I may be mistaken but isn’t this the current plan already?
It’s not that you could do something you can’t do otherwise, at least in theory. It might be in practice though as being able to store and recall attributes is important for being organized, working more comfortably and seeing what’s happening more clearly. Without it, situations that could be clearly read otherwise, will become a bundle of wires. Sometimes connecting an attribute directly is the best and most intuitive. Other times using an attribute is the best.
Reading your answer, to me it appears that it is mostly about how to organize a node tree and keep it readable.
There are different tools, like groups, reroute knots, frames. I guess, having data-flow connections visually different from field connections does have the purpose to improve readability of a node tree.
Custom attributes inside GN node tree could do both. Improve the way a node tree is organized, and the contrary. Handling custom attributes could be organized, but they also could be used messily.
Just to note, unlike the shader nodes, every component on a mesh can be handled and edited by more than one geometry node program (ie. what multiple geometry node modifiers give you).
I could understand why the devs. would want us to take advantage of this fact rather than the user forcing every possible operation into one monolithic tree, especially in the context of flexibility in things like enabling, disabling, or stacking effects, though it may not be the most desirable for things like complex generators.
Also, let us not forget that while there is indeed an important place for user-defined attributes, keep in mind that adding attributes to a mesh is not free as far as processing power goes. In the 2.93 implementation you actually had to learn to offload the attributes (by a node which removes them) you only needed temporarily before doing more operations, I could in fact see some more low-level attribute writing stuff going in for power users, but please note the official implementation is less than a month old and needs time before an accurate assessment can be made.
Hi, here’s an idea about this:
All attributes that are not explicitly exported as an Output could be auto-deleted at the end of the graph. These would make them temporary, in-graph attributes.
About the multi-modifier workflow, I’m all for having that ability and that’s great, but we also can make a whole scene within a single node tree now, and that’s also great. I won’t speculate how the developers want users to work, but I think it’s a good path to allow and encourage unified graphs.
This is somewhat funny to me. I understand where you’re coming from but the number 1 complaint about GN in 2.93 with the named attributes workflow was that it was unreadable, because the attributes dataflow was not visible as nodes but instead was hidden in the names of the attributes.
I think I disagree with you here. I think that a very long node is still more readable than an attribute name somewhere in the start of the tree which corresponds to an attribute name somewhere on the other side with no connection between them to let you find it.
Don’t get me wrong, I still liked the possibility to get/set custom attributes and do direct calculations on them and it would be a shame if that completely disappeared in the new system. I don’t really get why all the attribute manipulation nodes need to be removed completely. The attributes are still there after all. ( Though I can understand wanting to remove nodes which are really redundant. Maintaining is not free after all. )
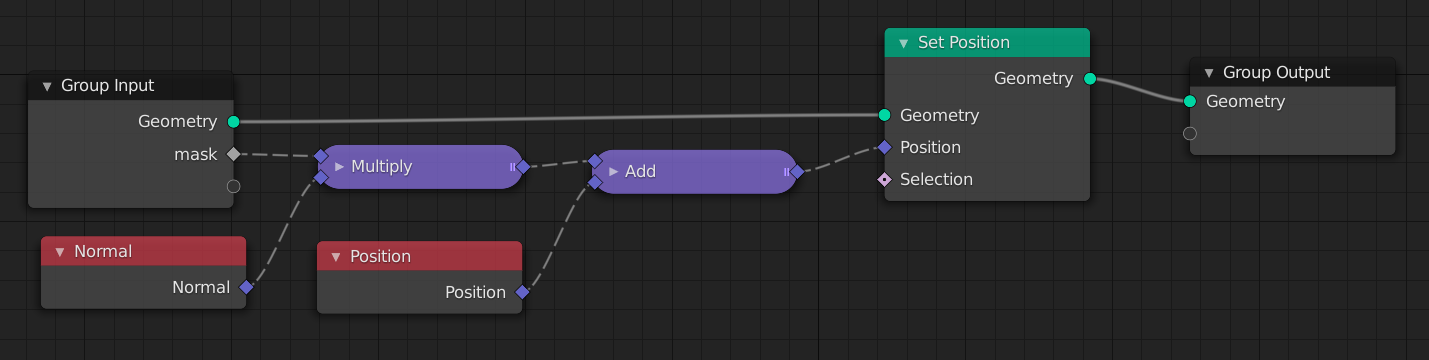
In the previous system I had some nice experiments where I multiplied a vertexweight with the normal and added that to the position. I don’t really see (yet) how I could do that with fields. But I hope it’s just because I don’t fully understand it yet.
That’s not really what I meant : I’m not advocating the use of the old attribute manipulation nodes (attribute math, attribute color ramp, and so on). They’re irrelevant now because all your attribute calculations can be done with regular nodes, taking advantage of the awesome flexibility of fields, BUT I see added benefit in storing them by name for later retrieval. (benefits in readability and communication of intention, mostly, which is important when you pass down your work to somebody else)
Without get/set nodes you need to go through the modifier interface (that’s what we’ve been discussing for the last few posts) : you have to create a group input, and go in the modifier and name it the same as your vertex group. Then it goes like this :
Maybe “Do you still want access to named attributes in the new fields system?” is a better way to phrase it. That’s how I voted.
There are already commercial courses and tools that rely heavily on the notion of named attributes. It might be prudent to throw a bone to those creators by allowing them more leeway in adapting their works to 3.0. Not necessarily advisable or optimal, but prudent and respectful.
This was posted before the " Hardcoded Attribute Names Removal" proposal, actually I believe that proposal was posted specifically because of this comment in the task. The end was that people did not like it and the proposal was not selected.
Then later Hans posted his ‘’ Shareable Named Attribute Node’ proposal, which in my understanding was to offer a middle ground. People seemed to be clicking a lot of likes and there seemed to be no objection. So they ended up chosing the shareable proposal.
So I don’t think they are not going with the removal, no need to rage on that now I think.
I’m not suggesting to actually replace them. The individual nodes are more high level, easier to learn, easier to use and make a more readable graph.
But in the end, being able to set/get any attribute is more sustainable and scalable. Does there need to be a node for every single attribute in the software? Every time an attribute is added, a node needs to be created as well? What about working with custom attributes from, e.g. alembic or usd?
It’s nice to have a consistent, generic solution for any attribute, which is also a nice way to store Variables per element. A great tool for users to have in their workflow.
Because that workflow is supposed to have an attribute processor, we never got it. Instead in order to fill up the attribute processors role we had a whole bunch of attribute nodes. Idealy you have an attribute processor doing most of the lifting, and you just occasionally use an attribute node like the ones we had.
The idea that the fields way of doing math is better is not in question, it is. The flow of what is happening is clear and easily followed. The attribute processor would have allowed for that, as it is a node that drops down to a lower level (like nodegroups) where you can then do math just like fields.
I know attributes can still pop up here and there without connection, thus some confusion can occur, but I think of that as more of a positive, it removed a lot of UI hassle and keeps things clean and elegant.
Thanks. That clears it up somewhat in my brain ;-).
Well, you can’t keep everybody happy I guess. Most people really hated the invisible dataflow through attribute names it seemed. Maybe the attribute processor would have solved that, but I had the feeling at the time that adding another level didn’t really help readability either. But for sure each system has it’s pros and cons.
We must be able to manage our own attributes in the node tree. Being able to have them outside is a good thing, but for some large node trees, it complicates things.
Fiels’ original proposal was much better.
Another point:
It’s great that you can set attributes in modifiers, but having them stack-exclusive has some more limitations. For instance, if I want to use this geometry nodes tree within another, do I have to make more sockets and always set it at the top of the chain? This makes even clean trees messy in the end. Rather than having to read and set only the relevant information, we have to go all the way up and look at what is affecting what.
Besides, wasn’t the nodes system made to replace the stack system? Why are we forced to use it?
A big part of the Everything Nodes project, is to convert the modifier stack to a much more powerful Geometry nodes system. This document serves to explain how this will work more precisely from a user point of view.
Geometry nodes encompass what Modifiers used to be, but where modifiers only allowed you to modify geometry, Geometry nodes also allow you to create geometry.
The first two paragraphs of the original design task.