This document contains has two main sections. First it outlines the goals and then describes the actual proposal.
Goals
This proposal addresses the following use cases:
- Bake simulations for a specific frame range and store the result in a user-defined location on disk.
- Bake not only simulations but any non-static geometry.
- Bake a static geometry that takes a while to compute. Potentially also store it in the .blend file to avoid having to recompute it after reload.
- Edit procedurally generated data manually. For example, to fix individual frames in a simulation.
- Create node group assets that allow progressive baking. For example, a fluid sim could be baked in multiple stages like preprocessing, simulation and final mesh generation.
- Allow accessing geometry from a different frame by accessing a baked version of it.
- Have a centralized place to manage baked data from a .blend file.
Proposal
The proposal has multiple components which are explained one by one below.
Checkpoint Node
At the core of the proposal is a new Checkpoint node. It can bake the incoming geometry at the press of a button. After baking, the baked geometry is owned by the node. That has a few consequences:
- If the node group is used in multiple places, the checkpoint node will output the same geometry independent of where it is used.
- If the node group is used as asset, the asset also contains the baked data.
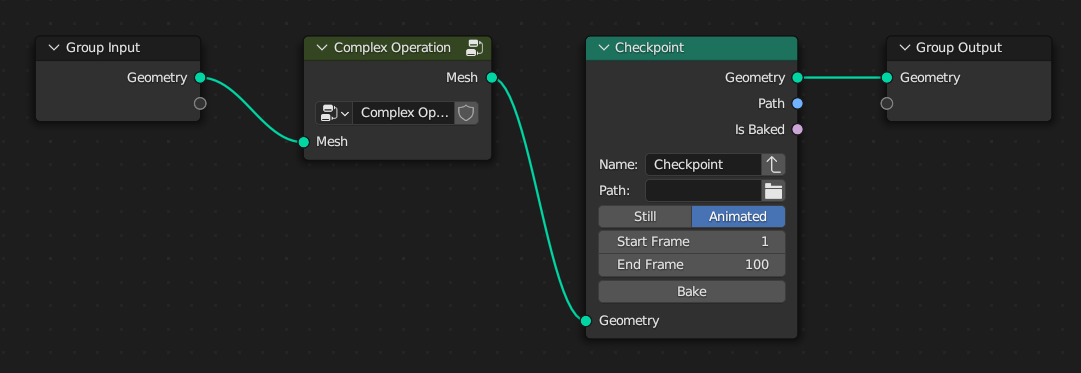
The UI in the screenshot is certainly not set in stone, but it shows some of the important elements. A checkpoint should have a name so that it can easily be identified in a global list containing all checkpoints. The name does not have to be unique, but of course that can help the user.
The path can be used to specify a location on disk where the baked data should be stored and loaded from. If no path is specified, we could support storing the data in the .blend file directly.
Exposing to Group
It’s often the easiest to just work with the Checkpoint node directly. That’s especially true while working on a new node tree or when a node tree is the top level tree for an object.
However, if the Checkpoint is in a node group that’s used in multiple places, and it has to adapt to the inputs of the node group, then each group node should really be able to manage the checkpoint itself.
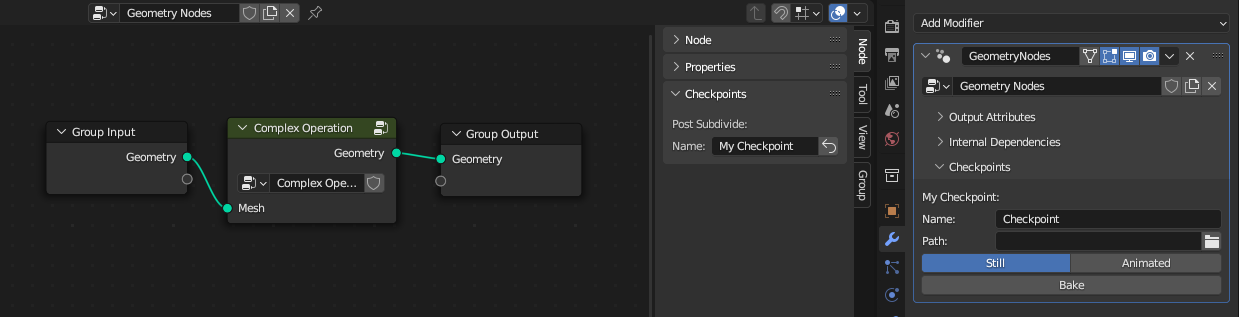
For that purpose, a checkpoint can be exposed to the group. In the mockup that is done by clicking on the little arrow-up icon next to the name.

When the checkpoint is exposed to the group, the Checkpoint node looses ownership of the baked data. Instead, the users of the node group own the baked data. In the example above, the group node on the right is the new owner. When it is selected, there is a new Checkpoints panel in the side bar that allows managing all exposed checkpoints. This group node could now be used in different places and and every group node can specify its own path where the data should be stored.
As shown in the mockup, the arrow-up icon also exists in the sidebar. That’s because it is possible to further move ownership of the cache up the node hierarchy. In this example, a modifier uses the node group directly. So any checkpoint exposed from the group would become visible and manageable in the modifier. Ownership of the baked data now lies with the object containing the modifier.
Currently, there are three different possible owners for checkpoints, but in theory more are possible.
- The
Checkpointnode itself. - Group node containing exposed checkpoints.
- Modifier containing exposed checkpoints.
Global Checkpoints Panel
Since every checkpoint has a well defined owner and name, it’s easy to list all checkpoints that are available in a .blend file.

The checkpoints panel on the right shows a list of all the checkpoints. What information and operators are available there still has to be worked out. We definitely want some way to bake and free a subset of all checkpoints at once. Furthermore, we likely want some filtering options like “Only show checkpoints that are used by the selected objects”. It may also make sense to support giving checkpoints tags that they can be filtered by.
For studio workflows which use many checkpoints it should be quite straight forward to manage the paths used by all the different checkpoints with an addon.
Note that the checkpoint list in the screenshot above does not contain “C”. That’s because the Checkpoint node with the name C does not own any checkpoint. Instead, it has been exposed to the group and therefore the modifier is the owner of that checkpoint.
Editing
The checkpoints essentially store full geometries containing e.g. meshes and curves. Eventually it should become possible to just enter edit mode on these. I don’t have any specific UI for that yet. The edit mode node that we talked about before could just be part of the checkpoint system.
The checkpoints panel could potentially be expanded to also show the geometries contained in the checkpoints.
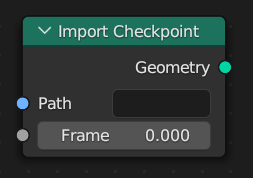
Import Checkpoint Node
The Import Checkpoint node allows reading a previously baked checkpoint at an arbitrary frame. This is useful for some use cases:
- Offset simulation by some frames.
- Access the data from multiple frames at the same time e.g. for trailing effects.
This node is a bit redundant with other planned features like reading from USD or Alembic caches. However, since checkpoints will often be stored in disk anyway, it would be a waste of memory to force the user to convert the data into another format for reading it at arbitrary frames. Currently, I intend to use the same file format that was used for the initial simulation baking. Checkpoints could potentially also be stored in common interchange formats but that always comes with the problem that more configuration is necessary to choose how to map Blender data to those formats and the result may not always be lossless (also see this).

The setup above could be used to get access to the current as well as previous geometry. Note that this also works when the checkpoint is exposed to the group thanks to the link between the Path sockets. One difficulty here is dealing with baked data that is not stored on disk but embedded into the .blend file. In such cases it might make sense if the path uses a special prefix to differentiate between actual file paths and embedded paths.
FAQ
How does this relate to Simulation Baking?
To me, the simulation baking we have now is mostly a user friendly way to quickly get started with simulations. It allows making all the objects in the scene history-independent so that random access of frames is possible. This is required for rendering in many cases. All of that is done mostly automatically in the sense that the user does not have to setup file paths or insert extra nodes.
That approach does not scale to more complex use-cases where one might want to bake more than just the simulation state or one needs detailed control over where baked data is stored. Therefore, I believe that the simulation baking should be kept very simple while the checkpoint system should be able to deal with more complex workflows.