Since this is related to the animation module now handled by dr.Sybren I’m tagging him.Although it might be just a python API thing @sybren
So as I’m fiddling a lot with keyframes. I inevitably end up dealing with fcurves.But I was wondering why is there two ways to accessing keyframes. Is this repeating data? or just two paths to the same.
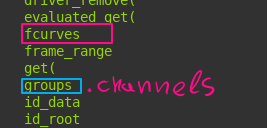
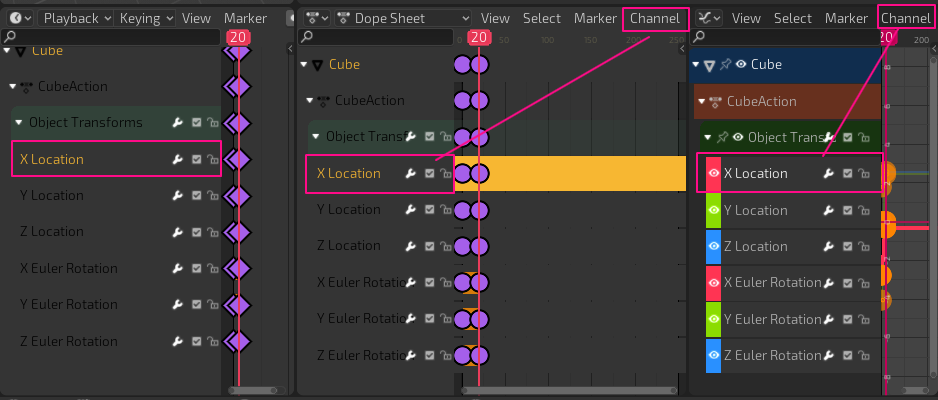
One way is through object.animation_data.action.fcurves[i].keyframe_points and the other is more in line with what we see in the graph editor and dopesheet, which is - object.animation_data.groups[i].channels[i].keyframe_points . Again both work but I feel like the second is more accurate with what we have in the dopesheet, and gives more accurate way to distinguish between channels/fcurves. Was the fcurves way an old data path? That is still hanging around?
Which brings me to another point about fcurves/channels.
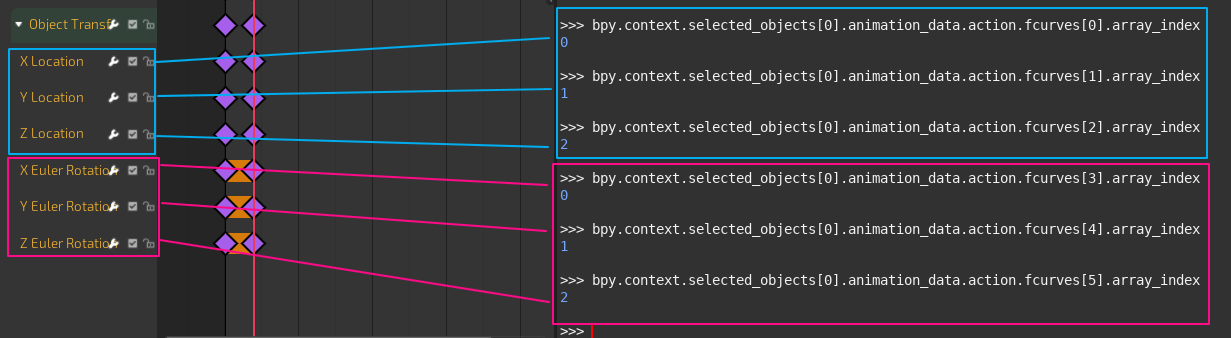
Right now the out of the box way to identify fcurves/channels is with .array_index. And that would be totally fine if blender actually gave each fcurve/channel it’s own unique index. But instead I would get 0,1,2 for location and 0,1,2 for rotation etc. . But sometimes it will actually work right and give me 0,1,2 for location and 3,4,5 for rotation etc. . Still it’s obvious that if take that index and store it along with some values, and apply it later. In the cases where it gives me 0,1,2 for every set of three fcurves/channels , it will modify all fcurves/channels with that index…thus all.
So I’m wondering… since we have user editable names for objects and we can reference them with object.name. Since we have user editable names for action and can reference it with action.name. Since we have user editable names for groups and can reference them with group[i].name . Why can’t we have an fcurve/channel.name instead of .array_index, which more often than not, is identical with other fcurves/channels.
At the moment I’m working around this issue with using fcurves/channels[i].data_path and concatenating that with the array_index and I get something like “0.location”,“1.location”,“2.location”.
I’m thinking, considering that in the dopesheet we have non user editable(hardcoded) identifiers for channels like “X Location”, “X Rotation”, “X Scale”. why don’t we have a fcurve/channel.name , in which we have the proper channel name string?
Note that this just happens to match for i=j=k=0, that isn’t generally the case. There is no more/less accurate way, as both paths lead you to the exact same objects in memory.
Right now the out of the box way to identify fcurves/channels is with .array_index .
You cannot consider array_index separate from data_path. FCurves can only animate a single numerical value, so when the animated property is multi-dimensional (3-dimensional for positions and Euler angles, 4-dimensional for quaternions) the array index is relevant. So, to animate the Z-location location[2], you’d have an FCurve with data_path='location' and array_index=2.
If you want to format a string in a way that it’s likely to be unique, use something like f'{fc.data_path}[{fc.array_index}]'
@sybren
yes your comment is what I already know. My question is:
Don’t you think there should not be array_index and data_path ,but instead .name . Which will reflect the name we see in the dopesheet or the timeline. We could still have the purely programmer friendly .as_pointer() for the advanced API users.
I just think array_index is a bit obsolete and useless on it’s own ,especially when you have the same array_index for fcurves/channels ,but in different data_paths…like all the transform channels have.
And for the Channels thing…what’s the point of having two paths to the same thing…especially if both paths are part of the same object, on the same level.
I think it’s better to force the user to go through the groups to access the fcurves, and I think it’s better to have the fcurves be only referenced as channels. Especially when even in the graph editor they are listed as channels.
No, because data_path and array_index are for the animation system to do its job.
I just think array_index is a bit obsolete and useless on it’s own
It’s vital. data_path points to an array, and array_index points to an entry in that array. You can’t have one without the other. X-position is location[0], Z-rotation is rotation_euler[2] and the W-component of a quaternion is rotation_quaternion[3]. The array index comes after the data path, not before it. It’s not for ordering FCurves in some array, it’s for declaring what the FCurve is animating.
And for the Channels thing…what’s the point of having two paths to the same thing…
The animation system itself doesn’t care about groups, so having one list of all the FCurves that apply to a certain object is the simplest & fastest way to evaluate the animated values for a given frame.
Still the python API is for user interaction with blender. Why should the user care how the animation system works. I mean, especially when from his point of view, the data_path and the array_index is split in to two properties. And nowhere in the API it is marked that these two properties should go hand in hand. I mean to me I already solved the problem by making the data_path+array_index thing(an unnecessary extra step I think). But I just think that it will be better for the user to have a .name property that reflects the name we see in the UI. In what possible way might the user benefit if he has array_index and data_path? Sure the animation system works that way, but from the user’s stand point…he just wants to pick data from this data block and put data back to it. And from his stand point he is interested in taking data based on an fcurve’s name i.e “Location X”,“Rotation X” etc. Not "data set <location>, fcurve <index 0>".
Anyway I see your point …that’s how the system works,and you can still differentiate between fcurves based on data_path and array_index. I just think an unnecessary extra step, that we force the user to do, without any real benefit, compared to a more clear property that will reflect the UI and will give the user a combined name of data_path + array_index from the get go.
Such a .name property would have to be read-only, otherwise you could name an FCurve that animates the X-location to Y-location and get all confused. If you want to find an fcurve by data path + array index, just use the ActionFCurves.find() method.
Yes a .name function should be a read-only. It’s not like the user can ever change the name from the UI.
Also Blender also automatically renames channels if they are given different data_paths.
Just tested it and moved the the location.0 fcurve to euler_rotation data path. and now I have 2 fcurves that are part of the euler_rotation data path with the same array_index but with different fcurves for the same property. Isn’t that messing things up?
Anyway…let’s end this discussion here. Don’t want to lose any more of your and my time.