Currently, assets are either linked, appended or use the “append (reuse data)” mode. All of these modes have problems which make them unfit for use with the growing asset system. This severely limits our ability to ship assets with Blender and also makes it the asset system annoying to use in non-trivial production settings.
This document proposes a new approach for importing assets which solves the problems, making the asset system much more useful overall. At a minimum, these problems have to be solved:
- Assets can be embedded into
.blendfiles while keeping them read-only. - The same asset should only exist at most once in each file, avoiding unnecessary asset duplication.
First, the proposal is presented and then some of the design choices and options are discussed.
Proposal
The proposal combines multiple small ideas which don’t help much on their own. However, taken together they seem to achieve the goal quite well.
Globally Unique Asset File Names
Files that contain assets have to follow a specific naming scheme: namespace.name:vX.Y.Z.blend (or similar). For example, our existing assets could be renamed like so:
assets/geometry_nodes/
blender.procedural_hair_node_assets:v1.0.0.blend
blender.smooth_by_angle:v1.0.0.blend
The directory path is not taken into account. An arbitrary number of assets can be in each file, but it can be benefitial to split-up assets into multiple files in many cases. Nested namespaces of the form ns1.ns2...name work too.
Immutable Asset Files
Once published, asset files should not be changed anymore. If changes are necessary, a new file with a new version number should be created.
Asset Path in Library Data-Block
Currently, Library.filepath can store either a relative or absolute path. This is extended to support asset paths of the form asset:namespace.name:vX.Y.Z.blend. Note that this path does not contain a directory path.
When loading such a library, Blender first has to find the corresponding .blend file on disk. It does so by searching for the file name in all asset library paths recursively. Obviously, the set of available asset files and their corresponding paths should be cached.
Embedded Linked Data-Blocks
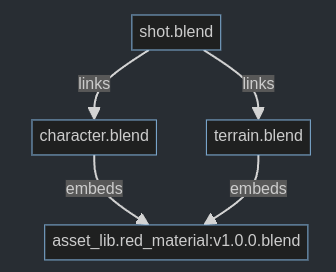
Support storing individual linked data-blocks in the .blend that uses them. This allows sharing the file with someone that does not have all assets installed. Just like normal linked data-blocks, they are also not allowed to be edited if they are embedded.
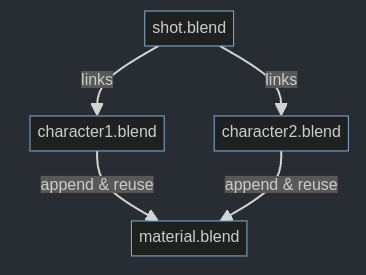
Embedded linked assets with the same file name are all considered to be equal. This is possible because of the immutability constraint mentioned above. So in a situation where there are multiple instances of the asset, Blender can choose one arbitrarily. For example, in the situation below, there are actually three stored instances of the same material data block. When loading shot.blend, any of those can be used. If the original asset does not exist anymore, it should still work, because one of the embedded materials can be used.
Discussion
This section explains and justifies some of the design decisions in this proposal.
Asset Identifiers
Are globally unique file names realistic?
I think they are. This is quite similar to how addon or operator names must be unique already. Enforcing a specific file name structure can help with that by forcing the asset author to think about what a good namespace name would be. It also enforces the use of versioning.
Can we use unique data-block identifiers instead?
Technically yes, ensuring uniqueness on the data-block level can work, but it comes with additional challenges:
- Asset authors have to come up with more unique identifiers if there are multiple data-blocks in an asset file.
- It’s not enough to give data-blocks that are marked as assets unique identifiers, because they might use other data-blocks internally that are unique too, even if they are not an asset themselves. For example, a procedural object as an asset might indirectly use a mesh, a material and a node group data-block. Sometimes it’s even hard to find all the data blocks that would need unique names.
- Deeper changes are necessary in Blender because right now the proposal assumes that asset deduplication happens just based on
Library.filepath.
Can generated unique identifiers be used?
Technically yes. For example, one could generate new unique identifiers every time the asset file is saved, or a hash of the .blend file can be used as identifier.
However, I expect this to make authoring assets harder where one might repeatedly change the same asset file before it’s published. Creating a new identifier and maybe a new version every time seems unnecessary. Furthermore, generated identifiers are generally not human readible which makes it much harder to debug any potential issues.
Having the identifier and version clearly visible makes it much more obvious at a glance how the system works.
What should the namespace in the asset file name be?
Anything goes, but everyone has to try to find something that’s somewhat unique. The name of the author, or project or a combination of the two should work. Using some (semi-)random string works too.
How does the asset file name correspond to the asset catalog?
Both are completely independent. This is important because one might want to move the asset around between catalogs without breaking files that link the asset.
Can the directory path of an asset be part of the unique name?
Technically yes, but I think that would managing asset files harder, because one can’t move them around between folders for better organization anymore.
Can the identifier and version be stored in the .blend instead of in the file name?
Technically yes. We can store file level data in .blend files (tried here). However, there are also some downsides:
- It’s much less obvious what file an asset belongs to. One couldn’t e.g. search for the linked asset file name on disk to see if it exists anywhere.
- Makes it more likely for version numbers in the file name and file contents to go out of sync, leading to confusing behavior.
- Might require additional data to be stored in
Librarybesides thefilepathto identify the asset file.
Not sure how much people value being able to choose custom file names in their asset libraries. I currently don’t see much of a benefit in separating the file name from the file identifier, but either way should work in this proposal.
Data-Block Management
Can embedded linked data-blocks go out of sync with the original?
Technically yes, within limitations. This can happen because the embedded data block might have versioning applied already, that the original has not. Furthermore, Blender does allow some kinds of edits to linked data-blocks like changing the selected node in a node group. Even with these possible deviations, it still seems ok to consider them to be the same data-block.
Technically, the original asset file could also be changed after it has been embedded, but that conflicts with the immutability requirement and should practically never be done if the asset has been published already.
What is the default behavior for adding assets?
For assets shipped with Blender, we should always link and embed them. This makes sure that files will still work in future versions of Blender, when we ship a potentially different set of assets.
For other assets, just linking them is probably fine as default. These are assets that the user installed, so it’s more obvious that .blend may depend on them. There should still be an option to embed all linked data-blocks.
Why support embedding linked data-blocks if we have packed libraries already?
Embedded data-blocks can be more performant and memory-efficient.
- They can be loaded like other local data-blocks and don’t need the overhead of parsing another library.
- Packed libraries embed the entire library
.blendfile which may contain unused data-blocks and their own SDNA.
How does this relate to the “Append (Reuse Data)” mode?
This mode was troublesome from the start, because it can’t actually detect if data can be reliably reused or if it was changed already. It can probably be removed.
Note that when importing certain assets, we might still want a combination of append and asset-linking. For example, when adding a mesh object, we may want the object to be appended and the mesh and material to be asset-linked.
How to edit imported assets locally?
Asset-linked data-blocks are generally not editable because they are linked. That’s true even if they are embedded. Like existing linked data blocks, assets can be made local and then they are editable. It may potentially be useful to keep a reference to the original asset that it came from.
What happens a data-block that uses assets is appended?
There are different possible solutions:
- Appending a data-block also appends all indirectly referenced data-blocks. This can result in duplicate data-blocks, because appended data is not asset-linked anymore, so it can’t be deduplicated.
- Indirectly asset-linked data blocks remain asset-linked. This seems more useful overall. It may be good to embed the assets by default in this case because users expected appended data-blocks to work without references to other files.
Personally, I’d try to keep assets linked for as long as possible until the user explicitly makes them local.
Misc
What about existing assets?
We could allow the proposed asset linking for existing asset files, but I think that would cause problems because there was no uniqueness requirement before, which is essential. Old assets can just use the existing link and append features. Old assets can be detected because they generally don’t follow the proposed file name structure. If they already do, great.
Can this be integrated with the extensions platform?
Yes! I could imagine people being able to share files which use assets that are available on the extensions platform. Since the asset file names have unique names, Blender could potentially download the required assets automatically (given user consent of course). The extension platform can also store older versions of assets.
Can we prevent users from changing asset files after they are published?
Not really. There will always be ways to overwrite or replace an asset file without changing the name, even after it has been published. There might even be valid reasons to do that in rare cases when the impact is known. We could introduce some safeguards though. For example, we can make some asset files read-only (e.g. the ones we ship with Blender). Furthermore, when trying to overwrite an asset file from within Blender, there could be a dialog that asks whether a new version should be created instead.
Can assets be updated when new versions are available?
Given that the version number is part of the file name, Blender should be able to detect when there is a new version of some asset file. The update probably still shouldn’t happen automatically in general, but the user can be prompted.
Summary
This document proposes a new approach for importing assets that solves existing problems in a way that seems quite feasible to implement. What do you think?