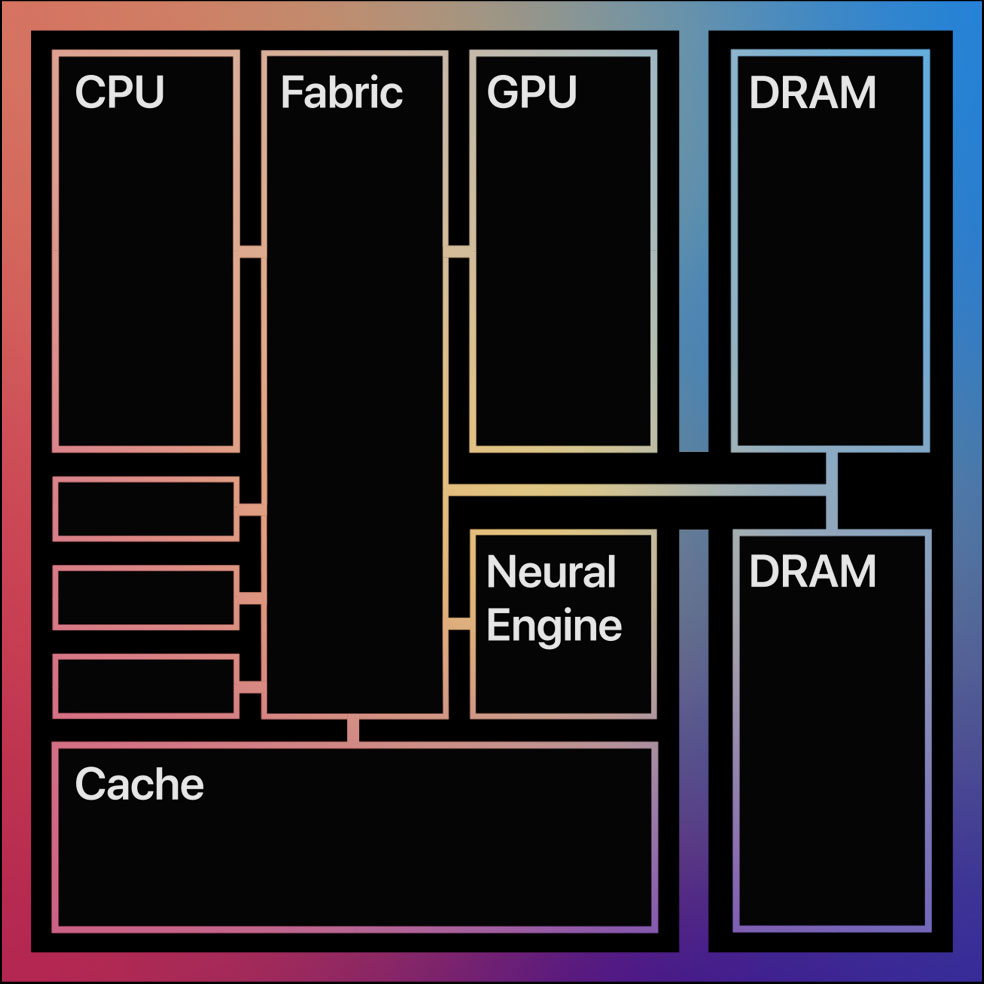
I’m wanting to be proactive with the discussion about the M1 chip from Apple and its future use with Blender.
I haven’t seen the same level of interest for the 16 core Neural Engine, that Apple included on the M1 chip, as I have for the CPU.
As of now I’m assuming the extra 16 cores would just be dormant while working in Blender?
I know Davinci Resolve talked about already using them for Smart Masking and Smart Tracking which uses Machine Learning to improve the outcomes. Affinity Photo has mentioned future use, or now, for masking and resizing images.
What are some of the ways Blender may be able to take advantage of the extra cores?
-Cycles realtime denoising on each sample rather than at the end; possibly improving the overall outcome?
-Some kind of ML Smart Masking?
-ML object tracking similar to what DR is doing?
-ML retopology?
-ML predictive “tweening” during animation or baking?
-Simulations!?
I hope this helps spur on some ideas for future development.
One of the issues with retopology is that the ground truth is not well defined and is clearly not unique. This makes it a very difficult problem. That’s one of the main reasons why there is basically no research and why there are no ML based products for that.
Wouldn’t an ESRGAN-like approach be the way to go? I’m using that for all kinds of image processing, ranging from pixel art upscaling to inpainting. The available ESRGAN models are trained with thousands of relevant images, and I keep being amazed by how effective the interpretations are. Such an approach should be possible with thousands of manually modeled / manually retopologized meshes, maybe mixed with Quad Remesher / ZRemesher results.
I agree with you that a GAN would likely be the most promising approach for the training.
Images are fantastic for neural networks, because they can easily be represented within tensors as they have exactly the same shape. There are also convolutions to process the tensors which are a prefect match as they allow you to work with arbitrarily sized inputs. So it is possible to setup a neural network which works for any image size and we also understand how to train them.
When it comes to meshes, it is still an open question how to represent them within a neural network, such that they are scalable and can be further processed at the same time. Meshes in neural networks for retopology are like:
Once that core issue is solved, it is still open how such a thing could be made artist friendly. For animated meshes, the topology looks different, that’s why it is unavoidable to have ways to specify the density, the flow and whatever else it takes to keep the artist in control.
@DeepBlender here is a machine learning benchmark for the M1. It looks like the developers noted some of the same compatibility issues you mention above, and could only compare against AMD GPUs because of the ML language.
Notable points: The M1 outperformed the the i5 by 315% and was extremely close to the AMD 5500 using 100% GPU power, while the m1 was at 10% GPU usage.
Developer says that optimization of ML language for the M1 should have it over taking AMD GPUs for Machine Learning compute task.
“Unfortunately, while the AMD Radeon was able to reach full 100% utilization on the 15” Macbook Pro, the 13" M1 never made it above 10% utilization. Despite being faster on paper, it still needs more software improvements to capitalize on its hardware. Apple is continuing to actively work on this with their TensorFlow port and their ML Compute framework."