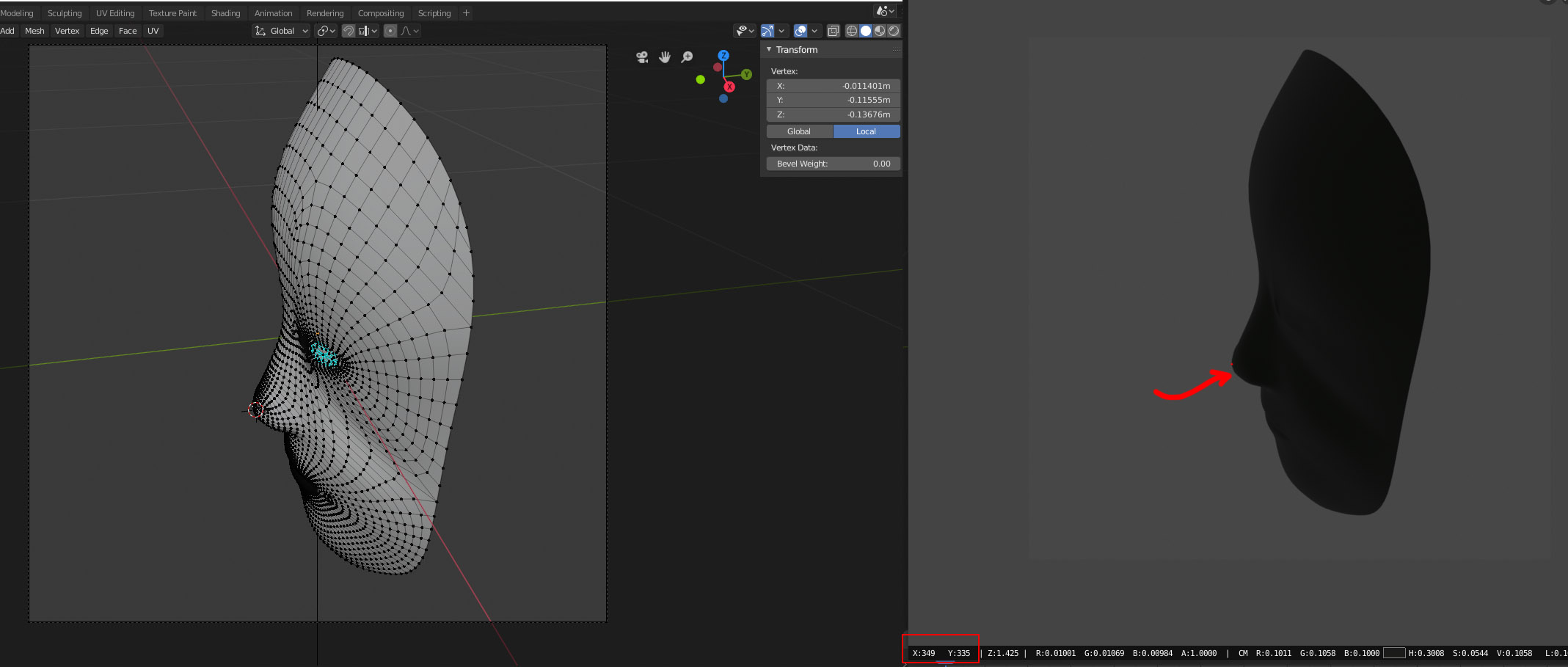
Hello, I wrote a script to understand how camera matrix works in Blender. First I use a parameter param to set up the scene(camera, parent/track camera, res_x, res_y, etc), then get the camera RT matrix and intrinsic matrix K from param . But when testing a selected vertex P3d to compare its 2d position in image p2d, somehow the result is a bit off. File here.
import bpy
import numpy as np
def camera_info(param):
theta = np.deg2rad(param[0])
phi = np.deg2rad(param[1])
camY = param[3]*np.sin(phi) * param[6]
temp = param[3]*np.cos(phi) * param[6]
camX = temp * np.cos(theta)
camZ = temp * np.sin(theta)
cam_pos = np.array([camX, camY, camZ])
axisZ = cam_pos.copy()
axisY = np.array([0,1,0])
axisX = np.cross(axisY, axisZ)
return camX, -camZ, camY
def unit(v):
norm = np.linalg.norm(v)
if norm == 0:
return v
return v / norm
def parent_obj_to_camera(b_camera):
origin = (0.0, 0.0, 0.0)
b_empty = bpy.data.objects.new("Empty", None)
b_empty.location = origin
b_camera.parent = b_empty # setup parenting
scn = bpy.context.scene
scn.collection.objects.link(b_empty)
bpy.context.view_layer.objects.active = b_empty
return b_empty
def cal_K(img_size):
F_MM = 50. # Focal length
SENSOR_SIZE_MM = 36.
PIXEL_ASPECT_RATIO = 1. # pixel_aspect_x / pixel_aspect_y
RESOLUTION_PCT = 100.
SKEW = 0.
# Calculate intrinsic matrix.
scale = RESOLUTION_PCT / 100
f_u = F_MM * img_size[1] * scale / SENSOR_SIZE_MM
f_v = F_MM * img_size[0] * scale * PIXEL_ASPECT_RATIO / SENSOR_SIZE_MM
u_0 = img_size[1] * scale / 2
v_0 = img_size[0] * scale / 2
K = np.matrix(((f_u, SKEW, u_0), (0, f_v, v_0), (0, 0, 1)), dtype=np.float32)
print('K: ', K)
return K
def get_RT( param):
# azimuth, elevation, in-plane rotation, distance, the field of view.
cam_mat, cam_pos = camera_info_rev(degree2rad(param))
RT = np.concatenate((cam_mat, np.reshape(cam_pos,[3,1])), axis =1)
print('RT: ', RT)
return RT
def degree2rad( params):
params[0] = np.deg2rad(params[0] + 180.0)
params[1] = np.deg2rad(params[1])
params[2] = np.deg2rad(params[2])
return params
def camera_info_rev( param):
az_mat = get_az(param[0])
el_mat = get_el(param[1])
inl_mat = get_inl(param[2])
# R = el*az*inl
cam_mat = el_mat@az_mat@inl_mat
cam_pos = get_cam_pos(param)
print('cam_mat: ', cam_mat)
return cam_mat, cam_pos
def get_cam_pos( param):
camX = 0
camY = 0
camZ = param[3]
cam_pos = np.array([camX, camY, camZ])
return -1 * cam_pos
def get_az( az):
cos = np.cos(az)
sin = np.sin(az)
mat = np.asarray([cos, 0.0, sin, 0.0, 1.0, 0.0, -1.0*sin, 0.0, cos], dtype=np.float32)
mat = np.reshape(mat, [3,3])
return mat
def get_el( el):
cos = np.cos(el)
sin = np.sin(el)
mat = np.asarray([1.0, 0.0, 0.0, 0.0, cos, -1.0*sin, 0.0, sin, cos], dtype=np.float32)
mat = np.reshape(mat, [3,3])
return mat
def get_inl( inl):
cos = np.cos(inl)
sin = np.sin(inl)
mat = np.asarray([cos, -1.0*sin, 0.0, sin, cos, 0.0, 0.0, 0.0, 1.0], dtype=np.float32)
mat = np.reshape(mat, [3,3])
return mat
def test_pt(P3d, K, RT ):
P3d = np.reshape(P3d,[3,int(len(P3d)/3)])
P3d = np.concatenate((P3d, np.ones((1, P3d.shape[1]),dtype=int)), axis =0)
print('P3d : ', P3d)
p2d = K @ RT @ P3d
return p2d
res = 896
img_size = (res,res)
scene = bpy.context.scene
scene.render.resolution_x = res
scene.render.resolution_y = res
scene.render.resolution_percentage = 100
cam = bpy.data.cameras.new("Cam")
cam_obj = bpy.data.objects.new("Camera", cam)
bpy.context.scene.collection.objects.link(cam_obj)
bpy.context.scene.camera = cam_obj
cam = scene.objects['Camera']
cam_constraint = cam.constraints.new(type='TRACK_TO')
cam_constraint.track_axis = 'TRACK_NEGATIVE_Z'
cam_constraint.up_axis = 'UP_Y'
b_empty = parent_obj_to_camera(cam)
cam_constraint.target = b_empty
# y_rot, x_rot, z_rot, dist, lens, sensor, max_distance
param = [14.41713748307988,25.29251130719033,0,0.7968077336595656,50,36,1.75]
camX, camY, camZ = camera_info(param)
cam.location = (camX, camY, camZ)
RT = get_RT(param)
mesh_objs = [obj for obj in bpy.data.objects if obj.type == 'MESH']
for o in mesh_objs:
o.select_set(True)
bpy.context.view_layer.objects.active = o
mode = bpy.context.active_object.mode
bpy.ops.object.mode_set(mode='OBJECT')
selectedVert = [v for v in bpy.context.active_object.data.vertices if v.select]
for v in selectedVert:
K = cal_K(img_size)
p2d = test_pt(v.co, K, RT)
print('p2d: ', p2d)
p2d should be somewhere close to [[349],[561], [1.0]], but the printed p2d is [[-270.47144011], [-525.51055641], [ -0.7289861 ]]. The last element should be 1, so I’m definitely doing something wrong here. Also I prefer to stay with my current functions, not to use built in functions like cam.matrix_world.decompose() or any other built in functions mentioned in rendering - 3x4 camera matrix from blender camera - Blender Stack Exchange