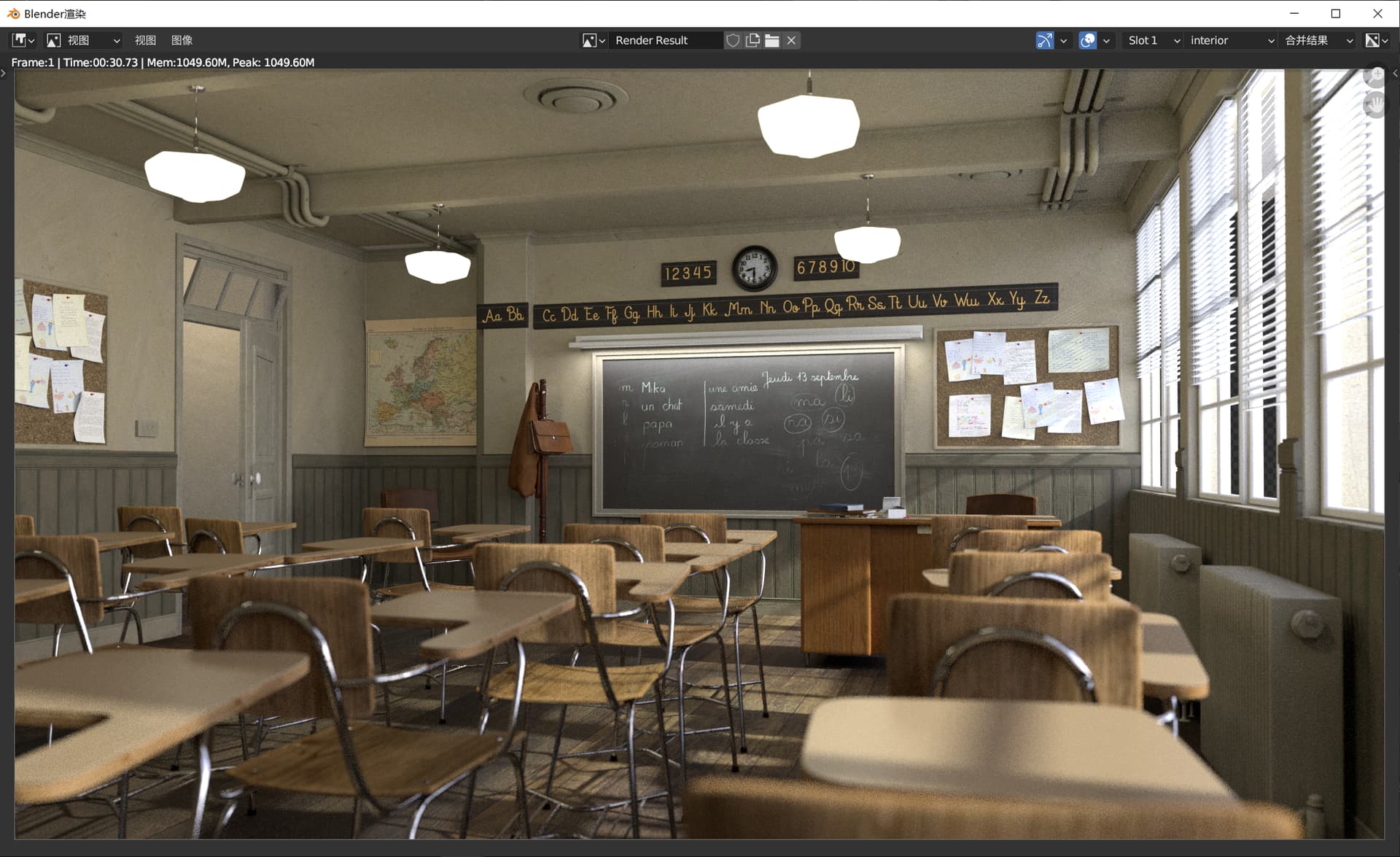
No, it’s the GPU. I double checked versions.
Unless those NVIDIA GeForce RTX 4090 users have some real firepower processors, in the 3.4 grouping.
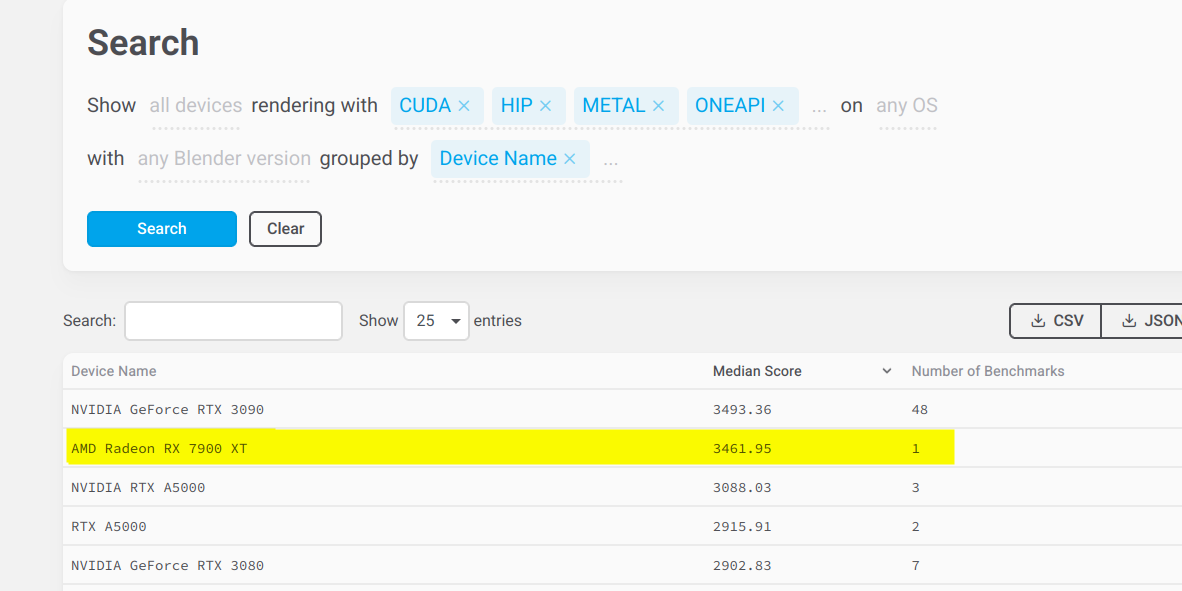
I had to double check, then triple check because there was no way that made any sense but it does, sort of. Compared to a 6900 XT it’s a great gain.
For 3.4
AMD Radeon RX 6600 XT 1183 @ 5 bench
AMD Radeon RX 6700 XT 1646 @ 3 *
AMD Radeon RX 6750 XT 1615.@ 1 *
AMD Radeon RX 6900 XT 2142.@ 1 *
AMD Radeon RX 7900 XT 3461 @ 1 *
Assmathing it on a napkin, that score makes sense. 7900 doubles the transistor count and the compute follows. The score, roughly falls within that. In terms of other hardware it’s a bump in shading units, tmus, rops, rt cores, but just a bump… IE 5376 shading units to the 6900 5120 count. 4 extra c/u,
So my disbelief aside, it not being a CPU aside, that score does make sense and given where it’s predecessors are I don’t think arguments that drivers or anything are holding it back. Always room for more but it’s right in line with what’s been on the table already.
It probably games like a son of a gun but that doesn’t help in this arena. It’s sitting beside a 3070, which can be bought new for $500~
It’s more powerful than the 3070 in a world where it’s doing the raytracing and all the other fancy algorithm-wrapped-in-a-flour-tortilla stuff that is OptiX, but it ain’t.
Prorender does baller stuff with ML, the denoise float16 is your money melon right there. 5x the jambalaya in a 7900 XT, and yeah this stuff is halfarse accurate but close enough.
7900 XT - FP16 (half) performance 103.0 TFLOPS (2:1)
3070 RTX -FP16 (half) performance 20.31 TFLOPS (1:1)
denoise_c3_ldr.pb
denoise_c3_ldr_float16.onnx
denoise_c9_ldr.pb
denoise_c9_ldr_f16.onnx
srgan-03x2x32-273866.pb
esrgan-05x3x32-278391.pb
taau_low_res.pb
taa_upscale_2x_part.pb
upscale2x_c3_rt_f16.onnx
upscale2x_fast.pb
It goes vroom vroom because of this sort of NOTPtiX method.