Hey, I’m walking through a directory to find a blend file, but I need to get all the collections it contains. Since it’s possible to go into the Collections folder it must be possible to list the contents
import bpy
import os
assetDir = "H:/Shared drives/Proj/2_PRO/Assets/Props/"
section = "\\Collection\\"
load = "Bench"
for root, dirs, files in os.walk(assetDir):
path = root.split(os.sep)
for file in files:
if file.endswith(".blend"):
path = root + "/" +file
directory = path + section
filename = load
try:
bpy.ops.wm.link(
filename=filename,
directory=directory)
except:
pass
So this will check if the collection exists and link it in, but how can I list the contents.
Doing “os.listdir(directory)” will return a fileNotFound error.
It’s important to list the collections without linking them into the scene first.
this is unsurprising because the contents of a blend file are not part of your filesystem. you have to open the file to get to its contents. once you’ve loaded it, it’s trivial to examine the collections using the data api.
Ah, it turns out that loading datablocks is temporary and they get removed upon reloading the file, so it doesn’t strain the system as much as I thought it would. Thanks for putting me on the right track
Turns out datablocks don’t get cleared so easily. I load the files to get their inside collections
with bpy.data.libraries.load(path) as (data_from, data_to):
data_to.collections = data_from.collections
#print(list(data_to.collections))
data[path] = list(data_to.collections)
But then they all stay in blender, and even after reloading not all the links are removed.
Is there a way to purge everything without users? I tried to do it manually but even that didn’t work completely & and the linked libraries still stayed.
for obj in bpy.context.scene.objects:
if obj.type == 'MESH':
obj.select_set(state=True)
else:
obj.select_set(state=False)
bpy.ops.object.delete()
for block in bpy.data.collections:
if block.users == 0:
bpy.data.collections.remove(block)
for block in bpy.data.actions:
if block.users == 0:
bpy.data.actions.remove(block)
for block in bpy.data.meshes:
if block.users == 0:
bpy.data.meshes.remove(block)
for block in bpy.data.materials:
if block.users == 0:
bpy.data.materials.remove(block)
for block in bpy.data.textures:
if block.users == 0:
bpy.data.textures.remove(block)
for block in bpy.data.images:
if block.users == 0:
bpy.data.images.remove(block)
for block in bpy.data.cameras:
if block.users == 0:
bpy.data.cameras.remove(block)
for block in bpy.data.armatures:
if block.users == 0:
bpy.data.armatures.remove(block)
for block in bpy.data.curves:
if block.users == 0:
bpy.data.curves.remove(block)
for block in bpy.data.lights:
if block.users == 0:
bpy.data.lights.remove(block)
I just want to list all colections cleanly and then get rid of anything that was imported
Hi, I’m curious if you ever found a solution to this. It seems natural to store objects in one .blend file and append them to any other file using an addon. For that to work, I’d need to list out the objects the source file contains so that the user can select one with the addon’s UI. Is that possible to do without hard coding the list?
Hey Jonathan,
Unfortunately I never found a good solution in terms of loading in and clearing the links.
Are you making a library? If so I definitely wouldn’t recommend storing all the assets in the same file. It will get too large and cluttered to modify. In bigger teams it would also mean that people need to wait for someone editing an asset to save, only so that they can begin editing a completely unrelated asset.
However if you do that, it’s easy to go through all the asset names and print them to a file, then you can read the list from another script if you need. It’s what I do with my plugin. I load all my blend assets from different blends into an empty document, write all their paths to a file, and then search through the file for a path when i want to load in a specific asset.
If you want I can mail you the plugin (but it’s not really ready)
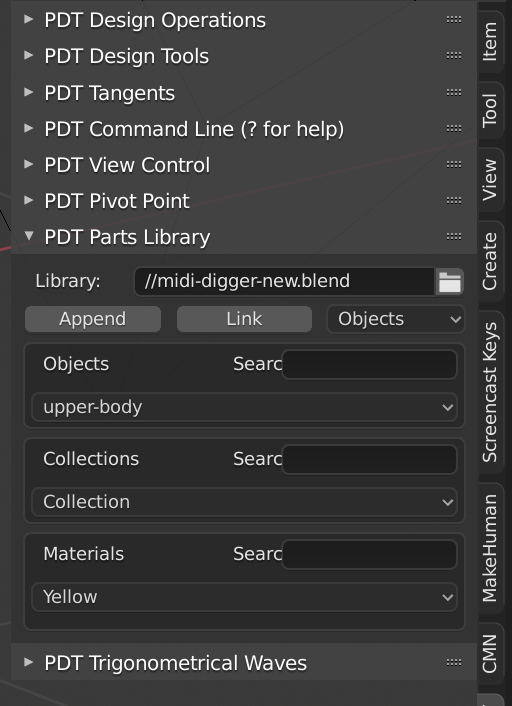
Precision Drawing Tools (PDT) does that through the Parts Library Functions, the display of the library file assets is automatically updated and includes, Objects, Collections and Materials at the moment.
PDT ships with Blender after 2.82 release, full details can be found on this thread (a lot of reading), the Wiki provides some info, but is slightly out of date in that the Library file is now specified in the Parts Library menu, not the Add-on Preferences, that is on my ToDo list.
You can either Append, or Link, things from the current specified Library file BTW. Appended objects are put on the current cursor location.
Cheers, Clock. 
@clockmender Please don’t advertise your plugins here. This thread is about a specific problem of traversing blend files and writing collection paths onto files. If you have tips on how to cleanly load and unload datablocks then please share the knowledge
Hmmm, curious comment, I am not advertising anything here, if you look at the code I used you will see how I read the various data from the blend file. Forgive me if I am mistaken, but didn’t you advertise your plugin here?
1 Like
This is how I see it, since you’re talking about a completely other plugin, and not about python specifically. I didn’t advertise anything, i offered to send my code form my personal plugin which isn’t available and which this thread is about.
I’ve looked through your github wiki and what your plugin does is not related to what my plugin does. My plugin reads all blend files in an Asset folder, and stores paths for all props, so that any prop can be quickly loaded in by typing it’s name in the asset editor, without having to search for blend files and traverse them manually.
The issue which I’m having is that creating the path storage file requires linking and unlinking collections which leave behind datablocks that stay even after a reload, thus weighing down the file with data which isn’t used.
So, you can’t make the leap from reading all the assets of one blend file to iterating through a folder of blend files and doing the same for each blend file therein? I’ll leave you to sort it out then. There are ways to read blend file assets easily from a blend file path without having a write list to external files and trying to keep those lists updated.
I was only trying to help you with this remark:
Referencing a method to do this was my only intention, pity it backfired on me, I am out of here.
1 Like
Throw insults at me because I thought your og comment was off topic, very mature. I’m sorry, but I don’t consider “you can look through my code” helpful to any degree, especially to someone who isn’t really a programmer like me.
Making a list is a more efficient way of working with production libraries with 20+ blender files and hundreds of asset files because searching through a txt is faster. I’m indexing a library.
I ended up doing a similar thing to @Blendermonkey and created a script that exported the names and info of the objects to a csv file, which I can read with the addon. However, if there is a way to easily get the info from the file directly without appending anything first, that would be great.
Here’s the code from your addon that I think is relevant, that I think is appending:
scene = context.scene
pg = scene.pdt_pg
obj = context.view_layer.objects.active
if obj is not None:
if obj.mode != "OBJECT":
error_message = PDT_ERR_OBJECTMODE
self.report({"ERROR"}, error_message)
return {"FINISHED"}
obj_names = [o.name for o in context.view_layer.objects].copy()
file_path = context.preferences.addons[__package__].preferences.pdt_library_path
path = Path(file_path)
if path.is_file() and ".blend" in str(path):
if pg.lib_mode == "OBJECTS":
bpy.ops.wm.append(
filepath=str(path),
directory=str(path) + "/Object",
filename=pg.lib_objects,
)
for obj in context.view_layer.objects:
if obj.name not in obj_names:
obj.select_set(False)
obj.location = Vector(
(
scene.cursor.location.x,
scene.cursor.location.y,
scene.cursor.location.z,
)
)
return {"FINISHED"}
So in my situation, I think I’ll stick with the .csv export. Thanks for the help, both of you 
2 Likes
@Blendermonkey @jonlampel
So, to actually answer the question  . This is surprisingly easy. The below code will return a list of the collections in the library file without loading the collections themselves. The same method works for materials, objects etc. The trick is not to set data_to as this is what actually loads the collection / object etc. into memory
. This is surprisingly easy. The below code will return a list of the collections in the library file without loading the collections themselves. The same method works for materials, objects etc. The trick is not to set data_to as this is what actually loads the collection / object etc. into memory
import bpy
def get_collection_names():
assets_path = "C:/somepath.library_file.blend"
names = []
with bpy.data.libraries.load(assets_path) as (data_from, data_to):
names = [name for name in data_from.collections]
return names
3 Likes
Exactly the point I was making by asking OP to look in my code…
The only variation I use is to use a simple _ as data_to so it doesn’t even load it. This also avoids your code linter moaning at you for not using a variable…
if path.is_file() and ".blend" in str(path):
with bpy.data.libraries.load(str(path)) as (data_from, _):
if len(pg.object_search_string) == 0:
object_names = [obj for obj in data_from.objects]
else:
Oh yes, I forgot, “Welcome to DevTalk!”
Cheers, Clock.
3 Likes
Oh, interesting. That is way more simple than I thought. Thank you!
Thanks, I’ll use that trick. Its a pity its not possible (as far as I know) to be more selective about what you pull in from a library file when linking to it, as I’m still finding myself having to store metadata for collections / objects etc. like author info and tags in a separate .json file as well as as a PropertyGroup on the collection or object.