Hi,
I would like to transform the Attribute Statistic node into a field node. I think it creates a lot more usecases, because you could get the statistics of indiviual elements of the geometry rather than the hole domain. I had many moments when this would be very handy.
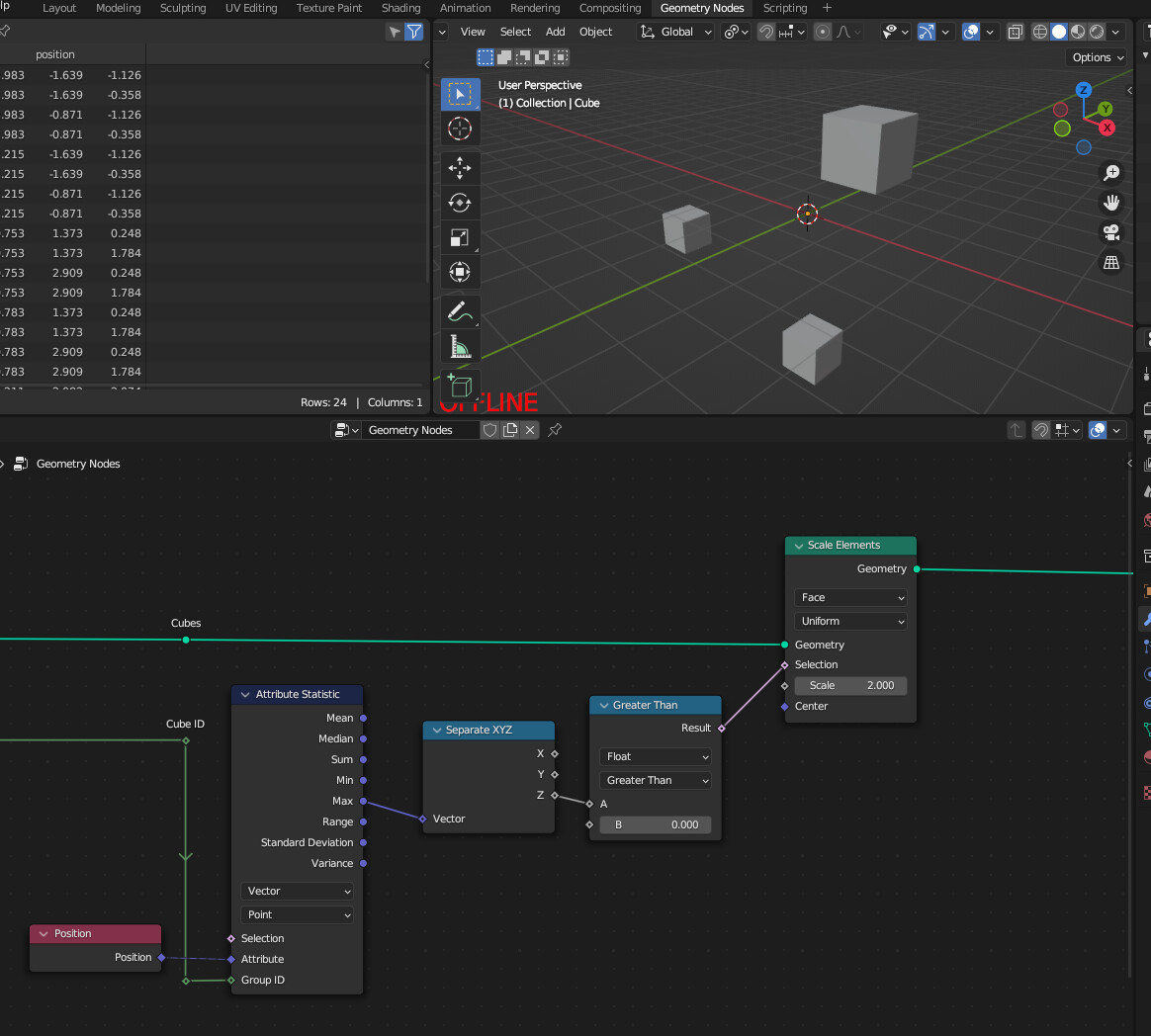
It could look something like that (All output sockets are fields):
Changes:
- add Group ID (Inspired by “Index of Nearest” Node)
- remove Maybe Remove Selection socket, because it would be controlable by the GroupID or the evaluated mesh
- remove Geometry socket, because its not needed for fields
- remove Domain enum
Iam very new to blender development and c++ but, i would like to try. But before i develop something which is against the plans of geonodes, I wanted to get a discussion going, what the best way of implementing this would be.
8 Likes
I think this is a good idea! The hardest part is keeping the same behavior as before though, existing files should keep working. It’s possible to change existing node groups in versioning code. There should be a way to do that keeping behavior the same, but I’m not sure exactly what that would look like here.
The selection socket is probably redundant technically, but it is a nice convenient feature for things like “get the average color of all particles above the surface of the ocean” or something. I’d probably keep it.
1 Like
Puh, didn’t think about conversion of old node trees. I’ll look into that.
Your right the selection socket would definetly be more convenient. Wasn’t sure if redundancy is “allowed” in geonodes.
Edited the original: I think the domain info enum isn’t needed anymore
I found a problem with the node. The original node allows generating data that works on any domain without any problem. This would be difficult, if even possible with the new node.
Maybe a new enum or switch would be needed. This would allow switching beetween the current mode (non field) and the new mode (field). But not sure about this, because I think this was never done before in GeoNodes:
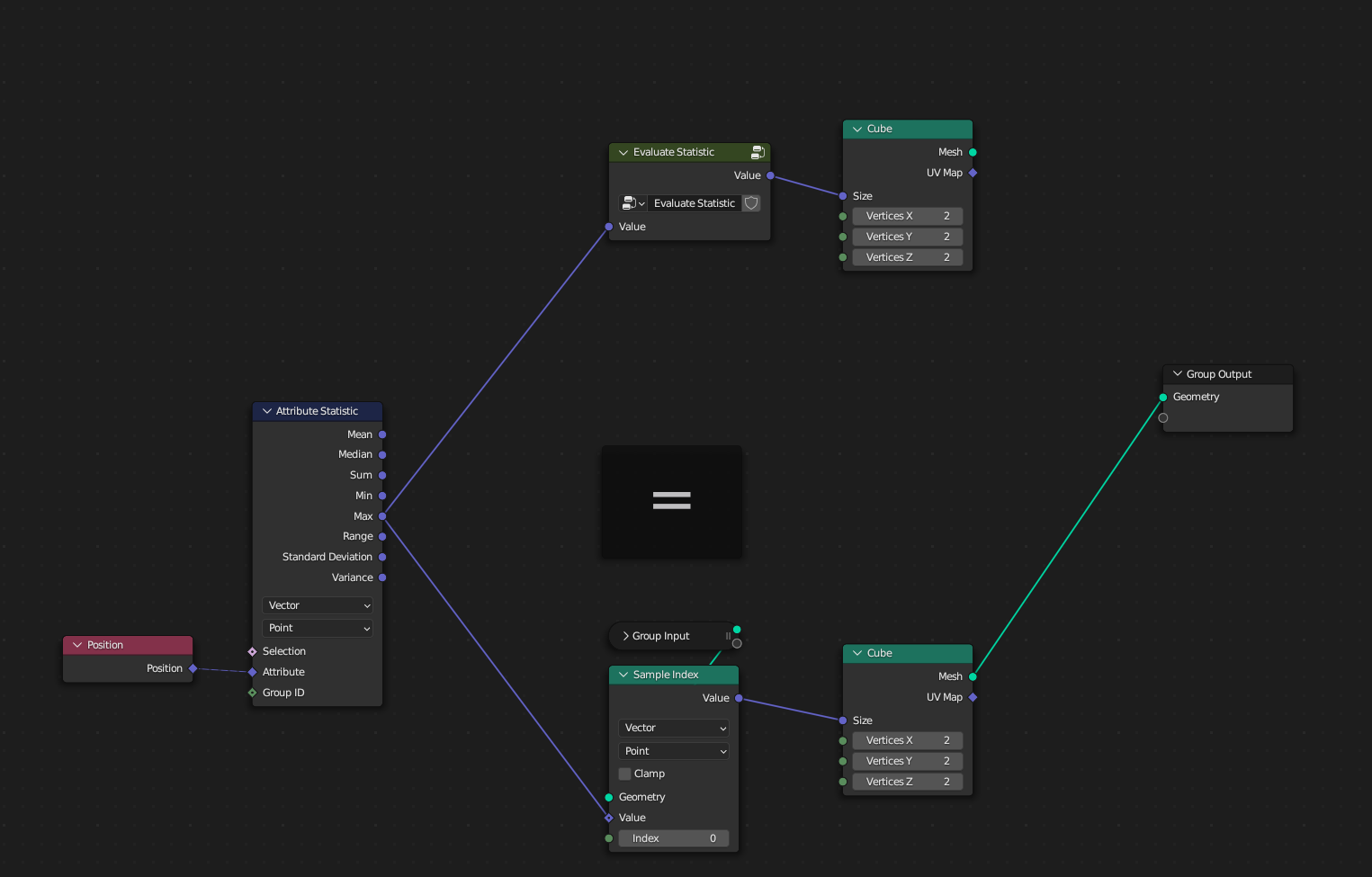
Just add Sample Index node during versioning. Sampling can be from any index…
You’re right. It would work, but maybe not as straight forward than the current Attribute Statistic
Statistic attribute / evaluate statistic value nodes?
When you have to add a sample index node you have to know that the sample index node can be used for this case.
When you only want the global attr. statistic, the new idea would be more complicated when you have to use the sample index to retreive the output.
But I’ll have to look into the sample index node. Because it can output both: field and non field. Maybe the attribute statistic could behave the same way. When there is no group ID defined it would return a non field data, which wouldn’t need the sample index node, behaving like the current attr. statisting.
I mean, potentially you want to make another node of Evaluate group:
-
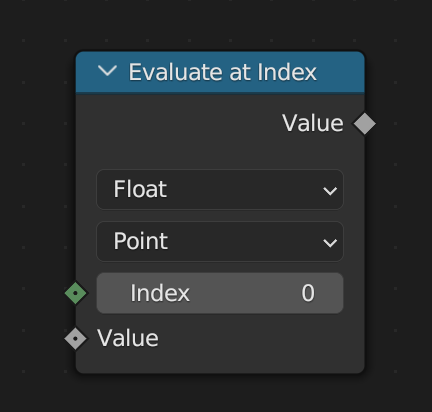
Sample Index / Evaluate at Index.
-
Capture Attribute / Evaluate on Domain.
-
Sample Nearest / Index of Nearest (hm… it something to me to think…).
-
Attribute Statistic / Evaluate Statistic.
Ah I see, what you mean by “Evaluate Statistic”. Iam not sure if creating a new node, is necessary. Wouldn’t it work if the Attribute Statistic can return both: “field data” and “non field data”.
I think it’s more consistent if a new node doesn’t do both. Generally we try to avoid nodes that fundamentally change their inputs and outputs based on an option.
Okay, so do I understand it right, that the “evaluate statistic” would be equal to a sample index?
I don’t know about adding “evaluate statistic” just for this use case.
Maybe a “evaluate sing”, which checks if all values in the field match, if so it returns the value. if not it gets red. Basicly a field to non field converter.
“evaluate statistic” will be equal to a evaluate at index
This reminded me of the grouped statistics node: Blender Archive - developer.blender.org
Its very similar.
The difference would be:
This one: changing the current node to work for fields and groups and add a new node to get the old behaviour
The other one: Create a new node that is only for fields. Also it seems it warnt sure if there should be a enum for the statistic type (max, min,…) or add all sockets to the Output (like the current attribute statistic)
Ok thanks. I’m not sure I understand, how are two nodes necessary? can’t you use the “field statistics” without a group input, and get the same behaviour as the current “statistics”?
@HooglyBoogly said this about this behaviour. Maybe you wouldn’t need an extra option, like I said before. It could auto check if there is only one group, like you said @Hadriscus.
I’m not sure why it is necessary that the node changes inputs or outputs. Why can’t it return a field in all circumstances?