Yes, I also liked it better in the prototype and hope we get the custom attributes get and set nodes
3 Likes
I am genuinely confused. From this screenshot it seems we will have the store but not the the get? What about attributes from object info then? I thought it says this in the field conversion form:
@HooglyBoogly What exactly is the situation?
3 Likes
Well, here’s the interesting bit: This thread was created for feedback from the community, when this proposal was released for a test. And I saw all the feedback was super positive. This Fields decision was taken based on community feedback, as opposed to the Expandable Geometry proposal.
Meanwhile I was extremely confused why is everyone so excited, because I was unable to do ANYTHING xD.
The issue is that the community was excited about the fields prototype build since it mixed the existing custom/named attribute concept used in 2.93, with the new fields system. Which was the best of both worlds and potentially game changing, somewhat like sops and vops all mixed into the same network. Seemingly now, it will be pretty much just the fields system with some ways of getting attributes in and out of networks via custom name attributes.
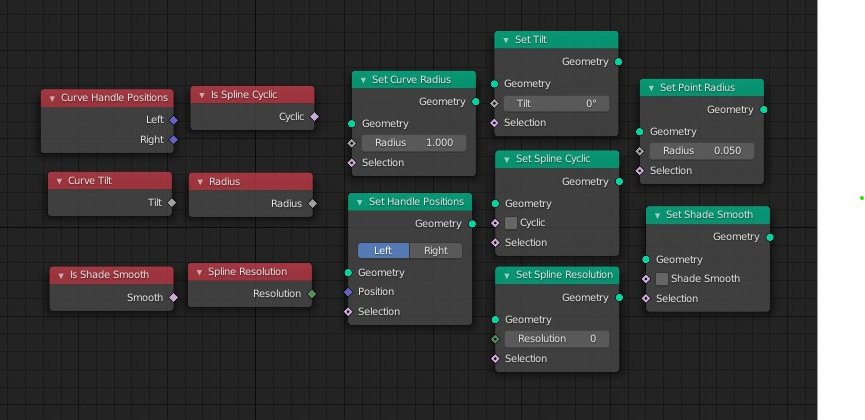
My concern is what will happen as the complexity of the node systems increase in the future, with particles, volumes, modelling operators, various dynamics solvers etc. all needing to interact. Will there really be a separate output node for each of these builtin attributes (as we currently have with position and normal, and soon shade_smooth, radius, spline resolution, tilt, etc) and how many of these will end up populating a list. There could potentially end up being hundreds of get builtin attribute nodes in a few years. This could instead easily be solved just by having an attribute get node and typing in the attribute.
If the goal is to avoid beginner users not having to type in attribute names to make life easier and increase discoverability, it could end up having the opposite effect. Because the list of nodes will end up getting so long, you will have to type in the name of the attribute get node you are looking for in the search box anyway… so either way the user has to type out something.
Even in graphical coding systems like UE4 blueprints or the Construct 3 event systems, the user still has to type in variables that they want to create and think about any possible naming conflicts. There is no way of avoiding the fact that all node systems are a form of programming, so there will always be some need to manually type variables, math functions, attributes at certain times.
Add to this, the usefulness of creating custom named attributes for all sorts of uses, and these recent decisions could really end up biting the everything nodes vision hard in the long run.
To see a vision into the geonodes future, multiply this image by 10 ![]()
17 Likes
Not so true, maybe you are not aware but the search feature is not so friendly towards non-English users with translation on. At least in the Chinese community the search feature is rarely used. Attribute names are in English while node names will be translated.
One of the many obstacles I faced when promoting GN pre 3.0 was that people had to type English attribute names and they hated that.
In many ways these nodes are going to make my video tutorials easier to follow, so I like these individual get and set nodes.
What I would argue though is that we need both the individual nodes and the type name node, even just for user freedom. If the user wants the handy individual nodes they can use them, or they want to use the typed name for attributes they should also be able to do it. Pre 3.0 we were forced to type names, and I believe forcing the user to not type names is going to another extreme. So I would just like to have both.
12 Likes
The new node is very similar to the material node, and many times you don’t know the specific effect you can walk through the material node again to see the effect.
Sure, I can understand that point of view. I am not sure how a non English speaker uses “H” with it’s heavy reliance on vex and attributes?
I think the good middle ground is what I suggested in an earlier post and is within the Blender ethos. That is to use a single node with a drop down menu for all of those attributes, just like is done with the math node. Rather than a separate node for get position, normal, radius, tilt etc they are all just in a drop down menu in a single node. No need for any typing.
Similarly the new attribute statistic node should have just gone with a dropdown design, rather than 8 separate outputs. If you look at the commit, the original version had a dropdown design and was changed for some reason. Those large nodes are often trying to autoconnect when first laid down and while you can hide the unused sockets, are still cumbersome to use.
7 Likes
I like the “exposed sockets” design, it allows you to connect several outputs from the same node. Plus it’s unlikely that this node is going to grow, useful statistics have already been implemented. 8 sockets is similar to the “geometry” Cycles node and others, I think it was sensible to keep it exposed like this.
I agree with your previous post, that a a single “set attribute” node might do the job just as well as a bunch of attribute-specific nodes (set position, set curve tilt, and so on). It crowds the “add” menu for little extra benefit. In addition to that, it doesn’t help teach the user how to manipulate things generically (which the attribute system is all about).
I’m also wary of having only anonymous attributes, since this means we can have very long node connections and the issue that stems from that is well-known : it hurts readability. Having named attributes allows the user to just store them in the geometry for later retrieval, without node connections. Now if the UI part of this (node connections obstructing the view) was solved without resorting to named attributes, I’d probably be fine with it, I’m not sure. But I think there needs to be a way.
I think the name conflict things is mostly artificial. Sure it can always happen, but it’s unlikely and the risk is not worth getting rid entirely of named attributes in my opinion.
4 Likes
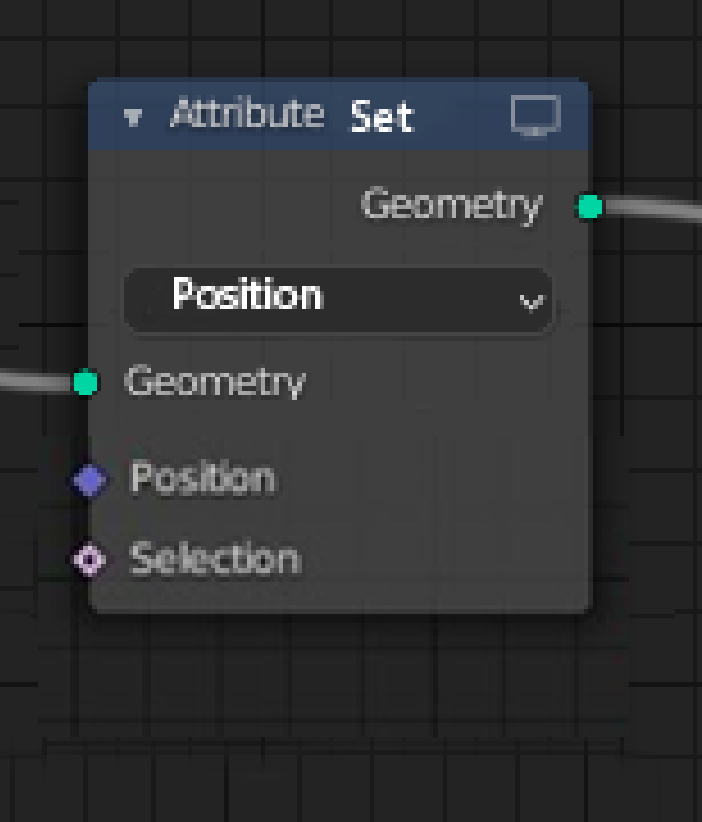
How about a generalized attribute set node
with an enum of various possible builtin attribute, and custom named attribute, of course.
i think that this solution resolve both problems, no repetitive pollution thanks to a generalized workflow + builtin attribute access for “beginners” or non-english speaking users
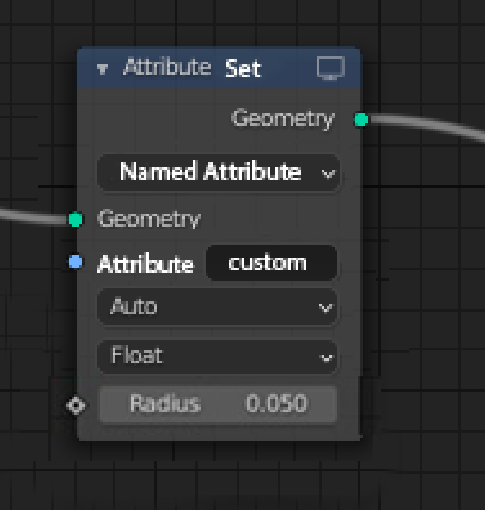
same can be done for getting field/attributes, a generalized attribute get node :

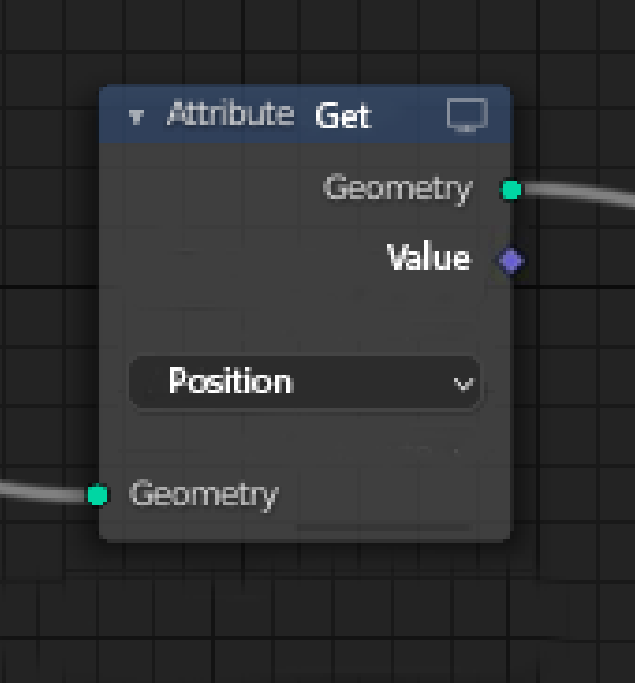
But some folks at the design team seem to reject the “get” nodes, preferring input nodes, which is understandable (?) It would be nice to have clarification about this design change.
I think the best quality about a “get” node is readability.
With the get nodes, we can clearly see from where the “array-value” is “coming from”. Don’t get me wrong i know that fields are not “array-values” but that’s the most easiest way to read them imho. With get nodes there’s no need to do reverse reading in order to understand the nodegraph function flow.
If attr get idea is rejected, then an easy way to access named attribute field value would be required such as the input attribute node from the pototype (that we all liked unanimously it seems ?)
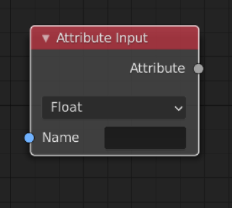
Personally, i too, much prefer a generalized solution, than having 50 input nodes and 50 set node in blender 3.3 ![]()
Similarly the new attribute statistic node should have just gone with a dropdown design
Note that it’s how it’s done in shaders too.
18 Likes
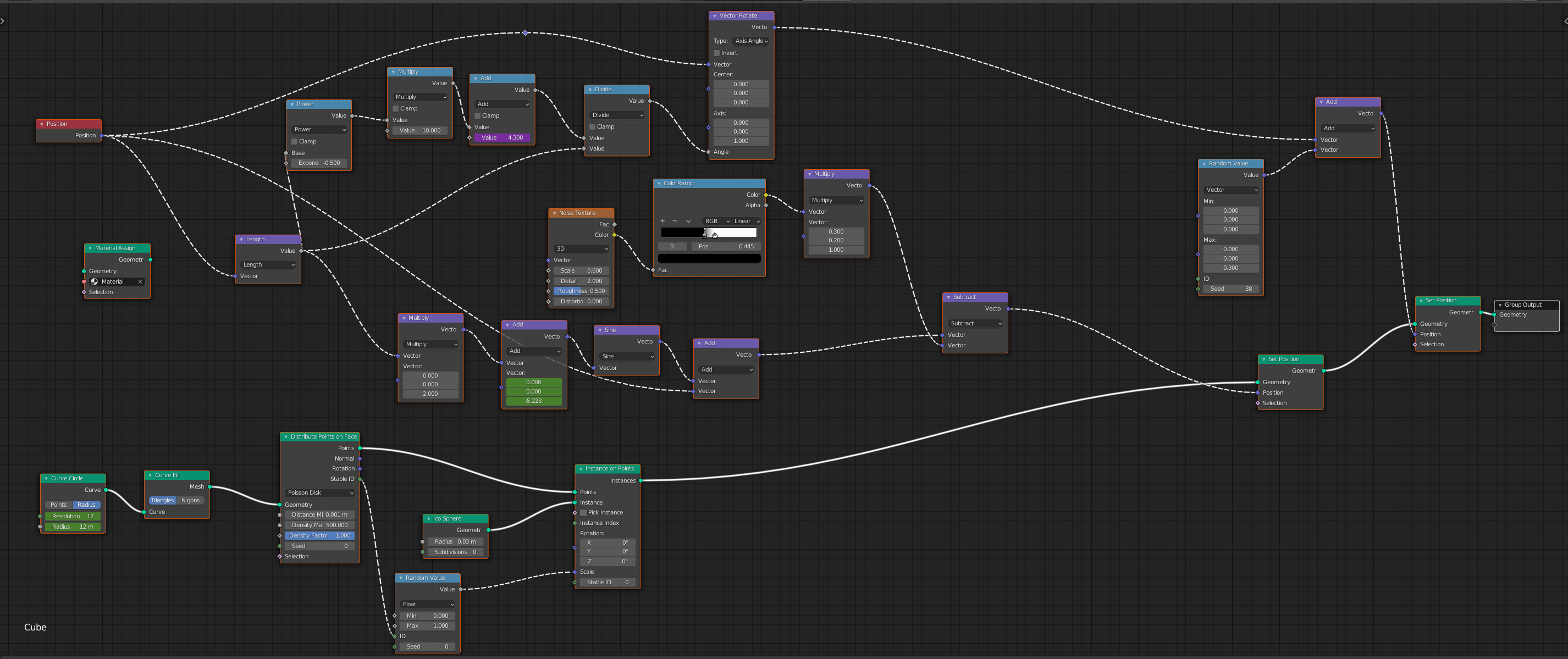
Maybe (or rather “hopefully”) I understood some things wrong when it comes to the plans for all of this, but to me it sounds like there will be a sh#*load of hardcoded attribute inputs (like position, normal, tangent, vertex colors, all the curve attributes… literally dozens) in the Add menu instead of a single and simple “Get Attribute” node that can import factory and arbitrary (user created) attributes where you can either type in its name and / or pick it from a list of available attributes at that point in the node stream.
Same goes for the counterpart “Set Attribute” that’s now only available and named when it’s plugged into the output of the network, otherwise it will be “anonymous” and is only available in nodes that support field inputs. I hope I got this wrong.
The idea of fields themselves is great and has a lot of potential, but I wonder how this will evolve when more complex stuff like particles or concepts like “for each” loops are joining the party.
One super basic but still powerful and oftenly used workflow in that one “King of the Hill” node-based VFX software I’m using a lot is that you can grab and use data from anywhere else in the project file, not only from the final output of each node flow. Like e.g. this mockup node tree:

If you e.g. have a low poly terrain that will be used as a collider for a fluid sim or rigid bodies and a higher res version for scattering grass and pebbles and an even higher poly version for shading, you could fetch different states of the terrain geometry from a single node tree without having to duplicate data and keeping them all in sync manually. (I hope that something like this is planned)
Now on top of this imagine there are different attributes on this terrain like weight maps for the amount, for the size and for the type of vegetation, attributes for the friction of the ground for RBDs, vertex color attributes for the color of the displaced moss in rendering, … etc.
If all of these were stored in properly named custom attributes you could reuse them later when picking up e.g. the geometry from the “OUT_Scattering” output.
How would this look like if there were only “fields”? Will you have to wire in all the “anonymous attributes” that you want to use on this output later on in each output? What will it look like if you have a network that’s not as basic as this one but one that’s halfway used in real production? I’m not even talking about the infamous dashed line (which is least of my concerns because it’s only “cosmetic”).
I’m still hoping that everything (nodes) will turn out to be awesome, these are just some thoughts ![]()
9 Likes
As many people already answered, the point is that the feedback was based on the prototype, and the final implementation is different from the initial prototype in something that appears to be a serious issue: The lack of named attributes inside the node tree.
This in general can be a problem of course, Probably, My Idea of “wireless” or “tunnel” nodes would likely be a decent trade-off solution to avoid too many noodles around but i think it won’t solve this issue:
To be honest, I personally need to try the current implementation to really tell if named internal attributes are a must and their absence is a game-stopper (which it seems to be, expecially for the point that @SteffenD mentioned). But at the moment, the lack of all the input builtin attributes nodes that are not implemented yet, I can hardly do basic stuff , while I managed to do a lot of fun (at least for me) stuff with the prototype.
6 Likes
Yes, I think hidden connections could help quite a bit.
Steffen’s comment shines a light on how difficult it is to tell whether or not the current system is sufficient given how little we know about future expansions to everything nodes. If simulations (RBD, fluids, and so on) happen in the same context as geometry nodes, I can see how direct field connections would be enough. But as soon as the user needs to change context (different node editor), or if simulations happen in a node group of sorts, wiring all these fields into the group interface might become a little tedious, instead of them being simply carried along with the geometry.
I wouldn’t mind keep both possibilities (named attributes and anonymous attributes).
To develop a little bit : some attributes are relatively straightforward and meant to have limited scope (isolate z position to create distribution gradient on mountain, for instance, this is done very simply and forgotten about right after) while some others are actually meant to be passed down and carry meaning beyond the modeling stage, like @SteffenD mentioned, and I think each method of working with attributes has merits for each case. Would it be cleaner to keep just one method and have everybody use it without question ? probably… would it be less flexible ? definitely. Ok, maybe
1 Like
I think I agree with that, despite the name collision problem… same issue there, without trying in real scenario, I personally can’t really tell how serious naming collisions are and if the lack of named attributes is worth it to prevent them.
1 Like
Hi,
from my pov, it was not clarified that storing, updating and reading attributes within the graph would be removed… I thought the attribute set/get nodes would be upgraded for using fields, while most of the math nodes would be removed.
I try to put the time to follow what’s happening, and provide feedback to the best of my abilities, but at least I couldn’t tell that this was the plan.
I do think attributes are important and the fields workflow is important too.
There could be temporary graph-only attributes, to improve on the anonymous attribute concept. If name-collisions are the main issue there could be a number of ways to address that.
That being said, if there are technical reasons to avoid certain things, it would also be good to communicate them so we understand why certain things are happening this way.
5 Likes
There is also another option …
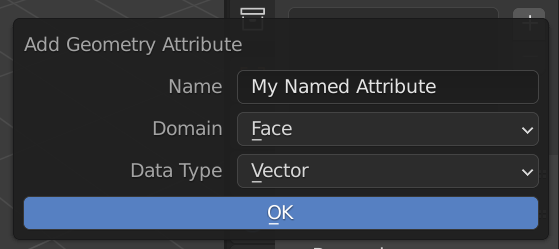
I like the thought to be able to add such attributes to an object, and pass them through multiple Geometry Node modifiers.
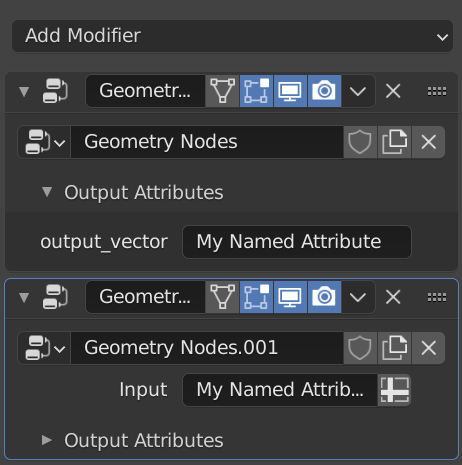
May it help to split a larger GN nodes to smaller ones?
GN could form blocks which process custom attributes, the custom attribute processing blocks can be chained in different ways.
The only problem is that the modifier input and output attributes are local to the object with such a modifier. This means that there is no way to truly make blocks that are chained. You cannot even set an attribute input/output default value. Since there is no way to set these attributes within the tree, these “blocks” must be set up all over again every time.
Maybe a way to combat this would be to have the get/set nodes but only as inputs and outputs? All of the attribute management would be at the start and end of a tree.
2 Likes
A custom attribute simply can use a GN initializer modifier. A modifier which does nothing but initialize values of custom attributes.
But, for different objects one has to redefine custom attributes and recreate the chain.
Node groups need to be considered too. One can create large unreadable nodetrees without node groups, whether dashed lines or get/set nodes are used or not.
The attribute window helps things make a little more sense, though there is the potential issue that stems from having to define all of your attributes outside of the tree. That issue is the idea that many will think the feature is broken because of this not coming to mind, despite the fact that one point of fields is that you don’t have to define attributes all the time to do even the small things.
Perhaps part of it could resolved by clear documentation, but I also don’t see why there wouldn’t be any room for a dedicated node for defining a custom attribute.
3 Likes
I am excited about the possibility to use “outside GN attributes” to split GN modifiers into smaller blocks.
It was not my intention to push people to define all their attributes outside GN nodes. Why present it that way?
Custom attributes within GN node trees also need to be managed. Initialized, removed. With fields, a user does not need to keep track of attributes.
Atm, to be direct, I am not that convinced that creating attributes from GN nodes is a must-have feature. Maybe there could be uses I don’t think about at the moment.
hupefully they will listen to the feedback ![]()
Here’s why, IMO, this logic is broken :
-
it could have been done with get/set attr
nodes anyway so it’s not a good enough justification to remove typed attr al together. Accessing attr only from there is very restrictive -
it do not work when we chain toward objects/collections. As I understand the designer of this workflow wanted to add new name attribute input in object/collection info, but this is A) cumbersome/confusing compare to a easy to understand “attr get/input” B) unecessary if there’s ways to play with attributes within a nodetree C) they won’t be able to support a possible infinity of attribute in these nodes. Ui don’t allow it
Nobody asked for typed attr to be removed entirely from nodetrees, this is coming from nowhere and everyone here is visibly very surprised by this move.
It’s definitely a nice addition! but very bad as a total replacement of what we knew
2 Likes