Update 4/2/2024: Revision 3 (GSoC version).
Project Title
Sample Sound Node
Name
Lleu Yang
Contact
E-mail: [email protected]
Blender developer account: @megakite
Blender chat: Lleu Yang
Synopsis
This project adds a Sample Sound node that retrieves audio from sound files, and provides their frequency response over time for use in Geometry Nodes.
Benefits
The built-in Geometry Nodes system currently lacks a way to retrieve sounds and generate useful information from them. This makes some specific kind of tasks (e.g. music visualization) hard to be accomplished using vanilla Blender.
Therefore, this project aims to:
- Provide the ability to retrieve sounds from files in Geomety Nodes,
- Generate amplitude/frequency response information based on several customizable parameters, and
- Be written in native C++ with caching/proxy operations to speed up execution.
This project will empower creators to easily access useful information of sounds, which opens up countless possibilities in their creative works. The whole Geometry Nodes system will also benefit from this project, since it now has a brand new dimension: the dimension of audibles.
Deliverables
-
A new socket type in Geometry Nodes called Sound that corresponds to Blender’s data-block type of Sound;
-
A Sound Input node that can read a single Sound from Sounds in data-blocks;
-
A Sample Sound node that takes a Sound, which then goes through several tunable internal processes, including:
- Gain control,
- Playback progress (sample time) control,
- Temporal smoothing,
- Audio channel selection,
- Frequency specification (FFT.)
The Sound will be finally converted to a corresponding amplitude/power value (as Float) by using the options above.
-
A series of usage examples and documentation related to all the deliverables listed above.
Project Details
User Interface
Below is a simple user interface mockup of Sound Input and Sample Sound node:
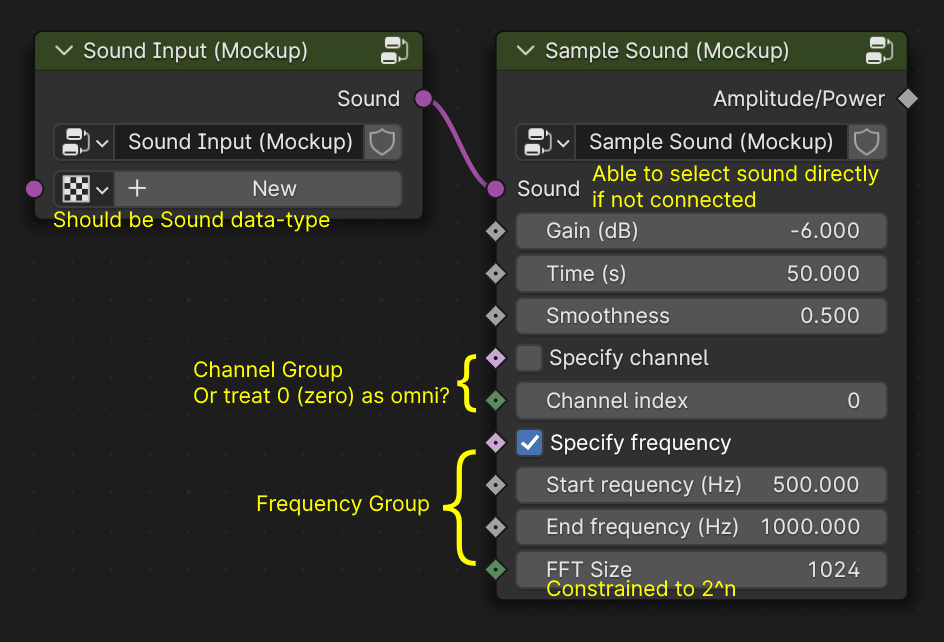
And one of their possible use cases, i.e. visualizing spectrum for a given Sound:
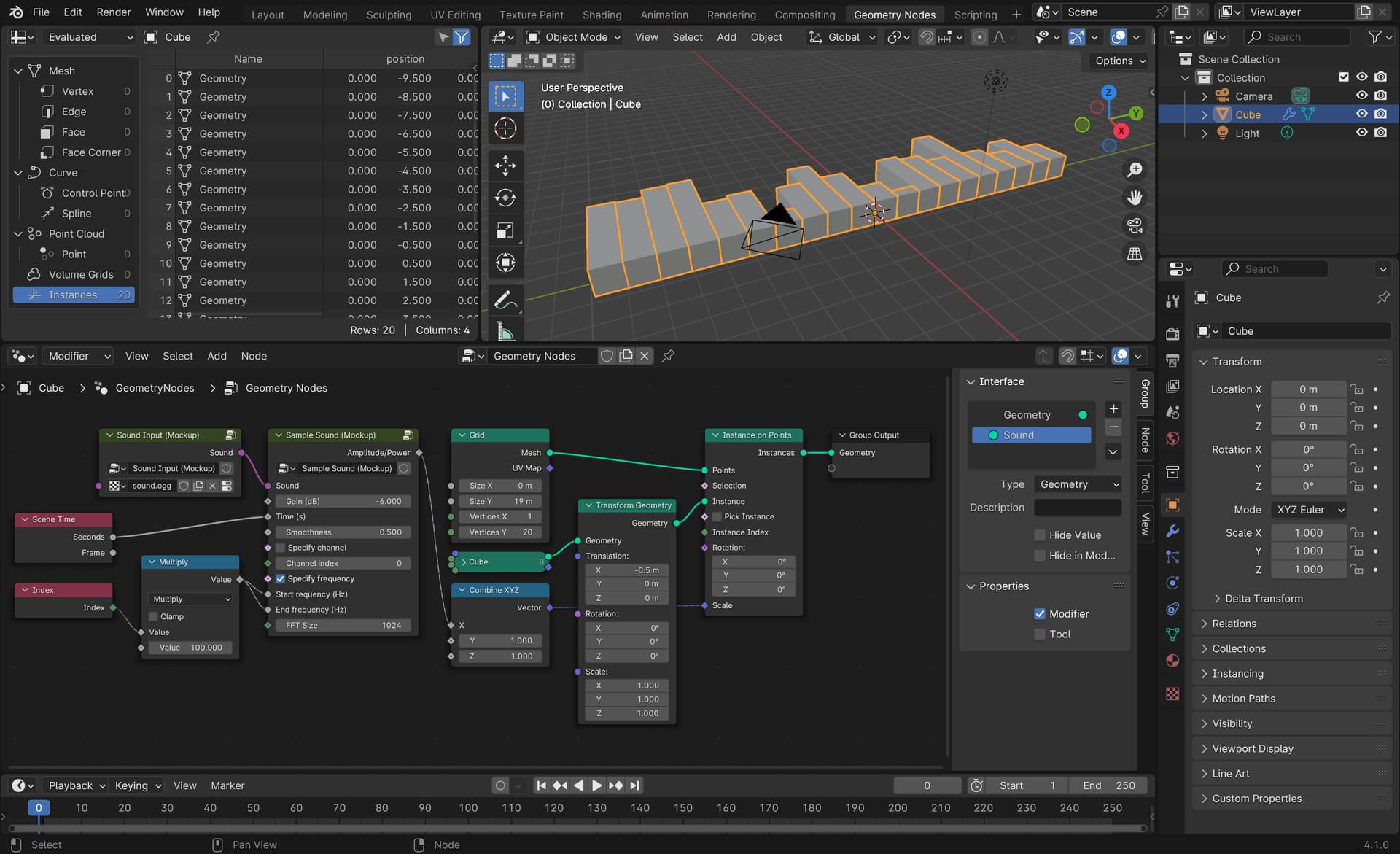
Details may be further determined during the coding period.
Sound Socket
Blender’s Sound data-block struct bSound already packs up all the data needed for audio processing, e.g. channel amount and sample rate. Thus, the Sound socket should be a relatively thin wrapper upon the Sound data-block type.
Library for Audio Processing
Blender uses Audaspace as its all-purpose audio engine. It already provides nearly all the operations that this project will make use of, for example:
-
Retrieving audio from sound data-block through
aud::SoftwareDevicewhich supports various mixing operations as well as 3-D audio processing, -
Directly reading sound samples through
aud::SequenceReader, and -
Proceeding FFT calculation using
FFTPlan(which is a wrapper upon fftw3.)
Actual functionality of this project will be primarily based on Audaspace.
Caching
Sound Spectrum, which is part of the original Animation Nodes project that calculates spectrum from audio, uses a LRU cache to store Kaiser window function results.
Caching mechanisms like this should be implemented in a larger scale in order to speed up overall execution. One of blender’s dependencies, Boost, already provides several ready-to-use classes, e.g. boost::compute::detail::lru_cache, which can be a good start.
FFT Result Storing
General audio processing software and DAWs usually generate a peak file for each corresponding audio file to achieve faster waveform drawing procedure, e.g. REAPER’s .reapeaks file:
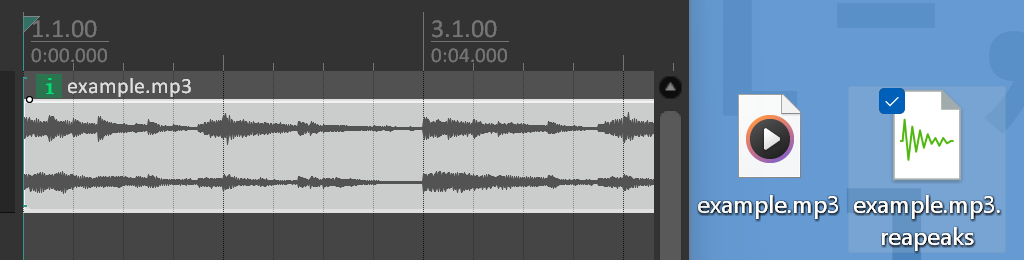
Similar method can be used for storing calculated FFT results. Detailed file format may be designed later in coding period.
Project Schedule
| Week | Task |
|---|---|
| 0 | Bugfix related to Geometry Nodes, RNA/DNA, and media processing |
| 1-2 | Basic functionality of Sample Sound node: gain control, playback progress control, channel selection, time domain information (overall amplitude) |
| 3-5 | Full implementation of the Sample Sound node: temporal smoothing, frequency domain information (FFT), and caching mechanism |
| 6 | Midterm evaluation |
| 7-8 | Implementation of the Sound socket type |
| 9 | Implementation of the Sound Input node |
| 10-11 | Documentation, refinement and bugfix |
| 12 | Final evaluation |
| 13 | Padding |
References
-
Sound Spectrum: One of the nodes from the original Animation Nodes system. It already provides nearly all features that this project plans to implement, and therefore is a very valuable reference for this project.
-
Sound Nodes: An add-on that enables user to analyze and make use of sound clips. Its functionality is based on pre-applied keyframes, which is not as flexible as real-time calculation. Despite the limit, it can still be a possible reference for the bigger picture.
-
Mic Visualization System: A real-time microphone visualization system utilizing UPBGE. Although real-time input is not listed in current deliverables, it can be inspiring for possible extension in the future.
Bio
I am Lleu Yang, an undergraduate student in Computer Science from China, and also a hobbyist music producer and visual designer.
I have a solid grasp of Blender’s usage, and have made several 3D stills and movies using this amazing software.
I am proficient in C and Python, fluent enough in C++, and have been consistently learning modern C++ features and Rust.
I have prior experience in audio/video processing using FFmpeg. I also have extensive knowledge in common audio/video codecs.
I have previously worked on some projects related to signal processing that utilizes FFT, e.g. EEG analysis.
Here are my contributions to Blender so far:
")