Precision Drawing Tools (PDT) does that through the Parts Library Functions, the display of the library file assets is automatically updated and includes, Objects, Collections and Materials at the moment.
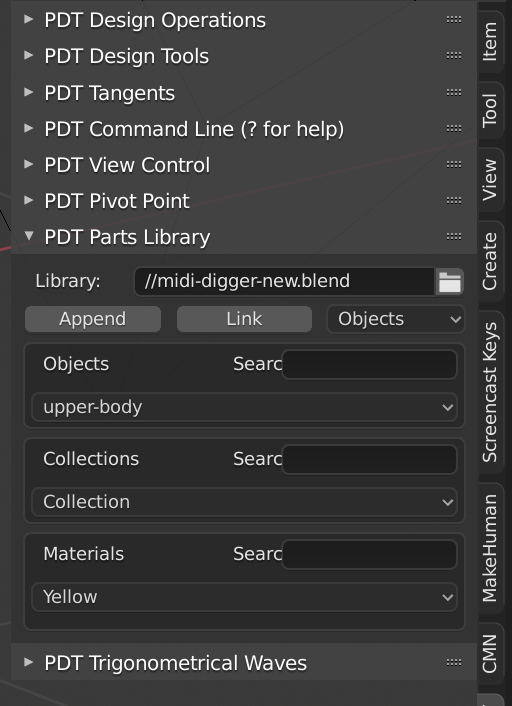
PDT ships with Blender after 2.82 release, full details can be found on this thread (a lot of reading), the Wiki provides some info, but is slightly out of date in that the Library file is now specified in the Parts Library menu, not the Add-on Preferences, that is on my ToDo list.
You can either Append, or Link, things from the current specified Library file BTW. Appended objects are put on the current cursor location.
Cheers, Clock. ![]()