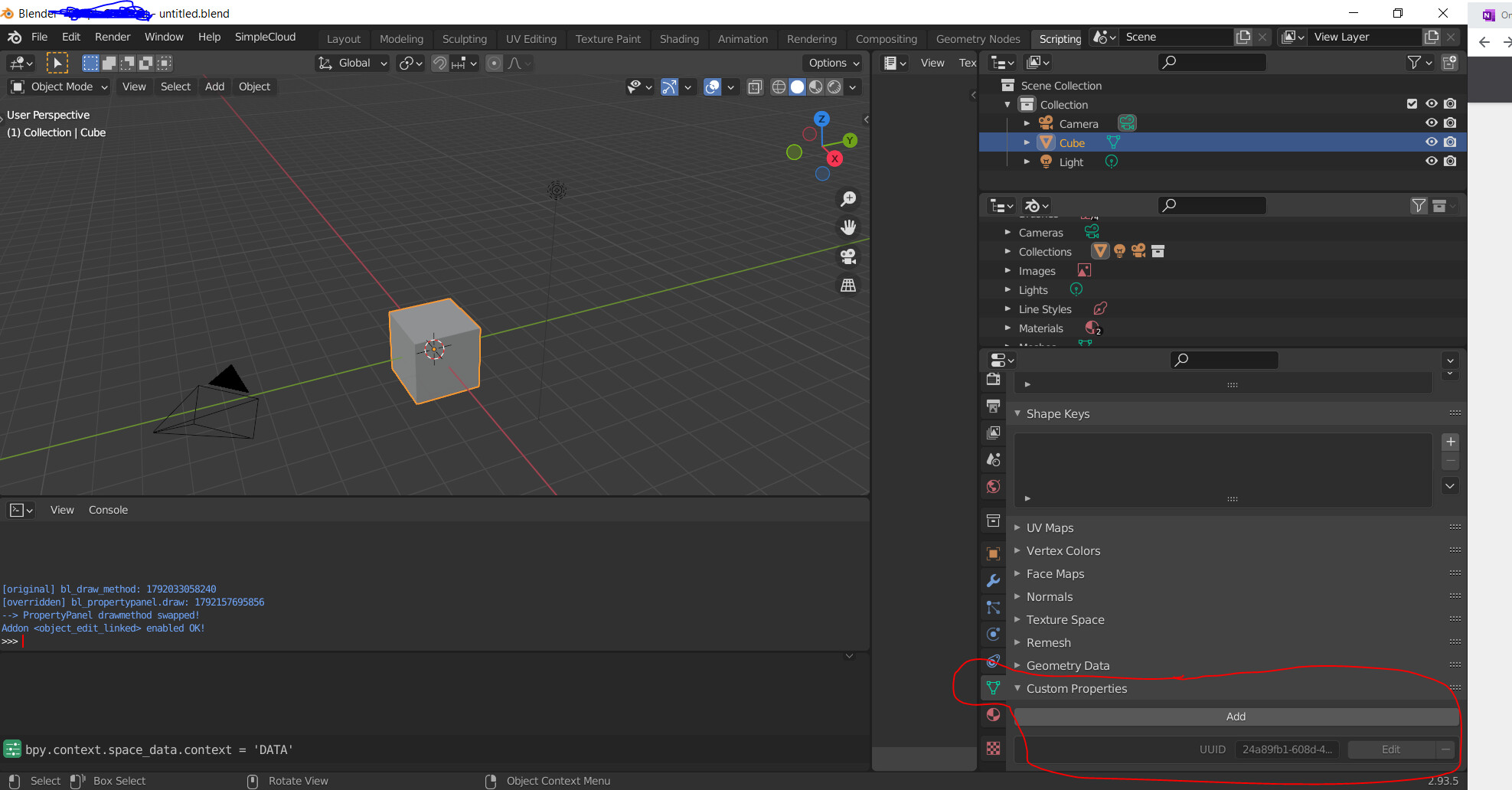
Good morning,
Regarding the use of custom properties to hold universal unique ids there are many threads and it is a recurrent topic (i.e.: Custom property improvements).
We are developing a pipeline a we are relying heavily on UUIDs. Other softwares that dont support this functionality natively have different workarounds that allowed us to bypass this limitation.
In Blender, we are getting to the point right now where we are able to set a custom property to objects datablocks that holds this UUID. But the problem now, is dealing with object duplication as copying the datablocks copies as well the same UUID.
In order to tackle this im trying to figure out how can i detect in depsgraph updates whether an object has been: (1) renamed (hence, no UUID update should be made) (2) duplicated (hence, a new UUID overwrite should be made) and (3) new object added (hence, a new UUID in the custom property should be created.
How can i detect unmistakingly each of these three situations when iterating through the depsgraph updates?
Im using blender 2.93 LTS.
EDIT: The other option im considering, is tweaking the bpy.ops.outliner.id_operation(type=“COPY”) so that it performs exactly the same as the original one but would not copy specific custom property UUID, so that instead of overwriting it, i would only have to create it once.
Im considering this in order to leverage a little bit the load on the handlers that iterate through the depsgraph updates.
I dont have much experience with blender yet, so any help would be much appreciated.
It’s not possible to accurately distinguish those 3 cases currently. That information is not maintained by Blender.
Detecting a new object is possible in that the UUID will be empty. Detecting that a datablock was duplicated could be done by checking for duplicate UUIDs, though that has a cost, and you wouldn’t know which one was the original.
This is why there are various proposals to improve properties or natively add UUIDs, because doing this from an add-on right now has limitations.
Hi,
Brecht, thanks for taking time to reply.
I understand there are many limitations and reasons why this is difficult to implement. So far, i understand having to iterate through all the objects (transforms/geometries) and materials is rather inefficient and time consuming even more as long as the scene is quite big.
I can see the inability to distinguish case (3) (where there is no built in option to differentiate between the duplicate and the original) (Is the index order in the collection not something to rely on?)
Towards this matter one quick thought that comes to mind is bypassing this using the combination of (1) a second custom property that would only hold a timestamp with the creation datetime, and (2) the extension or modification of the “copy/paste” operator that would work exactly the same as the built-in but would prevent from copying this custom property and instead would create a new one and add it. This would provide a way to compare both objects and there would be two possible cases: (1) comparing timestamps or (2) if no timestamp, this is the duplicate. (depending on the handler running at the very current moment)
This solution seems sufficient to us, in order to integrate Blender 2.93 LTS into our pipeline, but, can you clarify other core limitations that we may not be able to have taken into account?
I don’t really understand the timestamp idea, that timestamp would be duplicated just like the UUID, so you wouldn’t be able to distinguish it?
What could help distinguish is the pointer to the object that you get with .as_pointer(), that would remain the same for the original object as long as Blender has the file open. On .blend file save & load that pointer of course changes.
There may be a dozen ways to end up with duplicated datablocks besides copy/paste in the outliner. There’s duplicate in the 3D viewport, copy paste between .blend files, append, make local, making instances real, etc. It would be hard to handle all those.
I just thought that the timestamp idea would work, ideally, in combination with new implementation of copy/paste operators that would perform an exact copy of the datablock except for this timestamp property, thus leaving it aside. This way we could be able to distinguish it since the original datablock would hold the oldest timestamp and the dup would not have it or have a newer timestamp.
Would it be possible to implement all those operators in order for them to work as stated above? (preventing the copy of the datablock?) Is this feasible from the python API?
Maybe it is not, havent checked the code of these operators yet and maybe what im saying has no point…
We use a CollectionProperty to store a list of PointerProperties, with each PointerProperty pointing towards an object. The list can be updated such as in the depsgraph_update handler in this way:
For each object in the .blend file:
If the object is not in the CollectionProperty, add it to the list and initialize a unique ID on the Object
If the UID was not already initialized, then this could be a newly created object or the object could have been appended from another .blend file.
If the UID was already initialized, then this could be a duplicated object or an object appended from another .blend file.
If a PointerProperty points to a None value, then the object was deleted and can be removed from the list.
For our use case, the IDs only need to be unique per .blend file. We store the CollectionProperty on a datablock that is less likely to be deleted by the user (similar to this solution).
The CollectionProperty is stored on a Text datablock internal to the .blend file. The text file is named with a . prefix (ex: .my_addon_metadata), which hides the text object from being selected in the text editor, making it more difficult for a user to accidentally delete the object.
Since the update iterates over all objects, this can start to slow down the Blender UI if there are too many objects (around a few thousand) or if the update happens too frequently (such as in depsgraph_update). Depending on use case, an optimization could be to only trigger an update ‘on demand’ when ID values need to be retrieved.
Unique identifier through the lifetime of any id_data object would be a wonderful idea.
some id_data (vertex groups for example) have no way of identify themselves other than their name, not handy!
and using python hash values are unreliable
effectively, having reliable identifier would benefit all edge cases where custom properties are not supported. Perhaps we can override the native __hash__() function so it will become usable?
Thanks for your answer.
I understand it could be a ton of work, but that is not a problem for us right now.
Where can i find proper documentation and a list of all the these operators?
For instance, i checked the python code bundled with blender 2.93.6 LTS and it seems the ops.py module is in charge of executing all the operators but havent found the packages where all these built-in operators are defined, which leads me to the following question: Is it because they are defined in the C++ Blender side instead of the Python one?
It would be great to have access to this full list of operators, specially the ones that, as stated, are responsible for the appending/linking, duplication, copy/paste, adding, etc you mentioned before.
Is it possible to have this list? We dont necessarily need the code. Just the full list of ops with their names, so that we can make sure we dont leave any workflow leaks in our pipeline.
It would be at least an order of magnitude less work to implement a Blender UUID system than to reimplement those operators. Some of them probably can’t be done correctly with Python anyway.
There is no documented list of such operators, it requires delving deeply in the code base and checking all code paths that duplicate datablocks, which is a lot of work. I can’t help you with this, I don’t think it’s a good use of your or my time.
Hi Brecht
I understand your concern and appreciate your advice very much.
I was rather more interested in those operators that are part of an artist’s workflow. Thus, the ones which can be executed manually through the interface GUI.
AFAIK, i can enumerate the following ones:
(1) ADD new object
(2) DUPLICATE an existing object (copy/paste)
(3) RENAME an existing object (both, the transform / Object and the Shape (Object Data).
(4) LINK an existing object of another .blend library file.
(5) APPEND an existing object of another .blend library file.
I hope i m not abusing your assistance and attention here, and if i am, apologies in advance.
There’s not one operator to add an object, there are multiple for different types of objects, and many more in add-ons. And it similar for other types of operations. Plus there are operations like make duplicates real, copy/paste, asset drag & drop, etc. It’s just not a practical approach to handle UUIDs at the operator level in my opinion.