I just want to clarify, what is a hardware BVH? Is it hardware accelerated ray traversal? Because if so the 6000 series does support it.
If hardware BVH is something else, please let me know and explain it to me?
I just want to clarify, what is a hardware BVH? Is it hardware accelerated ray traversal? Because if so the 6000 series does support it.
If hardware BVH is something else, please let me know and explain it to me?
I was trying to say exactly what you said about the vocabulary, I just didn’t know how to translate it.
Sorry to bump with off-topic, I don’t have an AMD gpu so I was wondering if anybody on Linux can confirm if cycles gpu rendering is working in my custom build before I go posting it around blender artists and reddit.
Blender 3.0 came out on December 3, 2021, and that’s when AMD put together new support for its graphics cards (HIP). Since then we have had 6 versions of Blender. Before the latest release came out, I wrote about my suspicions that AMD would not make it in time with HIP RT on Linux, but I hope that at least the viewport will finally be usable enough to work without worrying about crashing the whole system. As for the positives, in the new Blender 3.6 the rendering time of the “BMW” project has decreased from 43 to 37 seconds, and that’s a nice change. At first it also seemed that the viewport was finally stable but unfortunately I was wrong. Previously (Blender 3.5.1 and earlier versions) when I turned off “overlay” in the cycles preview the gpu did not crash. Yesterday, unfortunately, the system crashed even in this case. It’s good that I use Nvidia at work, but I equipped my private hardware with a radeon card, because I don’t like when one company has a monopoly. I was glad to buy this card. I think AMD should consider withdrawing support for Linux. It has been more than 1.5 years since this bug wasn’t fixed. I omit the fact that the installation of Open CL and ROCm drivers is not very intuitive compared to Nvidia solutions. What hurts me is the fact that, despite the manufacturer’s assurances, the hardware does not fully support Linux systems. I think this is misleading customers. Maybe completely opening up the code and support to Mesa developers and giving them ROCm OpenCL and other technologies would be a good idea, while declaring that AMD is officially not 100% compatible with Linux. Right now I feel like the Radeon manufacturers are laughing in my face.
In fact, the main blender foundation does not have enough staff, open source anti-monopoly vulkan the most appropriate, rocm/hip although open source but to amd all, if rocm that he is powerful amd will change the rules of the game at any time, cuda also open source amd and intel dare not support.
I asked this question quite a while ago. Why doesn’t Cycles use Vulkan to support all major GPU vendors? The response from Brecht was basically that Vulkan was different from C++ and as such they would have to write large portions of Cycles twice. Once in C++ for the CPU, and once in Vulkan to support the GPUs.
With things like CUDA, HIP, and oneAPI, most of the code that Cycles uses for the CPU can just be recompiled into supporting GPUs without much extra work.
Also as a side effect of switching to Vulkan, it would mean they would lose the ability to potentially use many external libraries on the GPU in a official capacity. (E.G. OSL has OptiX support, allowing it to be used in Cycles with the OptiX backend for GPUs. If Cycles only had Vulkan support, there would be no OSL support for any GPUs unless the Blender foundation put in the work to port OSL to Vulkan theirselves)
rocm/hip although open source but to amd all, if rocm that he is powerful amd will change the rules of the game at any time, cuda also open source amd and intel dare not support.
The HIP backend code can be compiled both for AMD GPUs and Nvidia GPUs (Using the CUDA compiler). oneAPI can be compiled for Intel, AMD (Using the compiler for HIP), and Nvidia GPUs (Using the CUDA compiler).
If the Blender developers wanted to simplify things, they could switch to using only oneAPI and compiling for all three GPU vendors. But they don’t because:
So yeah, HIP does appear to be sub-par in some areas. But using HIP directly is better than using oneAPI → HIP and it’s less time consuming for the developers to use HIP compared to things like Vulkan.
I understand these problems. and in that case, is there a chance that the problem with the HIP viewport will finally be fixed? I’m straying a bit from the point but recently I wanted to test Davinci Resolve in the Studio version because I have a legitimate key. However, it turns out that the program does not detect the radeon gpu despite the installation of opencl pro and ROCm. only mesa-opencl started the progam and detected the graphics card, but any media file formats do not work, all files are grayed out and timeline does not work. If AMD made good and seamless proprietary drivers for their cards in Linux like nvidia does I would have no problem with this solution, but to use their cards more professionally you need to be some kind of programmer. i have not seen such unintuitive solutions yet.
These are two different topics.
Will the Linux GPU driver situation improve to the point where it’s stable, reliable, and easy to use for people wanting to use HIP/ROCm applications like Blender? (What I believe you’re asking). I can not answer that question since I don’t work at AMD nor do I work on the open source AMD GPU drivers, but I sure hope it gets to that point some point in the near future.
The other question was: Why doesn’t Cycles use Vulkan to improve cross vendor and cross platform compatibility? Especially considering that HIP seems to be in a sub-par state in some areas while AMD’s, Nvidia’s, and Intel’s support for Vulkan all seem pretty good. (At least I assume this was the question asked by the other user). And the answer to that question can be found in my previous comment.
Is there any new news regarding viewport crashing when rendering GPU from HIP? I have the latest ROCm 5.6 on Ubuntu and nothing has changed. for a while it looked like the viewport was not crashing, but when it first happened it now freezes the gpu after a short while every time. This forum thread has been going on since 2021. What is the reason that this problem cannot be fixed for such a long time? After all, it makes it impossible to use the program normally. This is how AMD is losing its reputation among Open Souce users.
Just to be clear you mean this issue? #100353 - Cycles HIP rendered viewport crashes system/GPU on Linux with RDNA2 GPU - blender - Blender Projects
Yes sir! It’s about exactly the bug that has been present in Linux since version 3.0. It seems that the new version 3.6.1 and ROCm Drivers have improved the stability a bit, but unfortunately I have noticed the viewport problem several times. here is my specification. I plan in the near future to update the processor to Ryzen 5 5600X and better RAM, but I think it will not affect the stability of the viewport.
Rendering crashes should restart the device
I’ve been interested in comparing the Ray Accelerators in the AMD GPUs to the Ray Tracing Units in Intel GPUs to the Ray Tracing Cores in Nvidia GPUs. And now that we have HIPRT, OptiX, and Embree GPU in Cycles, we can do that. And with Cycles we can extract some extra debug information to help understand the differences.
So that’s what this comment is about. The performance of the ray accelerators/tracing cores/tracing units on different vendors. From now on I will refer to the “ray accelerators/tracing cores/tracing units” as hardware ray accelerators.
First off, testing methodology:
I took a collection of scenes from Demo Files — blender.org and rendered them on various GPUs.
For each file I disabled “Adaptive Sampling”, set the sample count to 1024, and the resolution to 1920x1080 (With the exception of the files that had square camera resolutions. These were set to 1920x1920). Other than that, everything else was left at default.
I then ran the render three times without the hardware ray acceleration and with hardware ray acceleration, removing outliers and retesting. The average of these three tests are used in the results.
Some tests were removed (and thus not published here) because they didn’t fit fully within the 8GB VRAM limit of my GPUs so I didn’t think it was fair to publish them since they would just have weird performance numbers.
All tests were run with the launch options --debug-cycles --verbose 4, which breaks out information about different parts of the rendering process for performance analysis.
Using the information provided by --debug-cycles --verbose 4, the intersection time can be extracted from the render time, allowing us to compare the performance of intersections with and without the hardware ray accelerators. More on this in the “Context” section
The GPUs I tested with were the:
RTX 4090 (Representing Nvidia)
RX 7600 (Representing AMD)
Arc A750 (Representing Intel)
Other system factors:
Blender version: 4.0.0 Alpha, branch: main, commit date: 2023-08-23 19:52, hash: 7c2dc5183d03
OS: Windows 11
Drivers:
Nvidia: 536.67
AMD: Adrenalin 23.8.1
Intel: 31.0.101.4644
Tests were done on two systems.
System 1 (Nvidia was tested here):
Ryzen 9 5950X with 64GB of RAM
System 2 (AMD and Intel were tested here):
Ryzen 5 5600 with 32GB of RAM
Secondly, Extra context:
Nvidia, AMD, and Intel all offer hardware ray accelerators. And they do one primary job, do the math for the ray intersection tests quickly so the work doesn’t have to be done on the compute units on the GPU.
These hardware ray accelerators are accessed by enabling the BVH designed for each GPU. This can be done by enabling HIPRT, OptiX, and Embree GPU for each respective GPU vendor. The main difference between these features being on and off is the BVH and the performance as a result of the hardware ray accelerators being used. Other areas like shading are left practically untouched.
My main goal of this testing was to measure the relative performance of the hardware ray accelerators to the general compute units in the “intersection” part of Cycles (intersections being the part where hardware ray accelerators are used).
Thankfully with --debug-cycles --verbose 4, various intersection parts of Cycles are broken out from the rest of Cycles allowing us to look at just the intersections and how they compare.
I mentioned earlier I am measuring relative performance. I am doing this because it allows me to compare the different hardware ray accelerators to each other even though I have wildly different class GPUs (E.G. High end RTX 4090 vs a midrange RX 7600). Although, due to the complexities explained below, this isn’t exactly a fair comparison.
In a simple world, the relative performance numbers can be transferred between products with the same architecture (E.G. The relative performances scores from a RX 7600 are the same as the relative performance scores of all other RDNA3 GPUs like the RX 7900XTX). This is because the compute unit to hardware ray accelerator ratio stays the same throughout an architecture. And the relative performance numbers are measuring the performance ratio between compute units and hardware ray accelerators.
However, we do not live in a simple world. And so these relative performance numbers can not be transferred between GPUs of the same architecture. This is because things like memory size, shared memory bandwidth, work scheduling, etc, all change as you go up and down the product stack from different vendors. However, these numbers can probably be used to get a general idea of performance in the same architecture family.
Thirdly, How to understand the charts:
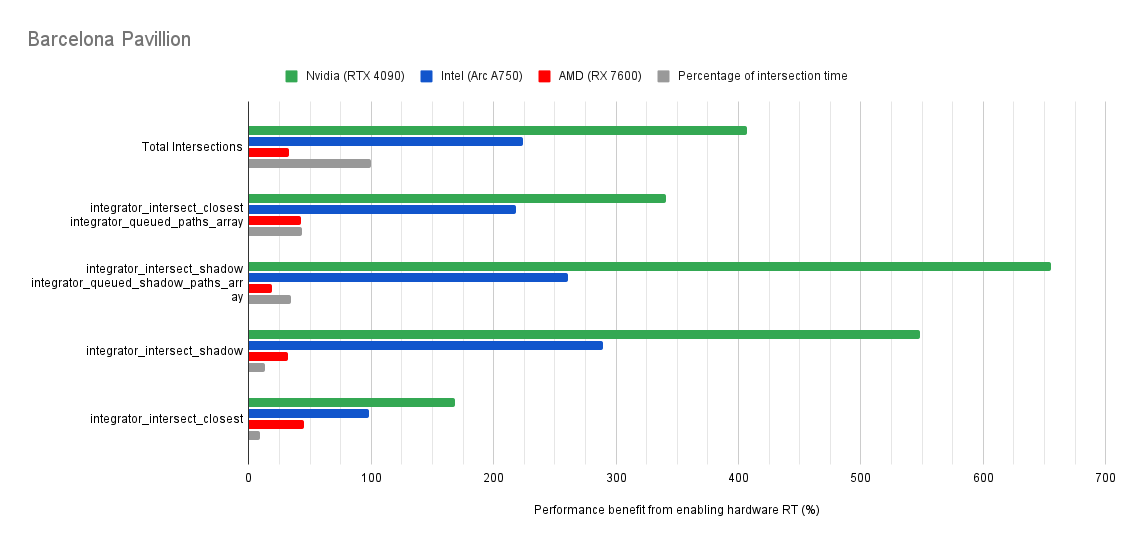
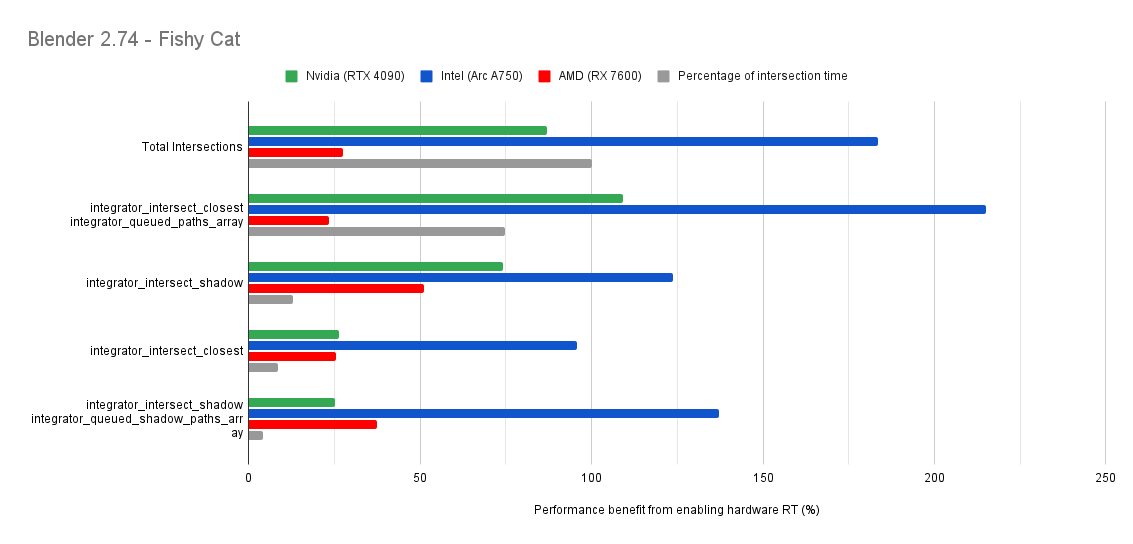
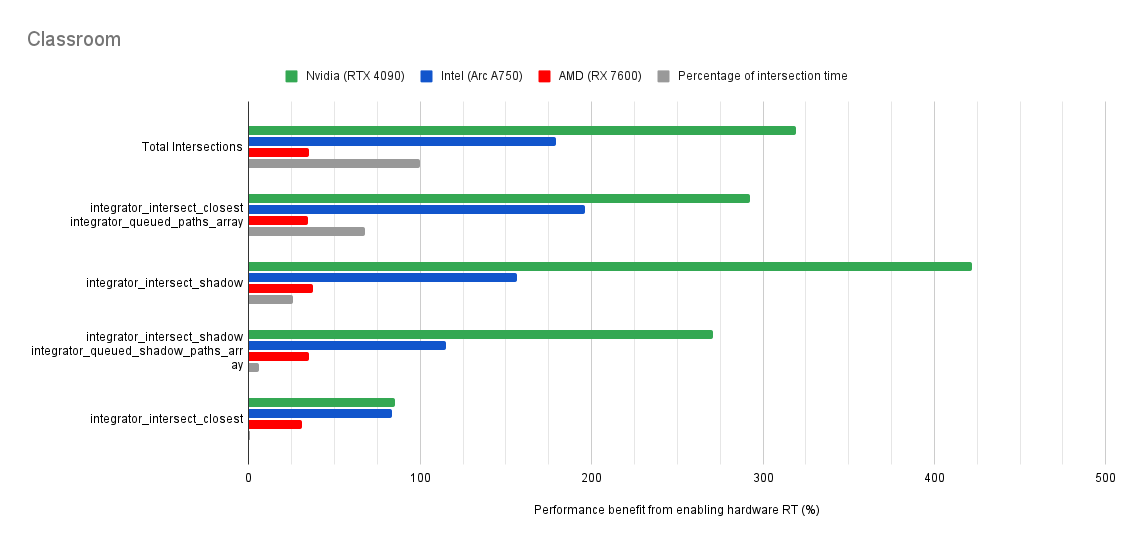
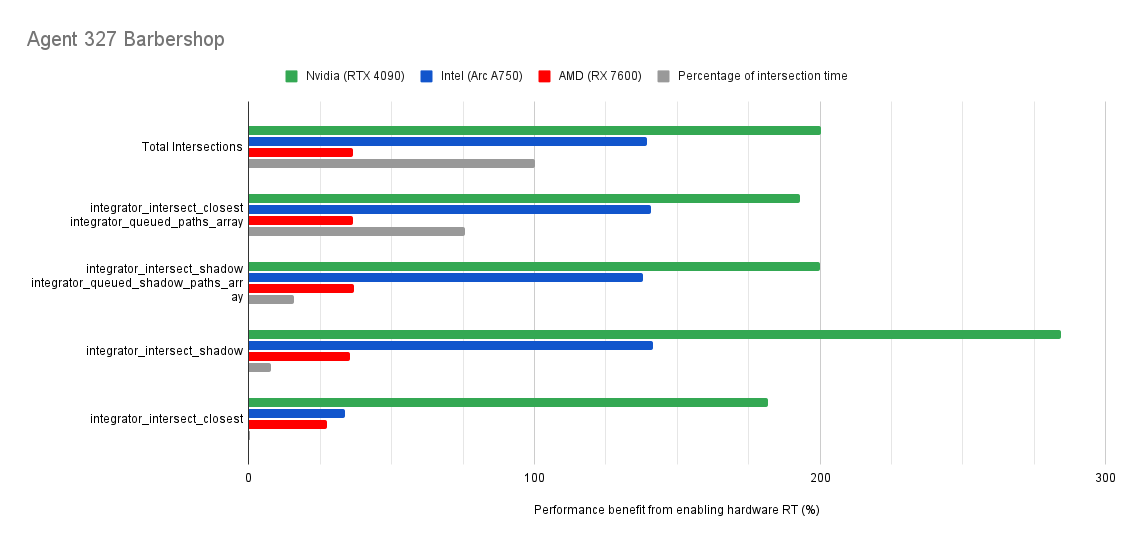
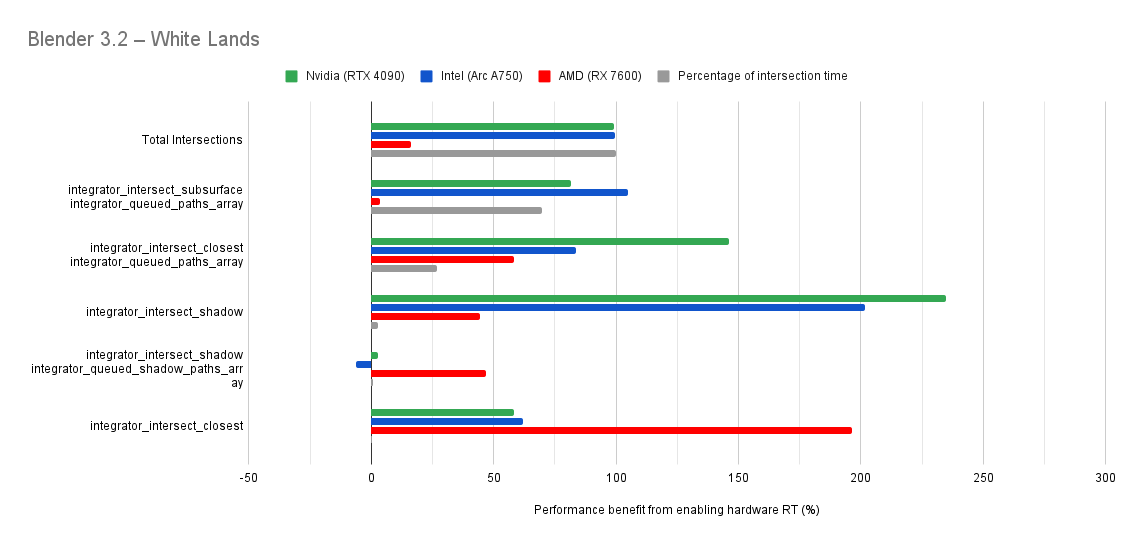
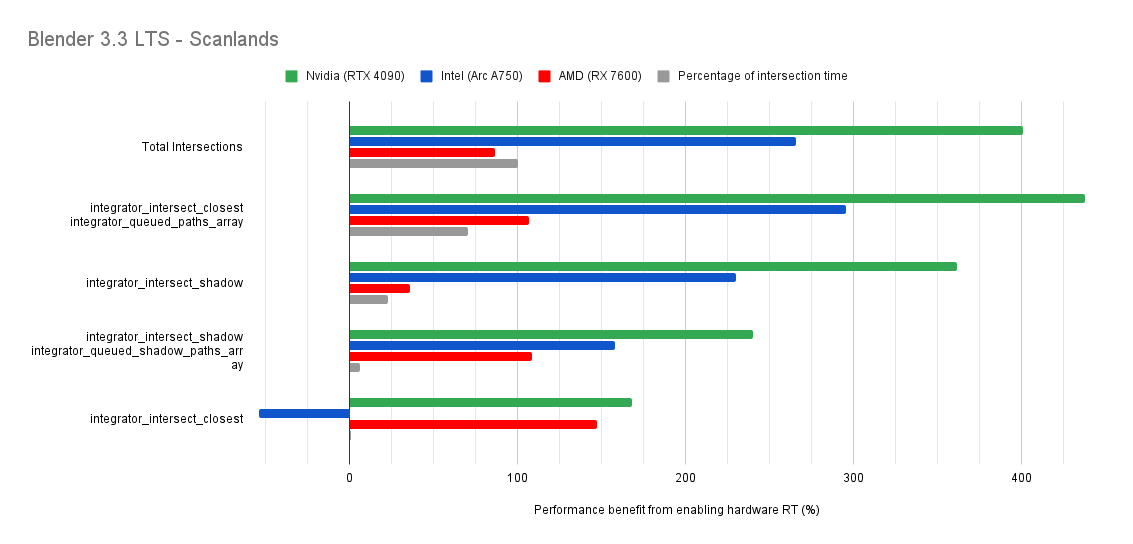
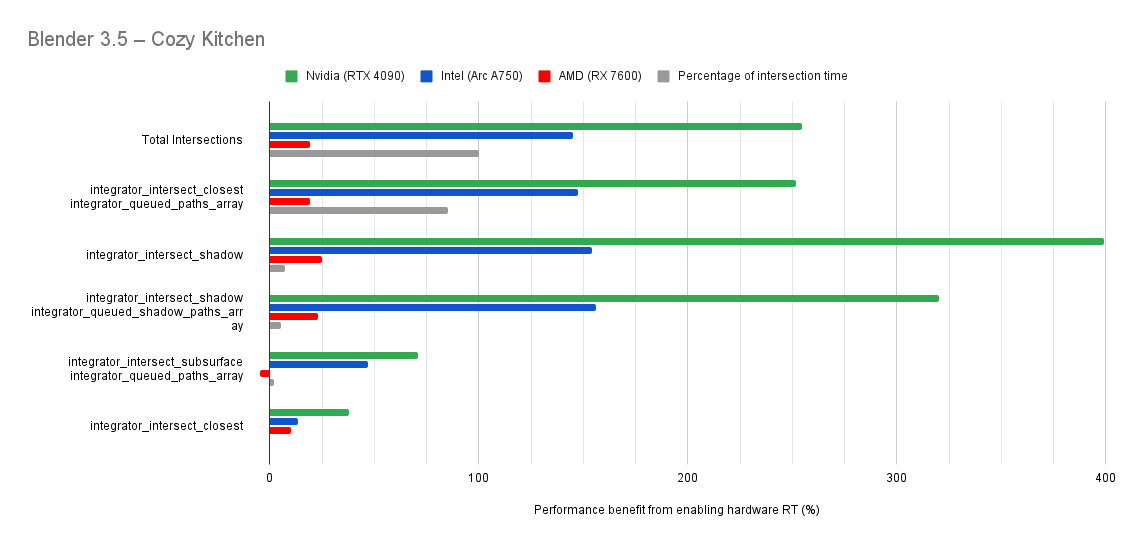
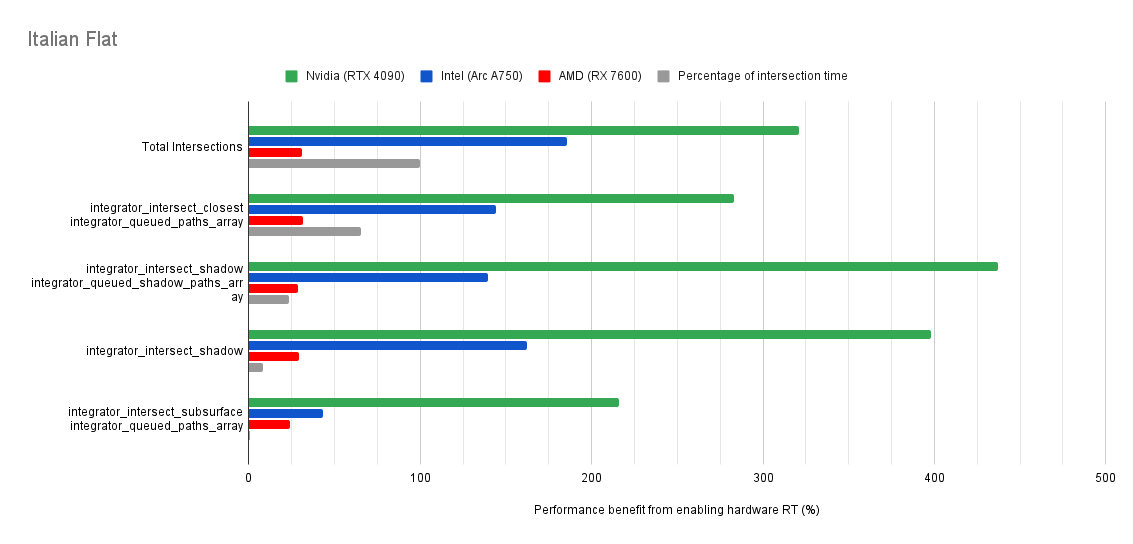
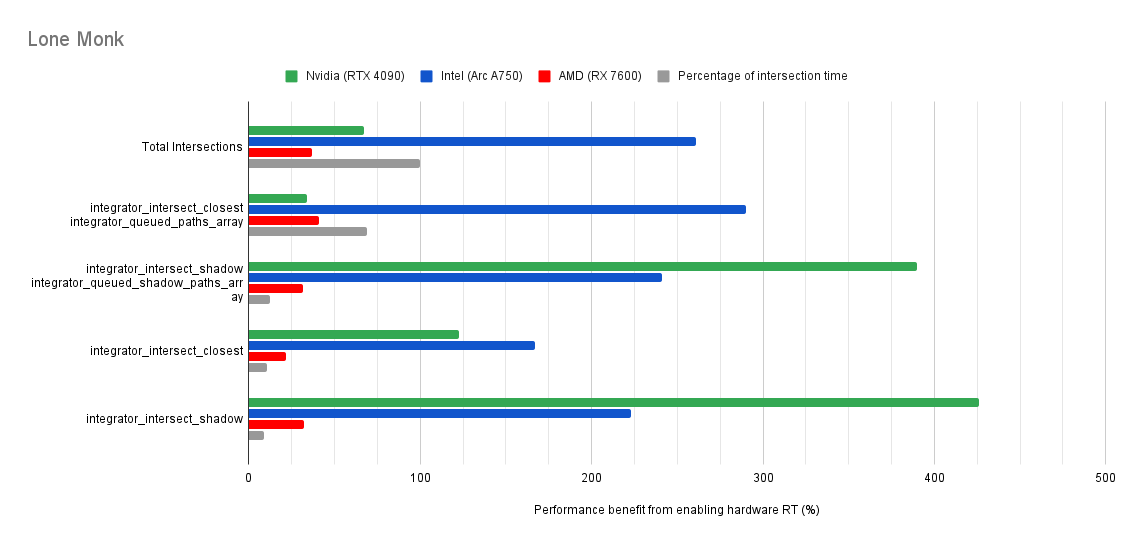
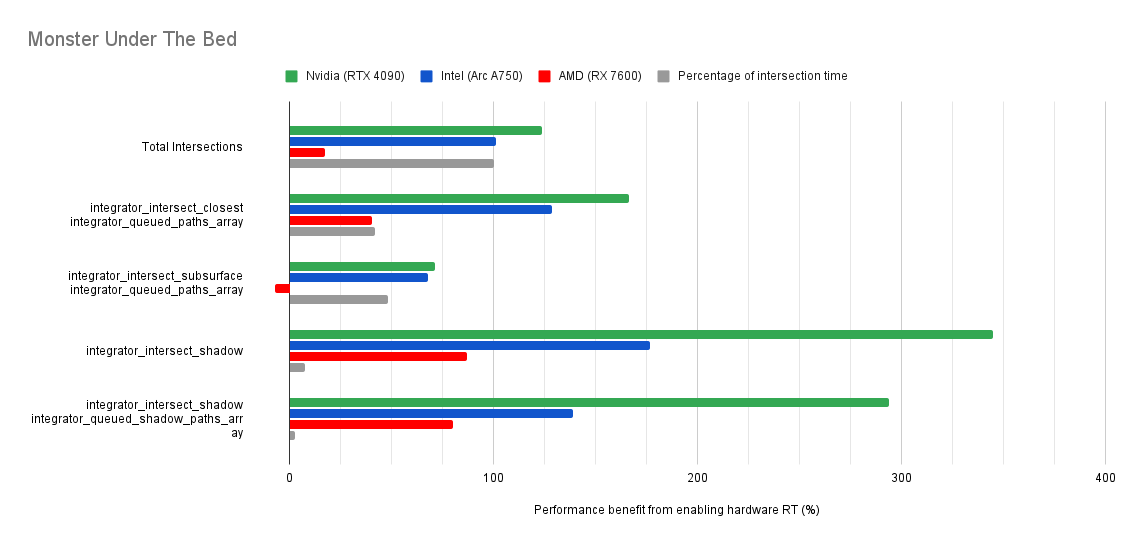
Below you will find many charts. Each chart has a title (top left) telling you which scene was tested.
The horizontal axis is the “relative performance benefit gained by enabling the hardware ray accelerators” in percentage.
On the vertical axis you will see labels for various intersection types along with the “Total Intersections”.
integrator_intersect_shadow and integrator_intersect_closest. These are different types of intersections done in Cycles and I’ve broken them out just so you can see them. However an extra piece of information is required to understand them. Percentage of intersection time. You will see that one intersection type may get something like a 300% speed increase compared to 100% in others, and you may think that’s important. But if that intersection type only makes up a small portion of the total intersection time, then that speed up doesn’t matter as much. So please take into consideration the percentage of intersection time along with the intersection speed ups to weigh their importance.How do the results transfer into rendering performance?
The results are for intersection time, not rendering performance. As such, if you see a number like “300% better intersection performance”, then don’t expect your renders to be 300% faster.
This is because intersections only make up a portion of the rendering process. And the ray hardware accelerators only speed up the intersections. So the intersections may be faster, but nothing else is. So 300% faster intersections may transfer to 50% faster rendering, or 10%, or 100%. It all depends on the ratio between ray intersection and everything else.
Along with that, although the only thing that’s supposed to be different between hardware ray accelerators on vs off is supposed to be the intersection tests. Other things like shading may run slower when hardware ray accelerators are turned on. The is because the shading done on the compute units have to share memory bandwidth (and maybe cache) with the ray accelerators which may now be accessing memory more often. That, along with changes in memory usage due to a different BVH, and changes of power distribution as a result of the ray accelerators being active can end up impacting the performance of other systems, like shading, in a negative manner.
Fourthly, disclaimers:
Finally, chats:
Summary:
Both Intel and Nvidia offer good hardware ray accelerator performance scaling with Embree GPU and OptiX. Anywhere between 100% - 270% for Intel, 70 - 400% on Nvidia. However AMD shows poor performance scaling with the performance benefit being between 10% and 90% (Mostly in the 30% range).
I’m honestly surprised by these results. Maybe I did something wrong on the AMD GPU? Wrong drivers maybe? Maybe AMD performance isn’t that great with the current implementation of HIPRT (It is experimental after all)? Maybe the RX 7600 doesn’t handle this type of thing well due to something like VRAM or cache, and a higher end GPU like the RX 7900XTX would show better scaling? I don’t know.
If anyone has any further insights on these poor results, I would be grateful.
For anyone interested in ROCm on Linux - Debian has new hardware compatibility list:
Another, maybe not so good news is that current ROCm version in Debian is too old to support hardware RT. Update to ROCm 5.7 is roughly scheduled in next month or two.
Interesting to see gfx803 in that list. Have you come across any info. / documentation about this. Thanks.
Unfortunately no. I never had Polaris GPU, and never paid attention to this gen.
However I saw it being mentioned on ROCm github more often than on Debian mailing list.
Hi! Recently, after the release of blender 3.6.2, it seems to me that the problem with viewport using HIP on Linux has been solved. Has any work been carried out and can this be officially confirmed? I wonder if this is true or if I was just lucky and the viewport hasn’t crashed yet?
There was some work on the driver side. What driver version?
Unfortunately, I noticed that in several situations there is still a problem with crashing gpu drivers. Fortunately, the system now logs off the session, after a short blackscreen. Previously I was using rocm 5.6.0 now I upgraded it to 5.6.1 but it didn’t help. I have to admit that overall it is better, but still, working on the project I feel anxious waiting for the crash. it spoils a bit the fun of using Blender.
I’d just like to comment. I got access to a RX 7800XT and the performance uplift from HIPRT is greater on that device compared to the RX 7600. Suggesting the RX 7600 is likely memory bandwidth or cache limited, and there’s still the potential that the RX 7800XT is also memory bandwidth or cache limited. Or there’s something else going on in the hardware that I don’t understand.
For reference, the performance uplift with the RX 7800XT was basically double the RX 7600.
E.G. If intersections were 25% faster with the RX 7600 when enabling HIPRT, then intersections will be ~50% faster with the RX 7800XT when enabling HIPRT.
It’s an improvement, but it’s still not close to matching Intel or Nvidia.
I should caveat this testing. The test conditions were not identical between the RX 7600 and RX 7800XT. Here are the list of major things that changed or were the same between tests: