Blender already ships with the sun position addon, so maybe that add-on could be extended to support the sky texture node
The sun position add-on already supports the sky texture node.
3 Likes
Doesn’t look like a robust implementation, you can’t “sync sun to texture” since it asks for an Env texture, and also even if you sync by eye (because z rotation doesn’t match) and then “bind texture tu sun” you still can change texture rotation independently and can’t have sun disk visible.
1 Like
Will sky textures in blender is going to have exposable input parameters anytime? because its impossible to make a node group, its really needed for having custom nishita sky with clouds or other additions  It mustnt be hard to do it
It mustnt be hard to do it
1 Like
Unfortunately that’s not possible because of the way it is currently implemented. This has already been answered in the past in this thread.
2 Likes
Ohh its too bad Thank you still for the kind reply, Sorry for asking it twice
2 Likes
So I have read the whole thread…and I couldn’t find an answer to my question:
- What value should I put in the “film → exposure” setting to get a properly lit outdoor sunny day scene ?
All I could find was that arbitrary 9.416 value to calculate real world EV in the “color management” exposure side.
- Is there any formula to convert real world EV values to that Film → exposure setting ?
I’m asking this because the intensity patch note is recommending it:
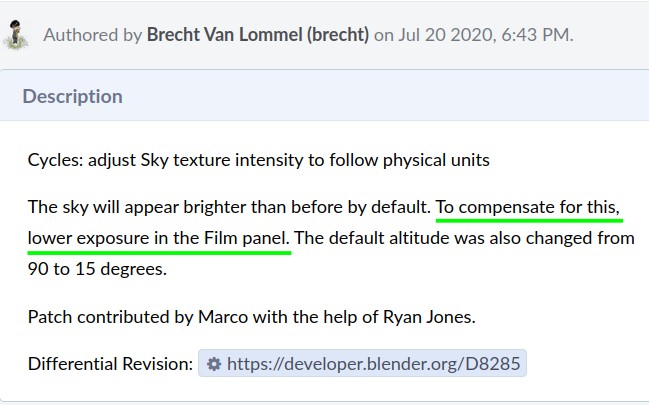
And the recent adaptive sampling patch note is further recommending it instead of the color management one.

Also while we are at it, can somebody explain to me the reasoning/math behind the film exposure slider ?
It can go from 0 to 10 with 1 being the default o_O ? “here I give you from 1 to 10 to overexpose your scene, but you can only go from 0 to 1 for all your underexposing needs” ?
At least the color management one can go from -32 to +32 with 0 as default (clamped at +/- 10 if using the slider).
Why I’m putting all this here ? simply because this is the only blender feature that makes me want to even touch any exposure related setting.
5 Likes
At least on the Cycles “film” exposure setting, I believe it’s just a simple scale factor. Aka, it multiplies every pixel by the number you type in the box. As opposed to the color management slider, which abstracts things through stops, so it multiplies the image by 2^n as opposed to the input value itself.
1 Like
I found this post by @troy_s on stack exchange from 2016 explaining the difference between “Film - Exposure” and “Color management - Exposure”
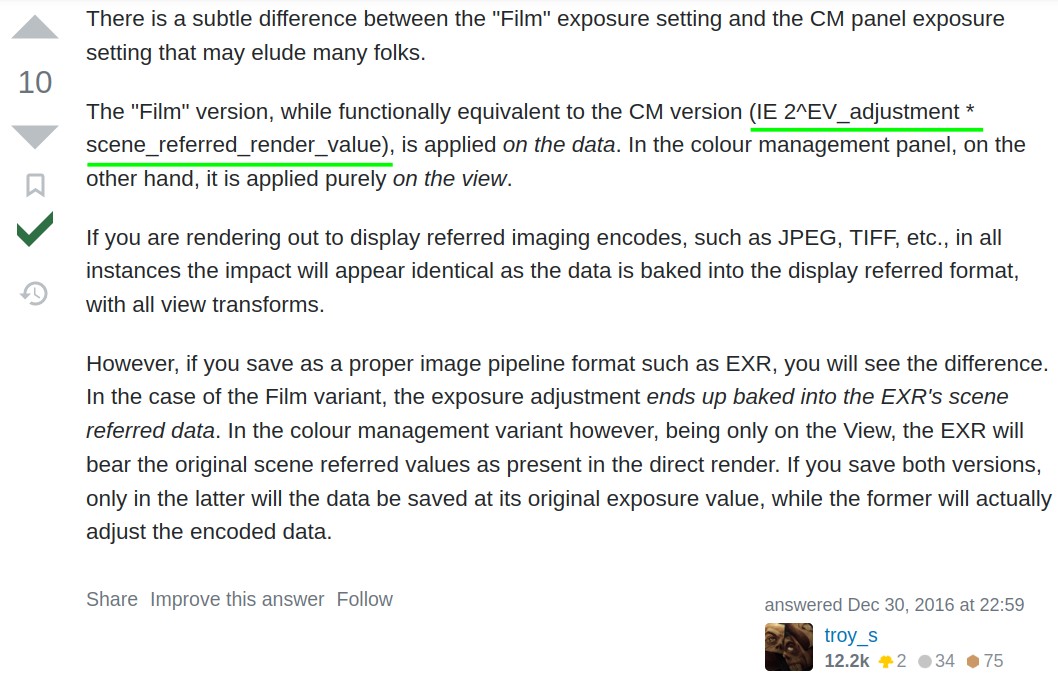
Idk how up to date that formula is, nor do I know what to with it to figure out the proper value to type in.
If it is indeed the same math behind the scenes, then they should also have the same range (+/- 32) which they clearly don’t have.
3 Likes
They both multiply the pixel value, they just use different conventions for the scale. Using p for pixel value, and n for the user specified value:
Film panel: p * n
Color management panel: p * 2^n
That’s why they have different value ranges despite effectively doing the same thing. The other differences is that the film panel affects the render output itself, the color management adjustment is just an on-the-fly scale performed when converting the scene-referred data into the output image.
2 Likes
Dev of the new adaptive sampling patch I am. Rendering with Cycles is:
Render → Multiply by film.exposure → Compositor → Color management.
- Calculate light data for each pixel;
- Multiply the resulting image (in linear space) by film.exposure. 1 - returns same values, 0 - pitch black, 10 gives a brighter result;
- Compositing. Brightness levels from the previous step affect the result of non-linear nodes, e.g. “Greater than 0.5” node;
- Color management (e.g. with Filmic). The result is taken from the compositor and is used to form an image. It has its own contrast and exposure (I don’t actually know why it is needed) controls. Here exposure is in f-stops: 0 means no change, -3 means multiplying by 1/8, +4 means multiplying by 2^4 = 16.
Now a tricky part. Adaptive sampling measures an error in each pixel and if it is smaller than a threshold sampling is stopped. But our eyes are more sensitive to noise in brighter, though not in overexposed areas (which are even clipped often). This is taken into account by giving more weight to pixels with R+G+B>1.0 and lower weigth to darker pixels. These are the same RGB values which you’ll get as an input in the compositor. That’s why you should aim your render to have a correct exposure before compositor and color management - it gives a perceptibly optimal (kind of) noise distribution on the render.
When you created a scene and set up all the lights, adjust film.exposure. Note that if you multiply all the lights and env in the scene by X and divide film.exposure by X it should produce exactly the same render, including noise pattern. Which is not the case, if you adjust colormanagement.exposure instead. Though, the cost of the error is not high - barely one can distinguish suboptimal noise distribution on the render, and if you can, you would just lower your adaptive sampling noise threshold and get a clean result with a slightly longer rendering.
2 Likes
Not sure where you arrived at this conclusion, but I am unsure of the veracity of the claim?
Noise is a relation to signal, and in terms of a picture, the information can be expressed colourimetrically as the tristimulus measurements presented in the picture, via the output medium.
This means that the opposite claim carries weight. The reason that photometrically “darker” values are easier to detect noise in is due to the amplitude of variations. In the darker regions, small amplitude variations carry much more tremendous visual impact. Conversely, at the higher end, small deviations will be less detectable.
This all requires incredible attention to the mechanism used to form the picture, but the general trend should hold.
1 Like
This entire evaluation of noise should be moved to after view transform, otherwise you are hardcoding a certain open domain (0 to infinity, pre-view-transform) value to be “bright” or “overexposed”. Think of how problematic it would be if, say, we support HDR displays in Blender’s OCIO config in the future (Where the light sabers are allowed to stay colorful instead of attenuating to solid white). Basically what you assume to be “nearly clipped” will be shown as clear as day in that image formed for HDR display.
Ideally anything noise-related including noise threshold evaluation, denoising etc., should be moved to after view transform, the evaluation of “what is noise” is completely determined by the view transform (I.E. the image formation). I have come to the conclusion that the attempt to measure noise level pre-view transform will be extremely ineffective.
I mean just look at ACES vs TCAMv2 and see how the same open domain Cycles outputed data can have different noise level depending on which view transform you use:
ACES:

I don’t mean to talk about color shifts but look at the noise appeared in the purple region.
TCAMv2:

Look at how different the noise level is.
“What is noise” is influenced greatly not only by the dynamic range of the view transform, but also how the view transform attenuates the chroma. Therefore, the evaluation of noise should be after view transform (I.E after the image formation).
Like you said, the parts of the image that has been “overexposed”, that are attenuated to solid white, doesn’t actually need that many samples. But if you think of the situation where you have HDR display support, you will start to see how a fixed assumption of a certain open domain vlaue start to fall apart. Or in a situation like above, where the amount of noise differs depending on the view transform, the assumption is also doomed.
Ideally we need to have the algorithm looking at the post-view-transform image to evaluate noise level, instead of arbitrarily down-sample above a certain open domain intensity.
So, we should remove this broken assumption:

Whether open domain R+G+B > 3 (like open domain RGB [1.5, 1.5, 0.5]) is overexposed, depends on the view transform, “noise” is only seen by users after view transform. So this assumption is deadly wrong.
Instead, move noise evaluation to post-image-formation, then the issue you have with “oversampling the solid white” should be resolved.
2 Likes
Fully understand, fully agree technically speaking, however this is really really tricky to do, as that suddenly means the render itself depends on the chosen view transform.
You have to do the potentially expensive view transform already at rendering time, and if you switch the view transform after the fact, you are essentially invalidating the noise bounds you set beforehand.
While those assumptions could instead be user-tunable parameters (perhaps hidden in some advanced-options menu), I don’t think on a technical level, that a post-transform evaluation is possible.
It gets even worse if you also have pre-transform compositing which further affects what noise is visible. If you wanted to do this perfectly right, you’d have to take into account the entire compositing chain, pre-formation and post-formation and everything. Then you could make actual guarantees on the noise levels as seen on the final image.
But compositing can get arbitrarily heavy. This simply is not feasible at all.
So I’m afraid some sort of heuristic is gonna be needed.
But yeah, at least make it tunable and even optional, so if there ever is a scene where you really do need more samples in highly exposed areas, you can decide to have them.
Thing is, people noticed a lot of slowdown from high exposures with very little visual difference (post view-transform) and started doing silly things like artificially constraining the dynamic range just to get stuff to render faster. And that’s not the sort of thing you want people to do either. If anything, that’s worse.
Rendering for HDR displays in the future is gonna challenge all sorts of assumptions I’m sure. This definitely being one of them.
I think another thing that could kinda challenge this even in SDR sRGB is the fidelity of caustics, now that Cycles is starting to see some serious caustics in certain situations
Maybe one “proper” way around this could be gradient-domain path-tracing, where you set rays specifically at areas that change quite a lot, leaving uniform regions relatively less carefully sampled. I think that can be combined with regular path tracing using MIS. To my knowledge, Cycles does nothing of the sort today.
https://www.cs.umd.edu/~zwicker/projectpages/GradientPathTracing-TOG15.html
As far as I understand it, this would kinda ignore both dark and light patches if they are rather uniform, thereby being a kinda more principled approach to this issue than this simple cutoff idea.
And a semi-recent survey:
https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.13652
(sadly couldn’t find an easy access version tho)
6 Likes
OK I see the problem now.
But the default shouldn’t be this low. The current assumption believes open domain RGB [1.0, 1.0, 1.0] (R+G+B =3) to be the threshold for overexposure. This is broken.
If we take Filmic/AgX’s dynamic range into account, you should at least put Max(RGB) = 16.1 as threshold. Maybe we need to leave some rooms for compositing, so maybe Max(RGB) = 20. But still, if we have HDR display support this will fall apart.
2 Likes
That is a reasonable request, yeah. 3 is an awfully low cutoff.
1 Like
The original Cycles implementation followed guides from section 2.1 “A hierarchical automatic stopping condition for Monte Carlo global illumination”.
Sorry for being unprecise, I meant relative error, of course. Whether the original claim itself holds and to what degree - I find it controversial a bit as well, but couldn’t find an extensive research on this. Anyway, it’s an old Cycles assumption tho.
2 Likes
I agree with you 100%. Although these estimations should also include compositor with all the nodes like blur, image lookups, posterizers and so on. Brecht suggested that it is not practical so far, especially considering that compositing might be done after the rendering is done.
As for which parts are considered overexposed, actually it is better to say that all the intensities in the open domain are treated equally and given the same attention (unlike before the patch), except for a small range 0-1 that is given a bit less samples because usually it lands to the specific sweet spot (in terms of brightness) of the rendered image. At least it should.
In my tests with benchmark scenes I found that cutoff R+G+B = 0.5 is even better, but I also found it too extreme of a change while making little to no difference to performance. Look, if the brightness is above X it doesn’t mean that it’s not going to get any samples at all. It just means that it will get as much samples, as a pixel with some mid-range brightness.
When you say about high dynamic range you should also consider that brightness range above 1 is squeezed into the image by having a low to very low contrast. That’s why you can get away with even fewer samples here. It still can bite you from the compositor, so it was chosen to have the same attention as midtones.
2 Likes
I strongly suspect this one, at least as stated, isn’t gonna be practical ever. There simply is no bound on how complex compositing might be. Imagine waiting for a second on a single sample - not sample per pixel, but a single sample. One singular ray. And you do that just to figure out whether the image is sufficiently denoised. This simply can never work. At those speeds you are better off just doing more samples than strictly needed, just to be on the safe side.
The best you could perhaps do in the future - and this may actually be feasible - is to like train up a specific adaptive sampling schedule for your specific compositing needs, and then use that.
Like, imagine the various AI denoisers got adaptive sampling counterparts. You’d only need a (relatively) little bit of possibly really really slow tests, and then the AI could go “I get the gist” and move faster from there.
Could even, perhaps, jointly train an adaptive sampling schedule, and a denoiser for your specific scene + compositing needs.
This is the sort of thing I could see happening in the near-to-mid future.
Right now, doing this requires massive amounts of compute. But what currently is a service NVIDIA and others can provide to optimize results, basically by pushing drivers that are tailored to any given software, in a few generations of hardware upgrades and algorithmic improvements could be a thing you do in a minute on your computer at home.
Not yet though. For now, all we could hope to do is to improve the current decidedly flawed heuristic.
“Midtone” only exists post-view-transform, it’s a closed domain concept, there is no “midtone” in open domain, when you claim there is, you are making assumptions that won’t work.
Brightness is a challenging concept in image formation
There is also no “brightness” in open domain, only tristimulus intensities. When you claim there is, you are making assumptions that won’t work.
Let’s not see it as “squeeze”, but rather, attenuation of chroma. And note I mentioned support for HDR display, basically means you don’t need to “squeeze” that much because those display devices can emit stronger lights by nature. You light sabers don’t have to be solid white (whether light sabers with colorful cores are aesthetically desired is another topic.)
The point is, the current assumption of “overexposure” is too low, it should be at least Max(RGB)=16.1 (and even that would be problematic in the long run), if higher threshold makes the optimization negligible, then this intensity based sampling method should be optional and turned off by default.
3 Likes