This thread can be used to provide feedback for this proposal: https://wiki.blender.org/wiki/Source/Nodes/UnifiedSimulationSystemProposal.
19 Likes
I think the concept in the proposal is great. It is high-level and generic enough to be applicable for many situations.
Regarding the undefined behaviour for applying multiple ‘parallel’ operations on a state, I was wondering whether you had considered doing a unique copy (rather than passing mutable state) to each operation in this case. This would make sense from a node perspective, with the output of each node being the result of the operation on the input, and will only incur the memory penalty when this pattern is used, but I haven’t considered whether it’ll fit with the rest of the higher level design.
The issue with that is that you have to combine the copied state in the end somehow because you want to start from that in the next time step.
Yesterday, I was actually thinking about another possible solution to this ordering issue. The idea is to introduce an output node that “collects” a set of state objects that should be simulated. Then we could define a unique order that would be imposed by the merge nodes. Will think about it a bit more and prepare a mockup for it a bit later if I still think it could work then.
1 Like
That seems like it could work. Obviously a complex topic… It would be awesome to be able to do things like make a distance field from geometry then use that to influence a wind strength or something, I wonder whether that needs parallel simulation ‘pipelines’ or whether if could all be done sequentially…
At first glance, this looks pretty flexible and easy to understand. I can’t wait to get my hands on it.
I’m pretty much to uneducated to evaluate this proposal in a technical manner, but I thought it would be the right time and place to share this paper.
5 Likes
Here is some feedback/questions on various intermixed levels (from linguistic to conceptual):
time_step: A non-negative real number that represents the amount of time that should be simulated.
Do you really want to allow a zero timestep? What should that do, other than return immediately?
This section describes how a node system […] can look like.
It’s either “how a $THING looks” or “what a $THING” looks like". It’s never “how a $THING looks like”.
A State Object is a container for arbitrary data. It has a (possibly nested) key-value storage, whereby the key is always a string.
How would you prevent naming collisions?
The State Object node represents a single state object, that has a unique name within the simulation.
The term “simulation” was defined as a function. As such it looks like it is a runtime-only concept (it would be the state that’s persisted, not the simulation itself), so to have naming of state objects (i.e. persisted data) depend on how they are grouped in simulations (i.e. runtime data) seems a bit strange to me. Of course there is “the node tree that constructs the simulation”, but that’s different from the earlier definition.
The signature of this function is
void operation(set_of_state_objects, environment, time_step).
What is the reason to give the set of state objects to the operation? ‘Set’ implies that they are unordered, which is fine, but wouldn’t most operations just do a foreach(state in state_objects): do_operation(state, env, time_step) anyway?
The Merge node performs the union of an arbitrary amount of incoming state object sets and outputs the new set.
Why are these nodes necessary? Wouldn’t it just be simpler to be able to plug multiple State Object nodes into a single Operation node socket?
In some cases, that is fine, because the individual Apply Operation nodes do not influence each other.
This sentence is a bit strange, as “the individual Apply Operation nodes do not influence each other” doesn’t reference the “some cases” and thus is too general a claim. I would write “When the individual Apply Operation nodes do not influence each other, that is fine.”
I’d currently prefer to explicitly randomize the order.
Same here; having things explicitly unreliable helps to make the end result predictable.
The goal of the second feature is to reduce the amount of necessary Apply Operation nodes.
Nodes are countable, so it’s “number of”, not “amount of”.
This can be done by making the Operation input and output sockets in some nodes more dynamic.
How do you see this UI-wise? Would there be two sockets, one for objects and one for operations, that are mutually exclusive? Or will you have a third socket type (“object or operation”) that changes the output socket type depending on what is plugged into it?
The location of the simulation object does not influence the simulation itself. It just changes where in the viewport the simulation data is visualized.
What kind of data do you expect can be visualized in a location-independent way?
By having simulations as normal object, they can be integrated into the depsgraph fairly naturally.
This is not dependent on being an Object; any ID datablock would work.
Simulation depending on Objects
In this section it looks like you want to add a node for each (rigid body) Object in the simulation. Would these nodes be added by the user? Or would they be managed by Blender in response to some settings in the Object properties panels?
The data path includes the name of a state object in the simulation and the name of the actual data in this object. Remember, a state object is just a key-value mapping with strings as keys.
How would you make it possible for the UI code to limit selection by data type? Would this be encoded in the keys, like we do with ID datablocks?
Linking
In the case where a simulation is linked into the scene, would it be read-only? How would it handle running the operations when the State Objects are linked in? What would happen when you save the blend file?
Either, every value has to come with functions to serialize and deserialize it
This is typically done for every value type. Would you really want to have each value come with these functions?
Once a simulation is cached, it will not have any incoming links in the depsgraph anymore.
How about the time source?
2 Likes
@DanielPaul Thanks for the link. However, there is no need to send me links to TwoMinutePaper videos. You can be sure that I’ve seen them.
@sybren Thanks for the detailed feedback. Will respond to the more conceptual things here and fix the linguistic issues in the document afterwards.
This is actually something I discussed with Sebastian and Omar already. Somehow we have to initialize the state objects before any time passed. I’m aware of two different ways to implemented this:
- Have a separate function, that initializes all state objects with some data. Users will need to customize that function. So, a second node tree might be necessary.
- Use the same
simulatefunction and define thattime_step == 0means initialization. Some operations care about that, others might not. A solver-operation would return immediately. An operation that attaches e.g. a 3D scalar grid to a state object does not care whether the simulation is initialized in that moment (it attaches the grid only if the it does not exist already).
Out of these options I simply picked the second, because it seemed to work better.
The set of all state objects is known statically. When there are any name collisions, we can use the usual Blender approach and concatenate the names with .001, .002, … I think state objects will have a string input socket, that can be passed into a group from the outside if necessary. If the user depends on the fact that a certain state object has a specific name, it is in the responsibility of the user to use unique names.
You are right. The state object is not “in” the simulation, but “in” the runtime-data of the simulation-object. The simulation function simply takes a set of those state objects and modifies them.
Yes, they are unordered. It might be that most operations just loop over the objects, but certainly not all. For example, a Rigid Body Solver operation will have to look at all the incoming state objects at the same time and figure out which dynamic/static meshes should be used. So even if only a single operation has to do more than simply loop over the objects, the signature has the allow that.
Yes, that would be simpler. In fact, this is what I do with the Influences in the new particle system. Some more aspects to consider:
- People are very sceptical, when they see this for the first time in Blender. I guess that is mainly, because they are not used to it.
- Merge nodes are still useful to reduce the number of long links in a large node tree. They could be considered to be syntactic sugar in that context.
- In my last post, I was considering to use the order of inputs in the merge nodes to define a total order of the Apply Operation nodes.
- We could have a new kind of socket, that is scaled along the y axis. This can indicate to users, that this socket can get multiple inputs. Furthermore, this socket could still define an order of the connected inputs.
- Working with sockets that have multiple inputs is a bit tricky in Blender currently, because the node editor tools are node really designed for that. This can be changed of course, but is not something I wanted to get into right now.
The node would have one input and one output socket. This socket can change its type depending on what is connected. I’ve been working on similar problems quite a few times by now. This document is a little bit outdated already, but still related.
I assume it does not make sense to visualize location-independent data in the 3D viewport. A grid view similar to the outliner works better for this kind of data. Not sure if I understand your question correctly.
True. Having it as an object has other benefits, but is not strictly necessary.
They can be added by the user, and probably have to be added by the user in the beginning. Various tools that automate building the node tree in the background are possible and will have to be implemented as well.
I would not encode that in the string key. I could imagine that the key into the key-value-storage of each state object is a (string-key, value-type) pair. That would allow multiple values to have the same string-key, which I’d like to avoid. Another solution is that the type is simply stored with the value. UI elements would just have to filter based on a type specified in UI code. How to do that efficiently is mostly a data structure question and not too difficult, I believe.
I was under the impression that linked objects can still have runtime data. Since the runtime data is not stored in DNA, it should work.
You are right, these functions should come per value type.
You might be right that this input in the depsgraph is still necessary. I have to think more about that.
5 Likes
Simulation as Object Type
A solution that seems to work quite well in many regards is to introduce a new object type (like mesh, curve, etc.) for simulations. The simulation data attached to simulation objects is first and foremost the node tree, but possibly also other properties.
What exactly do you mean by object type? For a mesh object for example, there is both a mesh datablock and an object datablock of type mesh referencing it.
I can see how you might have a “simulation” datablock, that is referenced by one or more mesh object modifiers. And I can see how you might want to add an object referencing a simulation datablock for the purpose of visualization / analysis.
But is there another purpose, or would it just be an optional thing for visualization and the simulation datablock by itself would already work?
Hi @jacqueslucke et al,
great that a new simulation framework design for Blender is being worked on! You may want to check out VTKs Visualization Pipeline docs for reference. Although I don’t think it’s a “simulation framework”, it has the concepts of data objects, process objects (operations), connections, loops, implicit and explicit execution etc. It is very powerful for scientific data processing.
Edit: Removed question about other framework suggestions.
What I mean in the proposal is that there is a new object type + a new ID data type, exactly the same as it is for meshes.
I think most of the proposal should still work without having an simulation-object-type, but only a simulation-id-type. I’m not against this approach, but here are some more aspects to consider. Btw, I did not put all the different aspects into the document for every sentence, because that would confuse too much and I probably would not have been able to finish the document.
- As object type, simulations would have the same visibility settings as other objects and can be part of collections. This might be useful for scene organization.
- As object type, simulations would be selectable (which might or might not be a good thing).
- As object type, simulation settings would be displayed in the object data tab in the properties editor. This can be considered more consistent.
- Dynamic Operators (simulation nodes) are an “object type” in Houdini.
Besides these aspects, there are also downsides to having simulations as an object type. For example, many operators on objects are not very well defined for simulation objects. That is mainly, because the position of these objects does not have any impact on what is actually simulated.
When having simulations only as ID data type, we would have to solve the visualization and scene organization differently. However, I have no reason to believe that this approach could not work just as well or even better.
Thanks for the suggestion. However, I do not want this thread to become a list of links to other node system implementations. I did check a few and I will check more. People sending me links to other node systems should always be more specific about which concepts they like in these systems and how they would improve Blender.
Great proposal! I’d like to throw in a few more technical suggestions:
I think there must be a defined node evaluation order. Random order is in my opinion the worst option, since that would make the outcome non-deterministic. One solution for the node order problem that I like is the one in Cycling 74’s Max: The user can either rely on the implicit order, given by the location of the nodes (right to left) or the user can use objects such as trigger or bangbang which relay their input to multiple outputs in a specified order.
A long term request, if I may: In order to scale well to complex node graphs, I think the backend should not be implemented via C function pointers or an interpreter a la SVM. Ideally, I think, the nodes themselves would be written in a domain specific language and could be compiled with optimization (via llvm or similar). When a user strings together many small math operations to implement their own solver, a compiler could optimize across nodes and remove dead code, dead stores, possibly auto-vectorize parts of it. If I remember this correctly, the Bifröst engine does something like that. There’s also this presentation about (the now discontinued) Fabric Engine and their use of LLVM: http://llvm.org/devmtg/2014-04/PDFs/Talks/FabricEngine-LLVM.pdf
2 Likes
Would be better indeed. I’ll check a few more options. I’m fairly confident that this can be solved in a good way.
I spent a good part of the last year (and even before I started working for Blender) trying different approaches for evaluating such node systems in a good way. I did use LLVM for that in the past and can totally imagine to implement a domain specific language that uses LLVM for Blender in the future. Unfortunately, there are also a few downsides to relying solely on LLVM. The compile times can be fairly noticable (maybe I was doing something wrong, but they were higher than I expected). Debugging functions, that have been compiled at runtime, is difficult. Profiling is more difficult, because you can hardly measure the impact of individual nodes. For nodes, that do more than some simple math, using LLVM does not really provide any performance benefit, but increases complexity a lot.
For these reasons, I started developing a different execution mechanism. It can evaluate node trees efficiently without a time consuming compilation step, resulting in faster feedback for artists. The key idea (among many others) is to always evaluate a node on many elements at the same time (following data driven design principles). This makes the function call overhead negilible and allows for many optimizations on various levels.
Nevertheless, I agree that it can be very useful to compile some parts of a node tree. This can be done in an optional node tree optimization step. This optimization pass could analyze a node tree, figure out which sub-node-trees benefit from LLVM, and replace those with functions compiled at runtime.
Note, this system is optimized for throughput. While it can be used to evaluate a node tree only once, it really shines when a node tree is evaluated thousands or millions of times. This is the case I mostly care about for now, because I need it for the particle system. The system I developed in the first half of last year, was actually latency optimized. Unfortunately, it was pretty much at the performance limit, mainly due to function call overhead which could not be reduced much further. It was still quite fast and could easily deform hundreds of thousands of vertices in real-time, but it did not fulfill all my needs. This led me to replace it with a different system.
I’ll happily talk more about different aspects of this system in the future. All WIP code is available in the functions branch. If you have any questions, contact me.
7 Likes
I did some experimental work last year in offline texture generation (similar to substance designer), and also ran into llvm achilles heel there , the quality of the code it generates is great, there’s no argument there but getting that great code takes a little bit.
Once a shader graph was compiled the run time perf was fabulous, tweaking the parameters of a compiled graph you’d have a great time and you could rapidly iterate. However the initial compile (or recompile if you change a single node link) was easily taking a over a second for even the most basic of shaders. making the thing just utterly frustrating to use and worse the load times of a file when you had a bunch of these things shot through the roof.
I think that fabric guys also bumped into this cause otherwise they would not have settled on a two stage rocket (from the pdf linked by @StefanW)
Two-pass compilation
– First unoptimized compilation pass
– Fully optimized code generated in background
Not saying llvm is bad choice though, just confirming that the issues @jacqueslucke had are not an isolated event and that if we choose to use llvm runtime perf is not the only metric we should be looking at, and should probably deisgn keeping in mind llvm can be slow at times and try to mitigate that behavior from the start rather than at a later stage when we run into issues.
4 Likes
How do you plan to deal with user developed nodes?
For example I spoke with @scorpion81 about using this as the new system to implement FM in the future, but would it support custom programmed high performance nodes or will we still require a full blender compile to get new nodes/functionality working? (Ím thinking in some physics solvers or geometry solvers)
I also agree with avoiding the random execution as @StefanW said.
Great plan 
1 Like
This is one area of interest to me as well.
I work in the automotive assembly line with industrial robotics and CAD packages.
In my daily work we have many things which need to be developed that are, conceptually at least, equivalent to your definition of Simulation “Operation” Nodes.
Just the industrial robotics sector alone is a deep enough concept to span multiple problem domains. For instance, we have kinematic solvers that must be accurate to a tenth of a second to the real robot’s motion, and the implementation for each of these is vendor specific.
My best idea looking through this proposal would be a user-defined node that would create an api endpoint (possibly http) for the industrial robotics api to post joint values (in yaw pitch roll expression) for Blender.
Otherwise we would need a comprehensive development environment similar to what we have in our current commissioning packages, complete with custom robot logic parsing engine… there is a lot of depth to cover.
However, if we could author a node which could read the robot logic file and interpret using Python (which could be possible) then we may be able to explore Blender better there.
However, much of my reading has to do with Physics and mesh simulation in this proposal. Is there any proposal for logic nodes, similar to what we saw in BGE (on state change, AND, OR, XOR)?
Also would there be any provision for multiple simulations that run concurrently and how would the user specify that? I don’t think that making that judgement call implicitly would be such a good idea. It would need to be a user decision. We typically consider multiple robots running in parallel separate simulations even if the robots are in the same physical space (and therefore sharing phyics primitives in the software) because in reality the logic calculation and inverse kinematics solutions occur on separate hardware.
Anyways that’s my 2c from a domain that, admittedly may not be the best suited by this proposal.
1 Like
I read through the proposal regarding evaluation order and two things about how Houdini
works seem relevant.
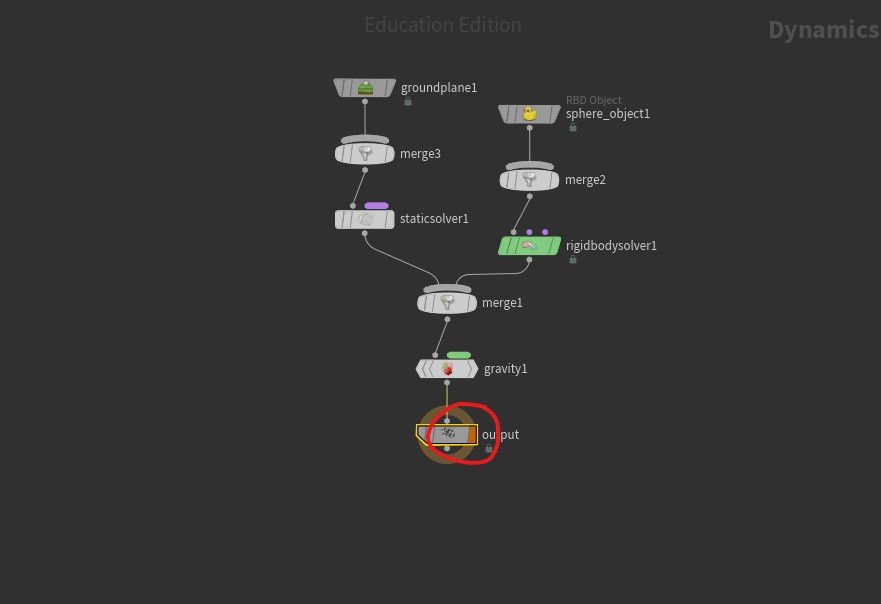
The output node of a Sim is marked with the orange output flag so there can be one and only one end point of the node tree. The second thing is tree traversal always follows up the tree and then left most input first so execution order is explicit. The Merge nodes let you easily reorder their inputs by moving the input up a stack just like how Blender modifier stack reordering works.
Unfortunately, even the unoptimized compilation using LLVM is too slow in many cases. I don’t like to add multiple seconds to the file loading time that is spend in code we don’t control…
A good short, medium and possibly long term solution seems to let users implement an operation via a Python interface. The user would have to implement a Python function like my_operation(state_objects: Set[StateObject], time_step: float). A StateObject instance has methods to access the key-value-storage of a state object. Access to underlying arrays has to be provided using Pythons buffer protocol. That will allow them to be efficiently processed by e.g. numpy or custom C/C++ functions loaded at runtime by an addon. Other, less trivial, value types need specialized Python wrappers, but that seems fairly doable. Using Python does introduce some additional locking when evaluating the depsgraph on multiple cores. However, since e.g. numpy and custom C/C++ functions can release the GIL while expensive computations are done, this is probably not a big issue.
I was thinking about the fracture modifier in the design process as well. I think it can fit into the proposal quite well. To a large degree this is because geometry stored in state objects can be (don’t has to be) decoupled from Blender’s Mesh data structure. Furthermore, a single state object can encapsulate a dynamically fractured object if necessary.
The only purpose of the node tree described in the proposal is to schedule operations on state objects. It does not propose a logic system yet. It might be good to have more domain specific node tree types for some use cases. For example, the behavior of agents within a crowd simulation could be defined in a separate node tree that is referenced in the simulation tree. It is the job of the solver to make sense of that other node tree. The following is just an example for what this might look like. I have not thought about crowd simulation more deeply yet.
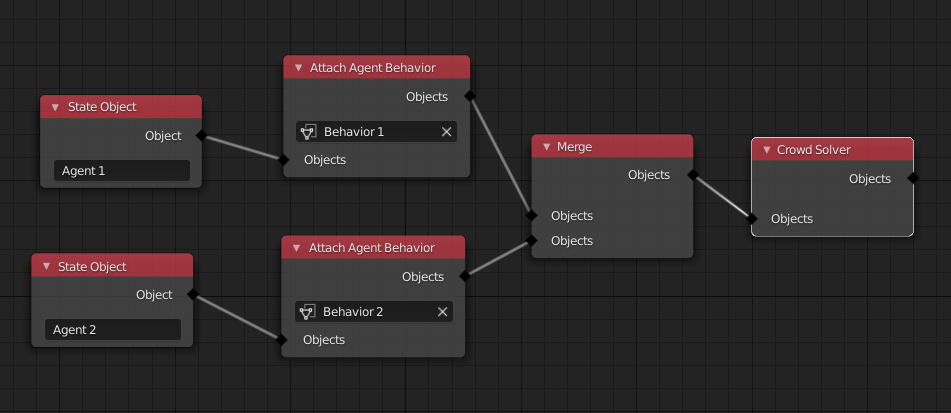
I can think of two ways multiple concurrent, but separate, simulations can be modelled with the proposed system. I’ll make the descriptions below specific to your example.
-
All robots are simulated within a single simulation. That means, that a single state object contains the state of multiple robots. The solver would update attributes of all robots in a single solve step.
-
Every robot is simulated in a separate simulation. That means, every simulation has one state object for one robot. Node groups can be used to share common nodes between all the simulation node trees.
For visualization, the simulated data can be imported to one or multiple separate objects regardless of which of the two approaches is used.
4 Likes
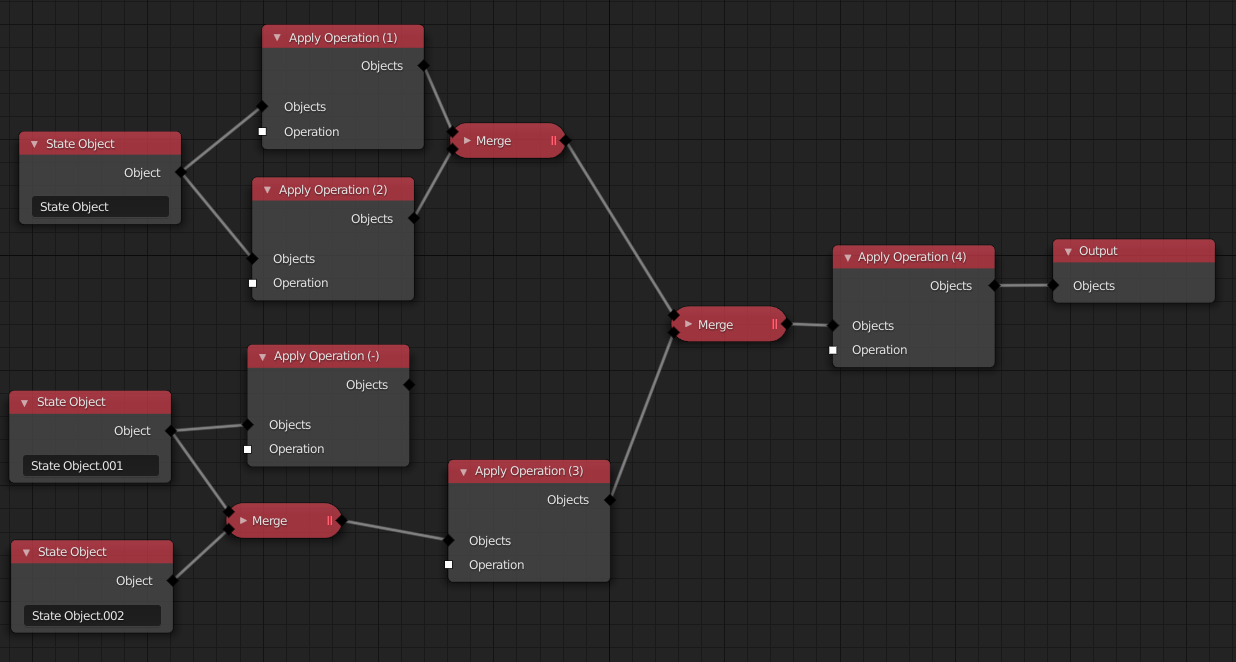
Under the assumption that we have a single output and that the inputs to a merge node are ordered, a deterministic schedule of the Apply Operation nodes can be found with this algorithm (given in pseudocode that I did not actually test):
def schedule_apply_operation_nodes(output_node):
if not output_node.inputs[0].is_linked:
return []
scheduled_nodes = []
schedule_apply_operation_nodes__impl(output_node.inputs[0].origin_node, scheduled_nodes)
return scheduled_nodes
def schedule_apply_operation_nodes__impl(current_node, scheduled_nodes):
if is_merge_node(current_node):
for origin_node in ordered_linked_origin_nodes_of(current_node):
schedule_apply_operation_nodes__impl(origin_node, scheduled_nodes)
elif is_apply_operation_node(current_node):
if current_node not in scheduled_nodes:
input_socket = current_node.inputs[0]
if input_socket.is_linked:
schedule_apply_operation_nodes__impl(input_socket.origin_node, scheduled_nodes)
scheduled_nodes.append(current_node)
The numbers in the Apply Operation nodes indicate the order in which they are run. Note, there is one node that is not run at all. This aspect of the algorithm can be used to “mute” a set of apply operation nodes by not connecting them to the output.
3 Likes
I can definitely see that being the de-facto way of doing logic nodes, but my only worry would be that in my domain of robotics and virtual commissioning there can be many, many thousands of signals.
What we tend to do for robotics and virtual commissioning is very, very simple and our use case would be very strongly supported for debugging purposes by the visual node type system proposed here.
Although I have no place saying what must be in it, I can only strongly encourage that logic nodes be considered for the proposal due to how powerful they could be and the fact that Python really would not be necessary for most cases. For things like specific IK solvers and the like, a custom node would be required, but for 98% of what we do in robotics and industrial controls validation (evaluate boolean and play an animation / apply force-torque based on the result) having boolean operators would be amazingly powerful.
100% agree with this. In fact, much of the logic we use daily is canned (copy and paste) logic so I was wondering what provision there would be for instanced logic (copied node maps maybe with less overhead?) and nodes which themselves contain nodemaps. The latter would be very powerful for us in that we could make precanned logic and provide it in a node that contains a nodemap that only displays a comment. This would allow us to make a general description of what complicated logic might do for those not in the know, but would not take up nearly as much space visually.
I love this part of the proposal in particular because it really does emulate the types of things we do very often. We have a lot of things that work on state, as you say “muted” in that they are simple monitors, debug, etc and don’t output anything.
Is there going to be a provision to append simulations or node maps (which I guess is just my word for a specific subset of a simulation) from one Blender file to another the way we can specify a library Blender file that appends to projects today with the append function?
Sorry, hope any of that made sense. I understand that I am speaking as an advocate for a very specific problem domain but I think these problems (boolean filter, simulation append, simulation-in-simulation) are pretty general, at least in the abstract. I think a lot of areas could benefit from their inclusion. In this way we would make a lot of this pretty similar to Cycles nodes and Animation nodes (at least I think).
Thanks for the awesome progress! Final question, are these actual screenshots from the interactive branch? Or just mockups?
1 Like
Few things to consider (not sure if you’ve got these covered already):
-
Variable time steps. System could support changing length of time steps that are simulated between frames. Maybe specify via curve like in graph editor? Anyhow, this would be useful for e.g. switching from normal speed to slow motion. Maybe even allow negative time steps?
-
Maybe consider to support interdependent simulations. By this I mean coupled simulations, which need to pass and map information between simulation domains, e.g. fluid-solid interaction. For this there is PreCICE library which may be useful.
-
Support for level of details. Some way to affect how coarse or fine simulation is wanted (quick preview sim, medium level sim or slow very detailed sim). Variable spatial definition of LODs somehow?
-
Support for parallel simulations (both among simulators and within each simulator, definition of how to access and divide local and remote computational resources).