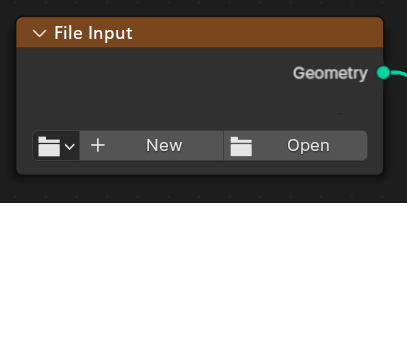
- Function for CSV
In case of CSV or similar spreadsheet type files, it will show the (truncated in case of huge row numbers) rows and vertex coordinates.
- Additional Tasks
-
A 3D viewer to view the imported file, similar to the rendered mode.
-
Should the time constraints permit me, I would like to also work on proper developer documentation of the features I introduce as well as deliver some case studies for the usage of the same. Along with that I will also try to contribute to other spheres of development and community as and how instructed by my mentor.
-
- Additional Tasks