Since it’s not ok to mention other software implementations it’s kind of hard for me to explain this 
But this concept has been widely used.
What I mean is that you can create a parameter or an attribute at a scene level and use that attribute in all the node trees you have in the scene.
That parameter would not be created inside a node tree, since the scene does not have a node tree, but rather in a “atrribute pool” where you can create random parameters that can be freely used by any tree.
Picture it like a custom parameter of the scene that can drive many settings in different node trees.
For example, an age parameter for a forest scene, you would have several distribution / modeling trees in that scene, for Tree A(model), for Tree B(model), for trees distribution / forest creation, for bushes, for peebles, for water level, and I can imagine a ton of things more that can be procedurally created with nodes.
Then in the scene you have a parameter that we will call “Age”, all your trees can access that parameter and modify their results based on that parameter, if you want the tress to be young, the forest to be in it’s incipient point with just a few trees, more water or less water, more or less pebbles, etc… since all the node trees can access that scene parameter, they can be driven by affected by it.
That would be the scene parameter pool, something shared across all the scene.
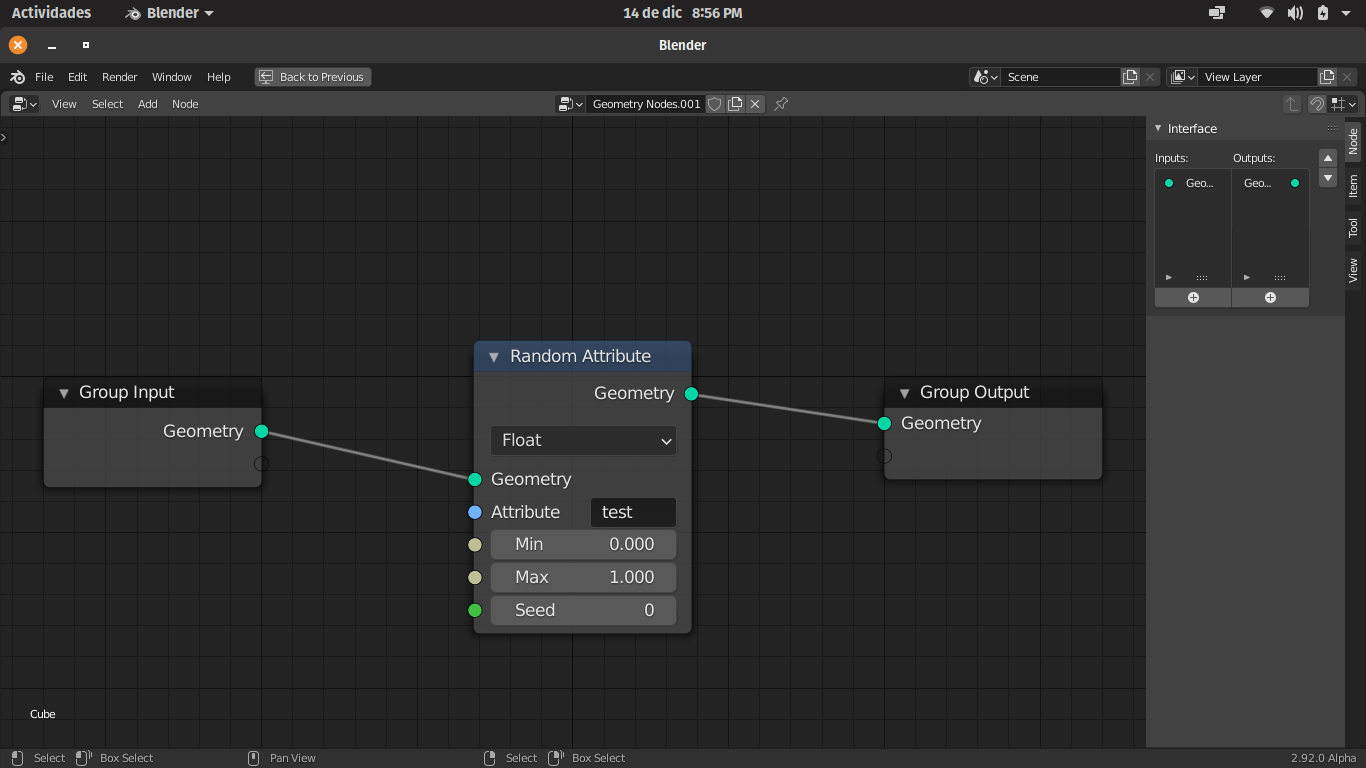
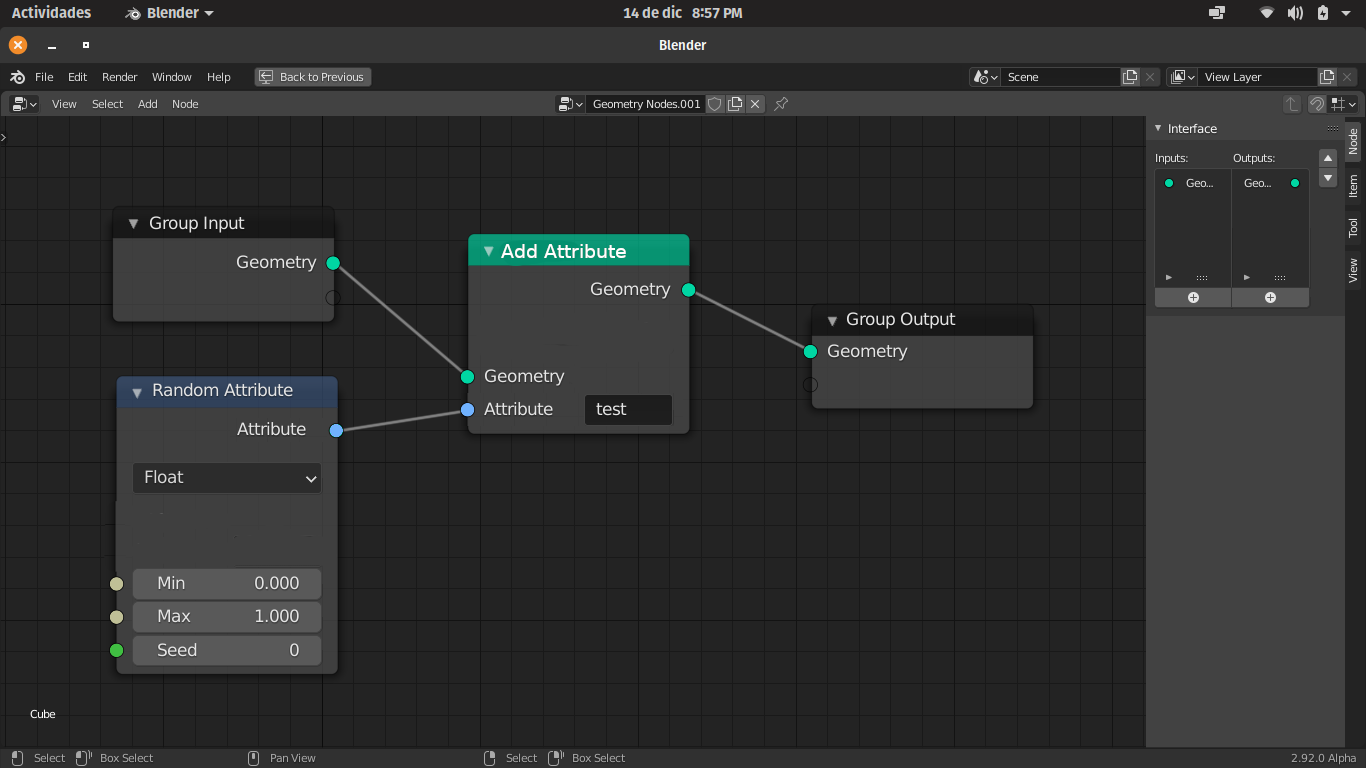
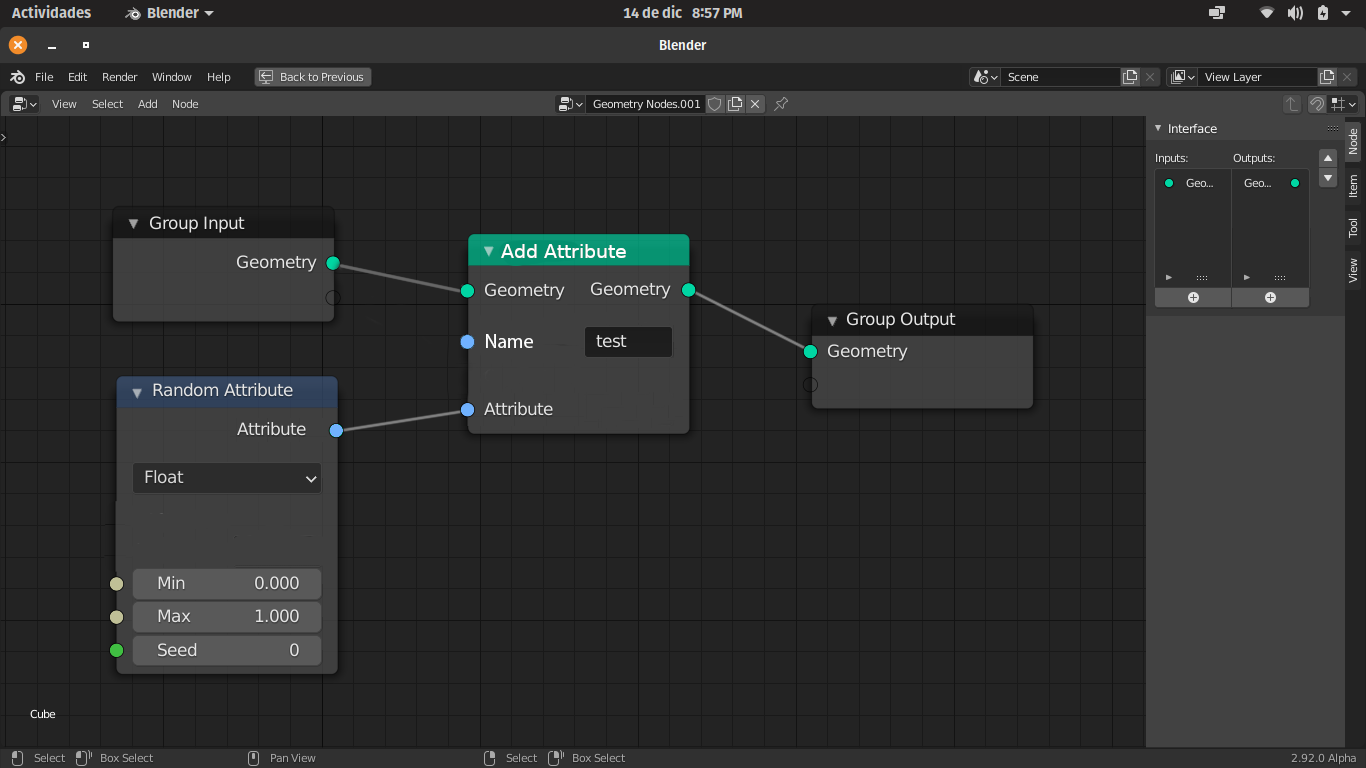
Now, on the tree level, right now to create an attribute you have to use a “Random Attribute” node, so you have to input an attribute inside a node inside a tree, leet’s imagine tha attribute is called “MY_VALUE”.
Let’s picture a big node tree, somewhere in the node tree I created the attribute “MY_VALUE” and I want to use it in several places, so far so good, I just call the attribute, but if I have to modify that attribute value I will have to look for the “Random Attribute” node where I created it and then modify it.
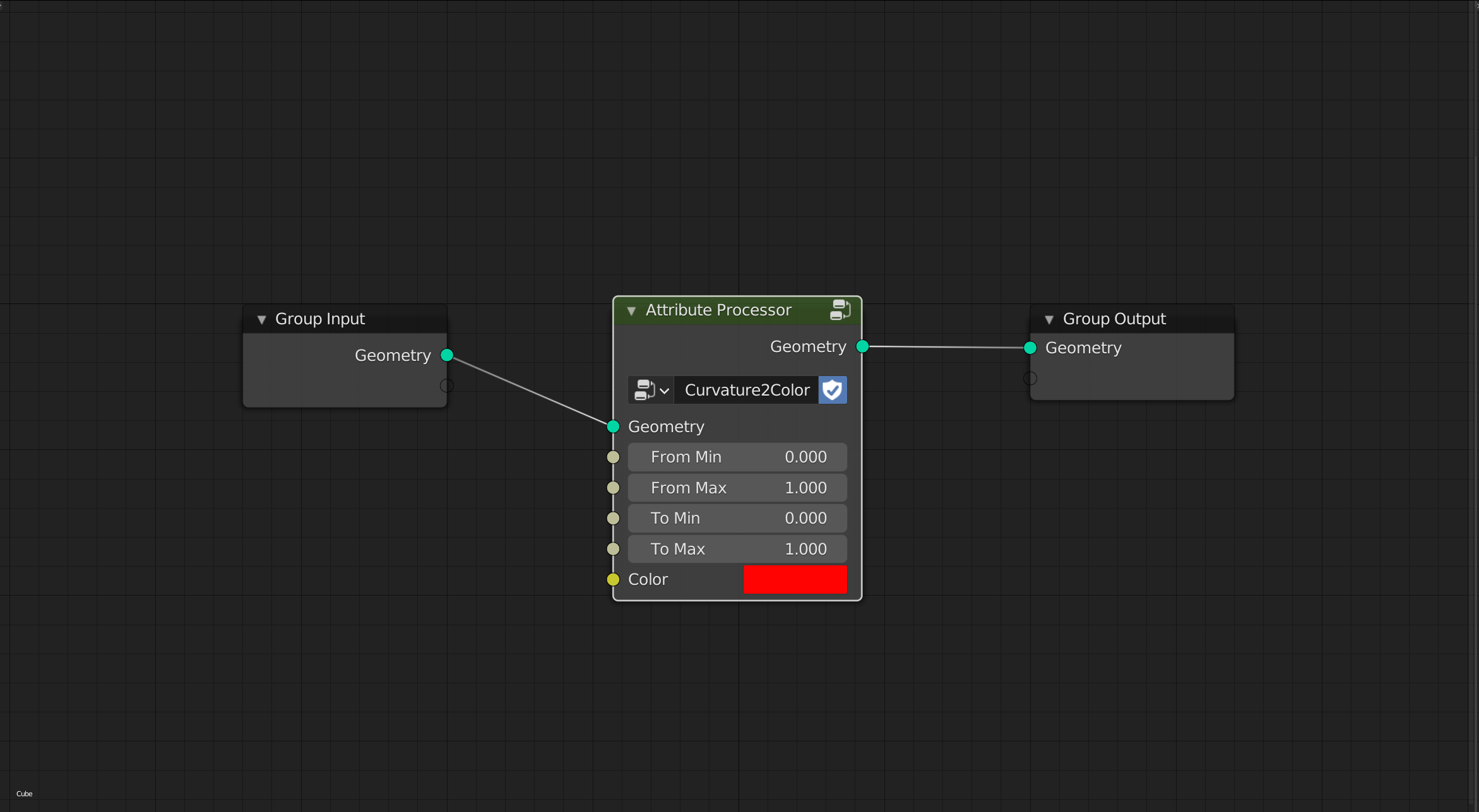
If we have an attribute pool, it’s just a variables list, and we can pick that attribute in that list, in the N panel, and access and modify it’s values, we would have just two nodes to access that attribute, the “Get Attribute” and the “Set Attribute”.
With the “Get Attribute” we are just getting that attribute to use it, that’s it, the “Get Attribute” node socket would vary depending in the Attribute type it’s called, or it can be a “joker” socket where the user has to be conscious of the type to use it.
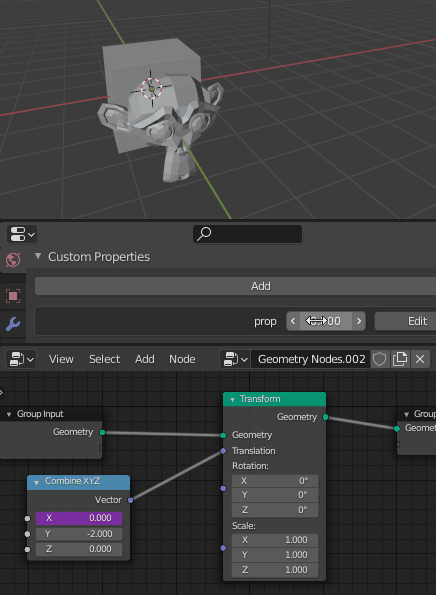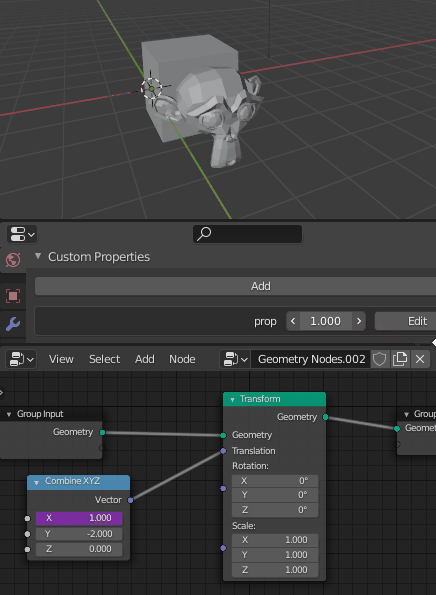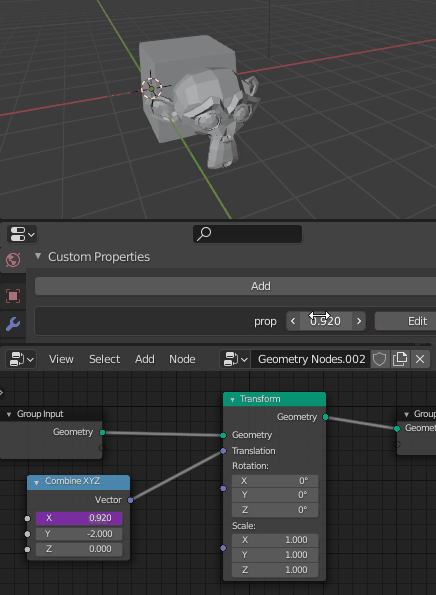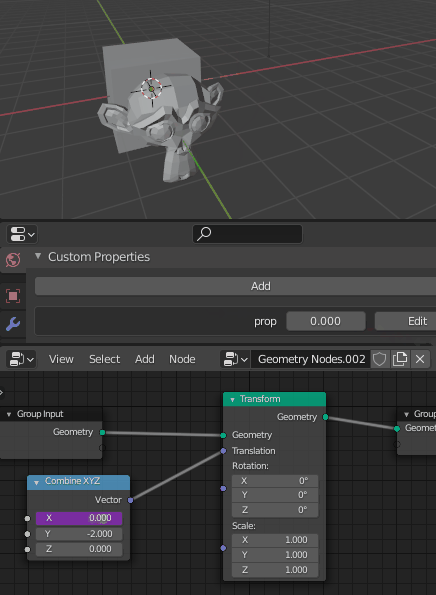
The Set attribute node would allow you to modify the attribute value, so you can do whatever operation you want and modify it on the fly, procedurally, on the execution tree, but the initial value is set in the attributes pool.
That would be a “Node-Tree specific attribute pool” and we don’t require to generate a node and input one more node in the tree to create Attributes.
It’s ok when you have one or two attributes, but it would be a nightmare to have to look for 10 or 20 “Random Attribute” nodes where you create and input new values and attributes, with this you use or modify the attributes in the tree, but you initially create them in a simple list, easy to access and modify without having to become crazy looking for it.
As I said it’s a concept applied in several other places for nodes and it’s a very successful one, efficient, simple, user friendly and advanced user / high level technical user/director friendly.