I don’t know if I like or dislike this proposal, but I do have something I want to say.
A friend of mine discussed with me his idea of making Fields nodes backward compatible (besides my previous idea about just let the old nodes working without showing in Shift A menu), is to automatically have the old nodes convert to some equivalent node groups. I also experimented a little bit and it’s totally doable:
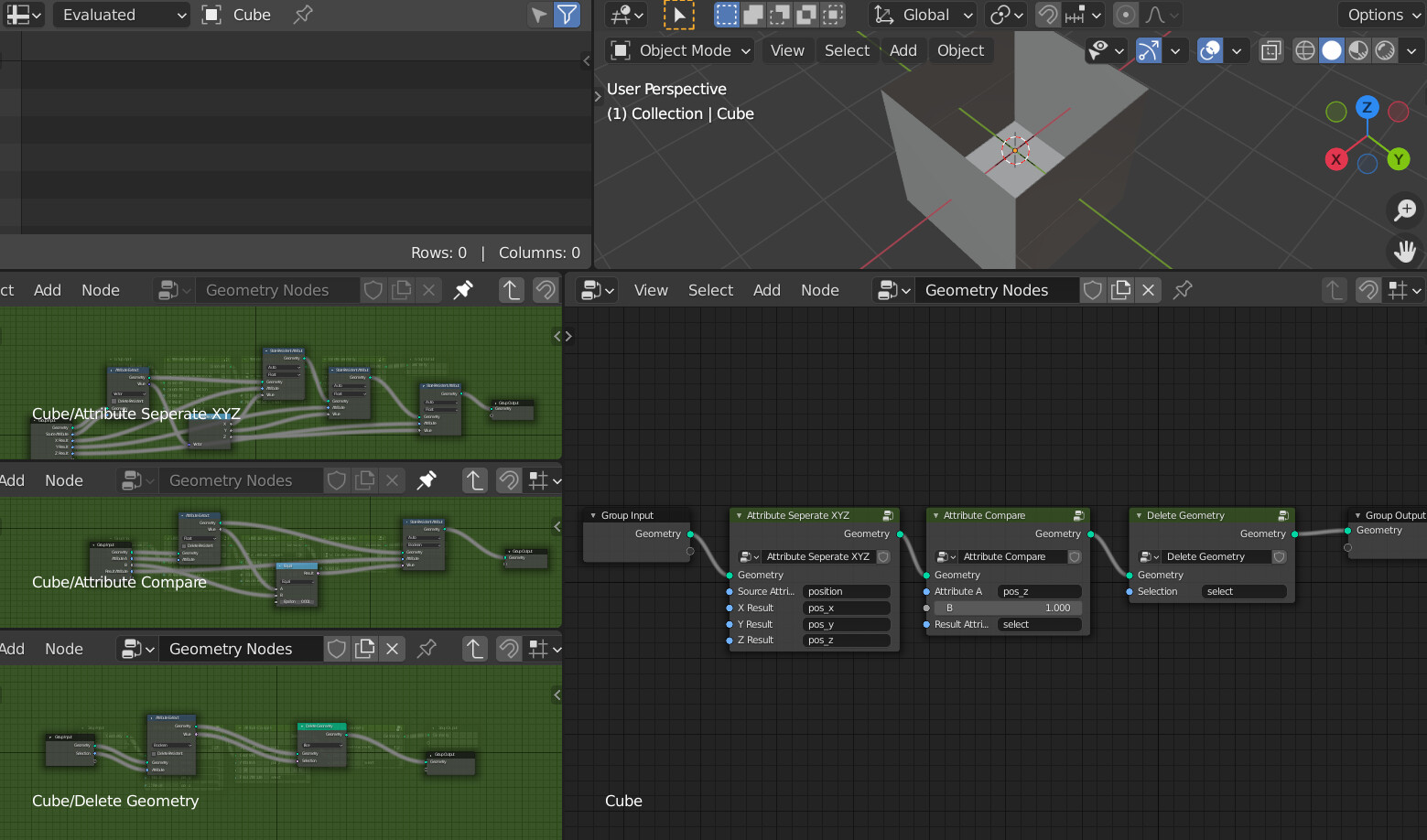
But with this proposal,
I think this means this idea of Node Group for backward capabitilty just not possible anymore?