I’ve been researching IDProperties because we plan to use them to store values for node
trees in geometry nodes. I have found the system quite complicated, and there seems to be
some consensus that the way they are implemented is a bit of a hack. Maybe my perspective
is naive, but it’s also the perspective of someone encountering this for the first time
who would rather build on top of a solid base.
Mapping Between IDProperty and RNA Types for UI
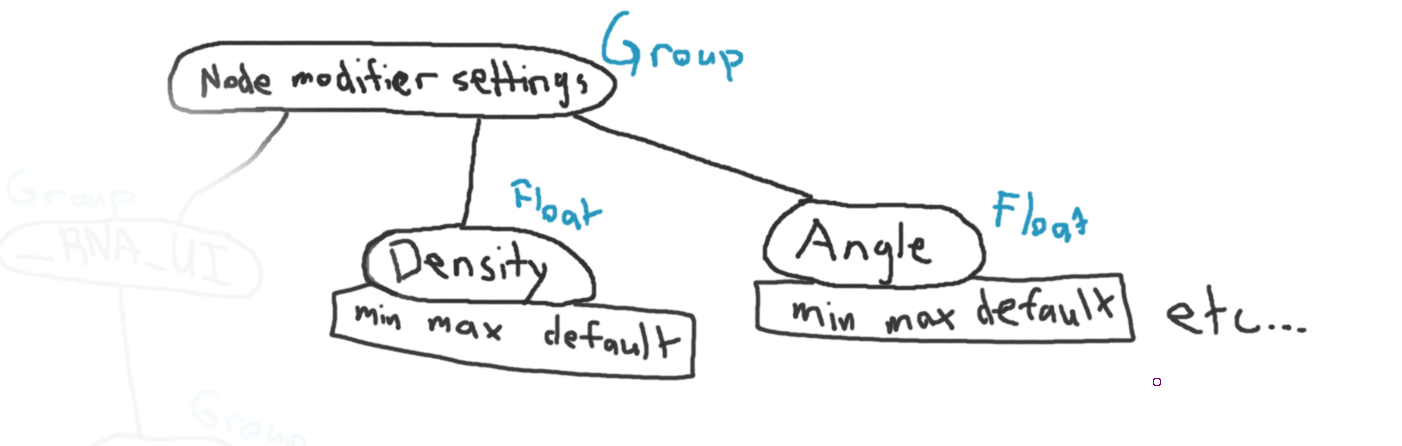
Currently, in order to get information like RNA’s PropertySubType, min and max,
description, etc, the code actually builds a group of properties, with a parent group
property and a child group property for every value in the following chart. This means
the UI code has to do a string lookup in the group’s children for every one of these
values for every layout pass.
| Value Type | IDProperty Name | IDProperty Type |
|---|---|---|
| Subtype | subtype | IDP_STRING |
| Description | description | IDP_STRING |
| Int Min | min | IDP_INT |
| Int Max | max | IDP_INT |
| Int Soft Min | soft_min | IDP_INT |
| Int Soft Max | soft_max | IDP_INT |
| Int Step | step | IDP_INT |
| Int Default | default | IDP_INT |
| Float Min | min | IDP_DOUBLE |
| Float Max | max | IDP_DOUBLE |
| Float Soft Min | soft_min | IDP_DOUBLE |
| Float Soft Max | soft_max | IDP_DOUBLE |
| Float Step | step | IDP_DOUBLE |
| Float Precision | precision | IDP_DOUBLE |
| Float Default | default | IDP_DOUBLE |
| String Default | default | IDP_STRING |

While there’s an argument for doing it this way-- it reuses the existing “groups”,
I get the impression it causes more problems than it “fixes”. There’s a change I’m
missing something though, and there’s a good reason these values are defined this way.
Proposal
I propose adding these fields directly to the IDProperty struct. While they are maybe
not always needed, it would be a small price to pay for the convience of properly storing
these values.
I suggest storing these values in a “UI data” struct, with polymorphic type specific structs to store
the values unique to each property type.
Versioning would have to be considered with these changes. To simplify the process,
these changes could be implemented step by step.
Adding an IDProperty
Currently there is the large IDP_New function, which handles the creation of every type
of IDProperty. It takes a multi-purpose union as an argument. For obvious reasons this
is not so nice to use.
typedef union IDPropertyTemplate {
int i;
float f;
double d;
struct {
const char *str;
int len;
char subtype;
} string;
struct ID *id;
struct {
int len;
char type;
} array;
struct {
int matvec_size;
const float *example;
} matrix_or_vector;
} IDPropertyTemplate;
Proposal
I propose splitting up IDP_new and instead using a separate function for each type.
There could be a template struct for each function as a clean way to pass arguments.
Along with the changes I propose in the previous section, a call to create a new int property would look more like this:
IDPropertyInt *prop = IDP_new_int(name,
&(IDPropertyTemplateInt){
.rna_subtype = PROP_PIXEL,
.min = 0,
.max = 100,
.soft_min = 0,
.soft_min = 10,
.default = 5,
.step = 5,
.decription = "A description",
})
Obviously in many cases all of those values wouldn’t be defined, so it would be shorter.
The Name
I think the idea was that these properties were only supposed to be added to IDs, but that isn’t true anymore, and it just confuses the idea.
Proposal
I don’t have a better name idea right now. Though IMO it’s a lower priority change anyway.
The function names in BKE_idprop.h should also be changed to conform to the style guide.