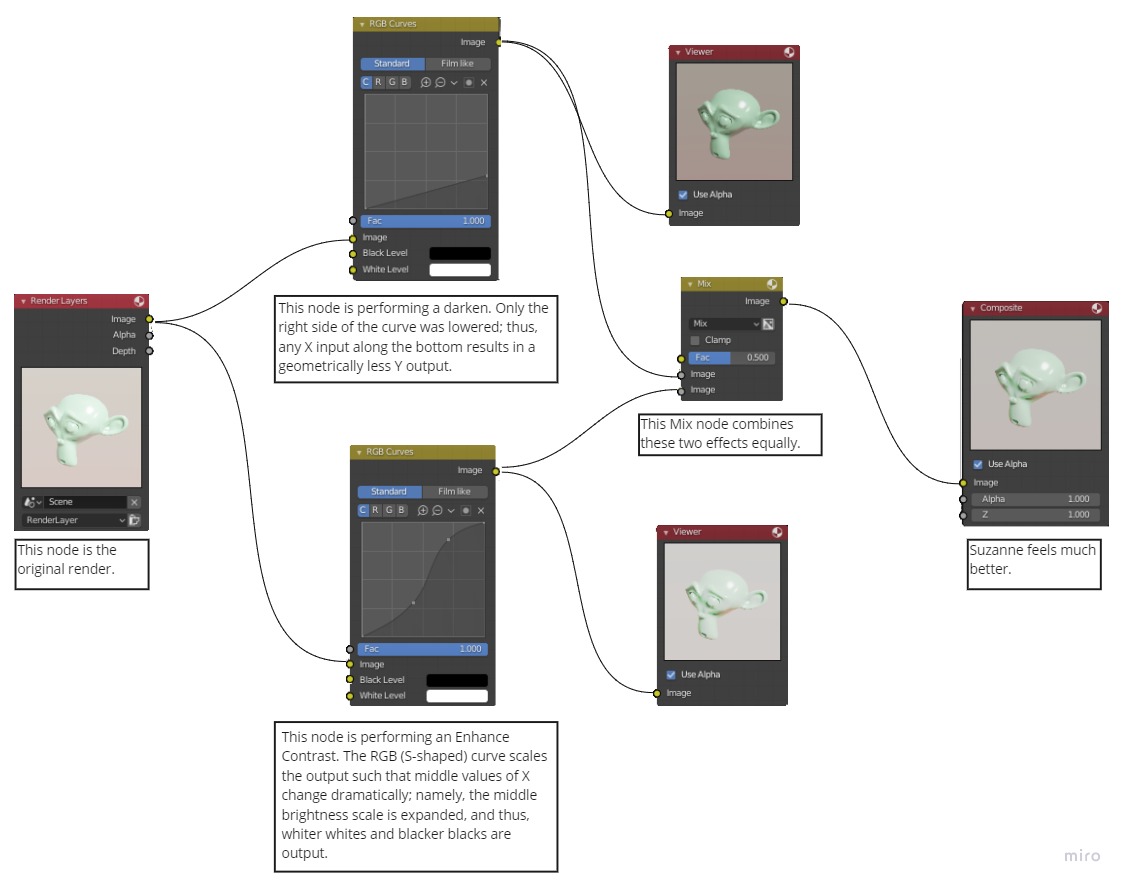
Having to look at a setup and then read some of the explanation and look at the setup until you understand it is an inefficient way to consume learning geometry nodes. The documentation would benefit from the explanation of what each node does being in proximity to the node in the figure.
This could be made easier to accomplish by having a text box primitive that could be created in the Node space so that the nodes and descriptions could be arranged easily in Blender instead of after the fact in a graphics program. This would also allow users to add commentary and explanations to their setups.
If you suggest adding text to screenshots in the user manual, then it is unacceptable. This text will not be translatable. And this will make it very difficult to update screenshots when the UI changes. It also looks like a tutorial, while the Blender Manual is a reference manual.
I believe there are web tools for displaying tooltips on images, those would be translatable. I also think the manual could go the extra mile and provide such breakdowns for learning purposes. I understand someone has to do it, but on paper it doesn’t seem out of place to me
Could create an add-on that captures the nodes space with the text blocks as text so that it can be translated. Would be best if the output was translated into HTML where each node was an independent graphic and each text box was a DIV with each just having an absolute position or part of an SVG element.
An even better implementation would allow for a way to tag the setup so that it easily be imported/sent to a CMS system.
The Blender Manual is written using reStructuredText (RST) and is built with Sphinx. So first of all there are technical limitations.
At the moment, all languages use the same set of images.
If you need to describe a separate part of the image, then you just add a marker (1,2,3,…) or a color frame and describe it below the image. But even this should be avoided, because it’s an extra work when you need to update the screenshot.
It doesn’t make it look like a tutorial. It makes it an annotated figure where the user doesn’t have to try to go between an image and text trying to tie the two together. Doing this shows a priority for understandability and minimal cognitive effort to help users learn a complex subject where the relationships of components are important.
While I do not know that the best solution is to embed HTML I suggested it because it lets the text be editable and the textboxes and graphics can adjust based on the length of translated text.
Embedding a html document inside of RST
Someone who knows Sphinx can do a POC and see how it works.