This document proposes to remove the ability to dump MemFile undo steps as .blend files. This is done for auto-save. This slows done auto-save but allows for more optimization opportunities.
Background
The undo system in Blender uses the same serialization code that is used for writing .blend files. Essentially, it’s currently creating an in-memory .blend file that is restored whenever the user wants to undo. On top of that simple approach, there are a few optimizations that to reduce duplications between undo steps and to avoid full depsgraph evaluations after undo.
This approach generally works well and is not subject to debate here. However, there is one additional aspect which was originally a good idea but is now causing some problems and limitations. Blender has auto-save which by default saves the current state every 2 minutes. This should be fast, because if it’s not, it causes annoying (short) freezes of the UI.
To make it fast, Blender currently just dumps the last MemFile undo step to disk as a .blend file. This way, the auto-save code does not have to serialize all Blender data again, which results in better auto-save performance.
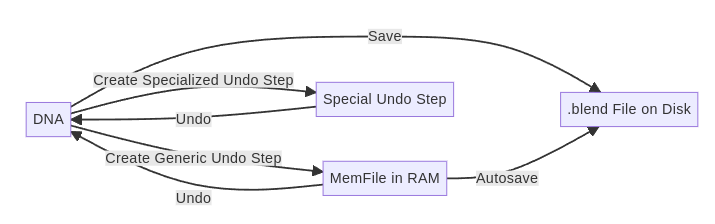
Downsides of Current Approach
Unfortunately, this approach to auto-save also has some downsides which is why I propose to remove the ability to support saving undo steps as .blend files. The most prominent downsides are:
- Not every undo step is a
MemFileundo step. For example, when in in mesh edit mode, a different kind of undo step is used. This also means that auto-save is currently essentially ignoring all changes done while in these modes, making it an unreliable tool. - It makes it much harder to optimize undo because every undo step also has to be able to become a valid .blend file with little overhead.
Possible Undo Optimizations
There are a few concrete things we already do or want to do to improve undo performance which would benefit from the proposed change:
- Skip forward compatibility conversions. Some features in Blender have been implemented with explicit support for forward compatibility. That usually means that Blender stores data in an older format in .blend files so that older versions can read them. At run-time the new storage format is used. This conversion step makes saving and reading files slower. When creating a
MemFileundo step, the conversion should not be necessary because only the current Blender session has to be able to read the data again. Therefore, skipping the conversion for undo is reasonable. Unfortunately, when saving such undo steps as .blend files, the resulting file is quite different from what you’d get when saving normally, which is unexpected and has lead to bugs in the past already. - Skip writing some data to the
MemFile, e.g. by using implicit sharing. This can make creating undo steps and undoing itself much faster. There is other data that doesn’t have to be written to undo steps, for example theSDNA. It’s likely that we’ll see more such optimization opportunities.
What should auto-save do instead?
Instead of using the MemFile for auto-save, we would use the normal saving code instead. This is generally slower than the current approach. From testing it seems that the auto-save time triples in the worst case.
This sounds quite bad, so there is definitely a trade-off between faster auto-save and faster undo. Fortunately, there are also a few things we can do to improve the auto-save situation again.
How to make auto-save less annoying?
The longer auto-save takes, the more annoying the unexpected freezes of the UI. There are quite a few things that were already done or can still be done to improve the situation:
- The most obvious approach is to just make normal saving faster. The design of .blend files allows writing them fairly efficiently. If we get normal file-saving to be bottlenecked only by disk-write-speed, it should have close to the same performance of the old auto-save. In this I started experimenting with serializing ID data blocks in parallel to achieve higher throughput.
- We could skip some things we do for normal file saving like calling
BKE_lib_override_library_main_operations_createwhich is essentially just a fail-safe. Skipping it should still generate valid files. - Restart auto-save timer when saving manually. This makes it so that people who have a habit of saving all the time anyway never get a frozen UI due to auto-save.
- Improve perceived auto-save performance by trying to find a better moment in time for auto-save where it is less intrusive. There are a multitude of different heuristics that could be used to improve the user experience.
- Notify the user before auto-save happens. For example, the status bar could show a count-down starting 5 seconds before the auto-save. The user could cancel it by saving manually. This way, the auto-save freeze is less unexpected, and it even teaches the user to get into the habit of saving regularly manually.
More suggestions are welcome.
Can we make the undo optimizations work without the proposed change?
In theory it is possible to write skip implicitly shared data and forward compatibility conversions when writing the MemFile. When saving it as .blend file, we would then still have to do the forward compatibility conversions and insert the shared data in the middle of the MemFile. This still wouldn’t solve the missing data when e.g. in mesh edit mode, but it could solve some problems.
While this works in theory, in practice it’s quite tricky. So tricky in fact that we likely wouldn’t implement some undo optimizations because it’s not worth the complexity. Another issue is that this code path would be rarely tested in practice. Only when it really matter, i.e. when the user has lost work due to a crash, the auto-save files are read back into Blender. I’d feel better knowing that auto-save is just a normal save. So as long as normal save works, auto-save also results in a valid file.
Conclusion
In the end it is a trade-off. Personally, I’ve come to the conclusion that undo performance matters more than auto-save performance, simply because it happens more often and affects more people. The extra work we currently do for every undo step allows auto-save to be faster but it comes at a cost that I think is not worth it.