This is not true, anonymous attributes will be removed when they are not referenced anymore. The capture attribute node can actually completely skip generating the data if it isn’t needed.
In general, anonymous attributes give us quite a few optimization opportunities that we wouldn’t have with named attributes.
But I think the bigger reason to prefer anonymous attributes is that connections are expressed with node links, and you don’t have to use arbitrary (or potentially conflicting) names to reference data. Of course different people will prefer different workflows, but the anonymous workflow is definitely more portable and probably easier to read, especially when we have something like hidden node links.
We’re not considering deprecating anonymous attributes, that was never the idea with adding the named attribute nodes.
But that’s the similar case with Named Attributes too, isn’t it? I mean if I created a named attribute, I’d expect it would not actually be evaluated until I use it somewhere down the tree, and then I’d expect it to be only evaluated up to the point of usage, and no further.
I guess the portability and name conflict avoidance are valid reasons too. Named attribute usage was a hell when we had the original named attribute based GN, but now that we have fields, naming and attribute is actually a lot more convenient than having to thread it though the other nodes out of the capture attribute node.
Rather than using capture attribute as a crutch to prevent name conflicts inside of the reusable node groups, I’d expect to see some sort of ability to use node groups as namespaces for named attributes contained within, so the GN node groups (functions) would gain sort of a concept of “local variables”.
I honestly don’t believe hidden/portal links should ever be a thing. I am afraid it will just give people a tool to create some very confusing node networks, but I may be alone on that.
Actually that’s not very doable in the general case. People expect to be able to see named attributes in the spreadsheet, or access them on a geometry at a later point after evaluation has finished. So we can’t created named attributes lazily in the same way.
Namespaces/scoping names was something we discussed when working out how fields should work. Personally I prefer keeping the interaction of attributes and names simple and predictable, I think any scoping rules would be hidden and not so intuitive.
Though I do share a bit of your concerns about the complexity of node networks with hidden links, I think we can do hidden links in a way that doesn’t increase confusion too much. There was plenty of discussion about that in the thread I linked. I also like the hidden links solution because it’s a more general concepts than just for attributes.
Yeah, these are valid points too. I did not think about seeing named attributes in the spreadsheet. They obviously need to be evaluated even if they aren’t used, otherwise the spreadsheet would not show the right values. At the same time I am not sure how useful it is to see just numbers in the spread sheet without actually using the attribute for anything. So this is a tough one.
Anyway, I guess time will show… I still somehow expect people to start using mostly named attribute node set and capture attribute being relegated to more of a niche, circumstance specific tool.
I know I’ll be using store named attribute from now on. I’m super tired of the long connections going all over my nodetree, having to reroute them like it’s some kind of factory simulator game. It’s capture attribute with the output link hidden ! I’m also not super keen on the link hiding thing, not sure how positive an impact this will have : how do we make it visually obvious that the user hasn’t just terminated a node chain at this arbitrary point, when in reality it invisibly connects to a different part of the tree?
I posted a mockup in the portal thread which I think could make the idea of portals work. It’d turn them into sort of “temporary named variables” which are not restricted just to attributes that have to be captured.
Yeah that would helpful. As an additional display option. Houdini handles “parameter references” that way, as an overlay : by default they’re not shown.
Still waiting about “Particle / physics / simulation nodes” and node for edit the geometry create by Geometry nodes called " Checkpoints "… Any update about thems ?
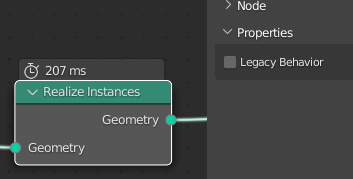
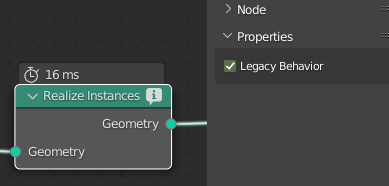
I have a basic scattering setup with 200k instances, and editing this is significantly faster with “Legacy Behavior” enabled in the Realize Instances node settings.
Yes patient ok… but one year as already passed… and nothing about this is mentionned / created or designed… i’m really worried about this features… when i see Particle Flow in 3DS max i just hope blender make a thing more better than 3Ds max or equal…
Just go ahead and report it as a bug. Worst thing that can happen is that they will tell you it’s not a bug but some known limitation. Just be sure to attach a repro .blend file where it actually reliably happens.
It’s not one new button, it’s whole new complex system. Those take time to design and implement. I mean look at 3ds Max. They wanted to add procedural modeling to compete with other DCCs using bifrost, but they messed up the process and gave up. Blender on the other hand did it right, but doing things right takes time.