This workshop took place at the Blender head quarters in Amsterdam.
Present
- Lukas Tönne
- Hans Goudey
- Jacques Lucke
- Simon Thommes (afternoons)
- Dalai Felinto (kickoff)
- Falk David (sporadically)
Notes
These are the meeting notes we took during the workshop. There is also a blog post summarizing the different topics.
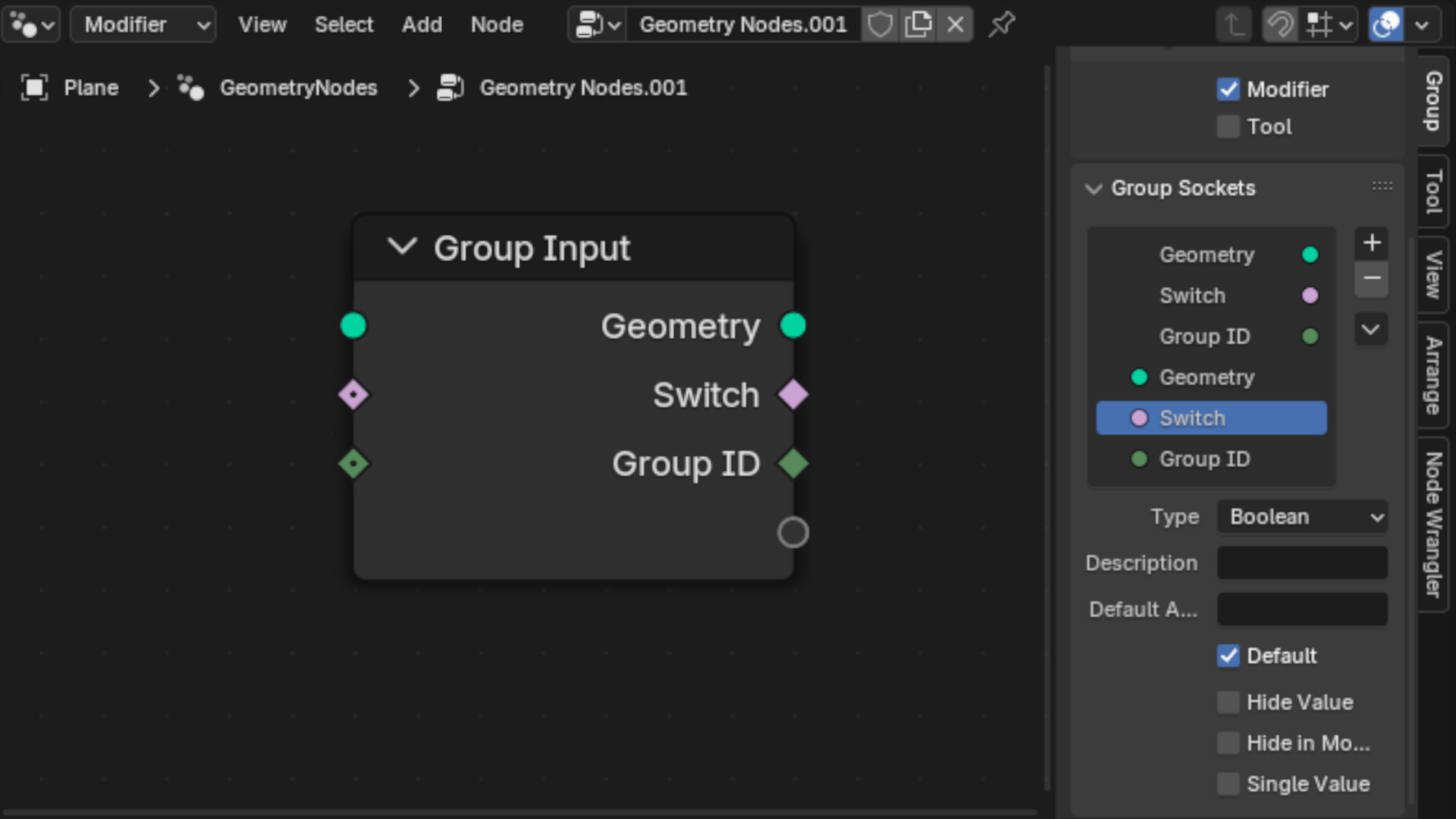
Use a declarative approach to separate the behavior a user wants from how it’s actually implemented. Users pass in “behaviors” to the solver which chooses how to evaluate them. Behaviors are implemented as closures or bundles.
Closures
A closure is basically a callback with some information stored inside.
The closure type cannot be statically propagated, so the types for closure creation and evaluation are separate on a low level. There should be high level tools that build on top of logged types to propagate types.
Closure input and output mapping can be based on identifiers (like node groups), because the closures and closure evaluation are built separately. The identifiers are exposed more publicly so it may not be possible to generate them automatically.
Mismatched closure types
- Missing socket
- Default value is used in evaluate node
- Incorrect socket type
- Implicit type conversion happens as possible, falling back to the default value.
There should be warning messages when the closure types don’t match.
Visualization
- A double link might help to signify that data flows backwards for the closure evaluation.
- On the other hand, it’s quite different from gizmos where the backward flow is for UI purposes rather than evaluation itself.
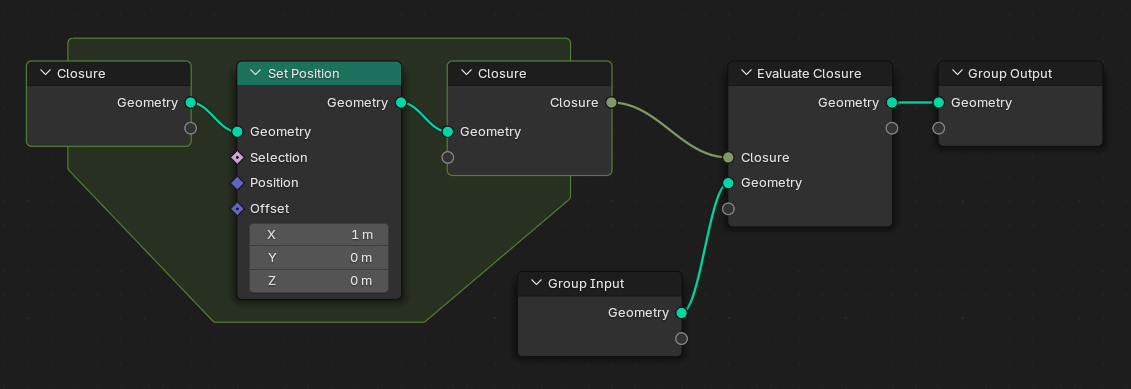
Bundles
On a low level, the types for the pack and unpack nodes are separate, meaning they have completely separate types. There should be high level tools to equalize types.
Many points from closures apply here too; conceptually they are a special case of closures with no inputs.
Bundles are syntactic sugar in the end, they should function the same as passing the links around separately (with some extra possibilities of runtime typing).
Bundles can be nested.
Bundles don’t have index access. We should avoid depending on the order of elements in a bundle. A bundle is like a dictionary while a list is like an array.
This relates to previous designs for extendable sockets (for example used for passing an arbitrary number of fields to the capture attribute node). Nodes that have extendable sockets (like the raycast node) should also process bundles.
Bundles will be useful for other node systems too (for example passing many PBR textures around at the same time). Shader nodes would have more constraints on the types, they must be statically known.
A useful operator would be a “Separate Closure” operator that would add a separate node based on the signature from the last evaluation.
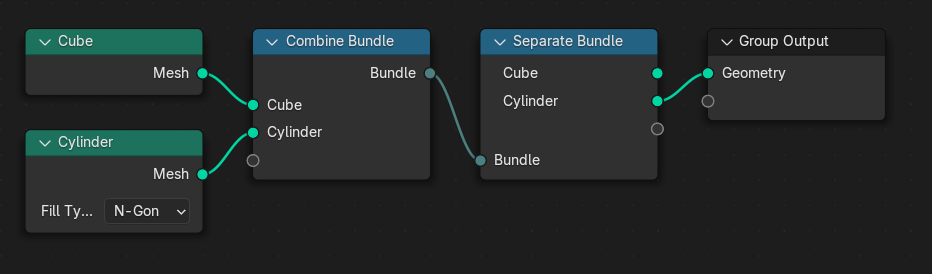
Bundle Nodes
- A node to retrieve items from a bundle based on an identifier: “Get Bundle Item”. It should have a “Remove” option that’s enabled by default which can be more efficient in some cases. It also needs a boolean output “Exists”
- A “Set Bundle Item” node which adds an item to a bundle with a name and an identifier.
- “Get Bundle Identifiers” with a bundle input and a string list output.
- A list of strings is also useful to reference a group of attributes in many other places.
Visualization
Bundles can be visualized with a thicker “udon” link. The link can still just have a single color though-- it’s too complicated to try to display all the inner colors inside.
When it’s known statically, bundle links should be dashed if they contain fields.
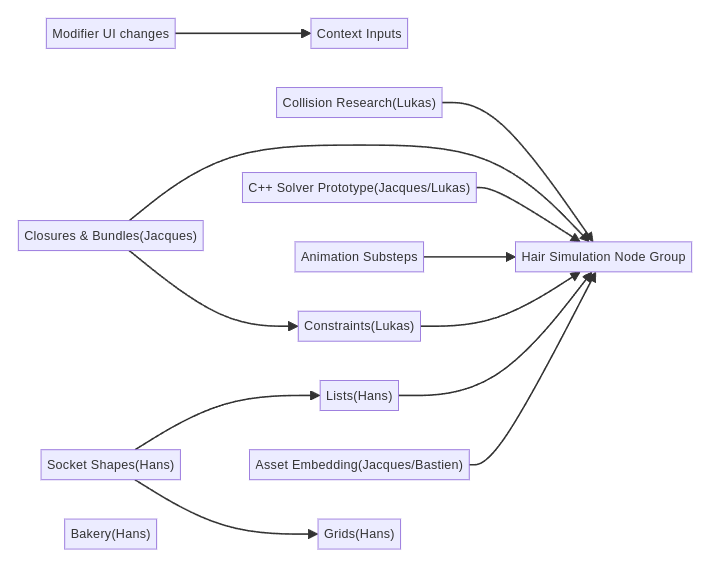
Context Inputs
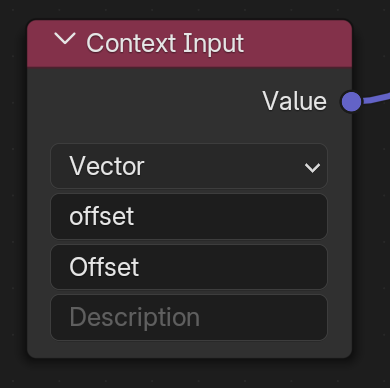
Reasoning
- We have no way to override existing inputs like node tools inputs and the scene camera.
- We have no good way to pass the hair system’s surface geometry in a flexible way.
- There is a lot of boilerplate necessary to pass the same input to many places. Example video of a workaround by Erindale: https://youtu.be/xBM4BPpfbUg?si=K1WEfVgdbBZfiBe_&t=64
- We need a more flexible replacement to the “Is Viewport” node, which is often used to control an interactive/quality switch.
A new “Context Input” node provides a way to retrieve data from an arbitrary higher level of the system.
Context values from builtin nodes should not be visible by default to avoid cluttering everything that uses a contextual builtin node.
Node group context inputs from builtin nodes should only be created when you actually use a socket. Removing a link from a socket doesn’t remove the group input.
In the modifier UI, if the context input is not overridden, an operator button displays to the right of the button to enable the overridee.
Group Input Defaults
Add a new output node that allows defining more complex defaults with nodes.
Design document: Group Default Node [Proposal] - HackMD
- This has some problems when the default is configured when it wasn’t before-- the behavior of node group instances may change.
- We propose to not specifically solve this problem for now. It’s not so different from the existing tradeoff when defaults are changed, and user feedback might make the proper solution more clear anyway. Moving forward with the implementation is more valuable.
- For forward compatibility and workflow breakage:
- The new group default node system should coexist with the existing field default dropdown in the node interface for several versions.
- Once the old field default dropdown is removed (at a major version change), we should have a label directing the user to the new system for several more versions.
Asset Embedding
This is an ongoing design topic that isn’t discussed fully in this workshop. It’s necessary for the other designs to work though. We did decide that to solve data-block name collisions from multiple versions of the same asset, libraries would be created for those duplicate assets to give a namespace and avoid changing the ID name.
Solver Implementation
XPBD
- Find all colliders before the substep loop.
- Integrate forces to change velocities.
- Translate positions based on velocities.
- Collision detection “broad phase” prefilters colliders.
- Find actual contact points to build contact constraints.
- There may be multiple contact points for a specific curve point.
- Alternate between Gauss-Seidel steps and Jacobi solver steps.
- In the Gauss-Seidel step, every constraint is processed separately, but first separate contraint islands have to be found.
- Without self collisions, all the points in one curve would be one constraint island.
- Solving the constraints changes the positions directly.
- In the Gauss-Seidel step, every constraint is processed separately, but first separate contraint islands have to be found.
- Calculate new velocities based on old and new positions.
We will need a graph coloring node.
Constraint Types
- Collision
- Edge length
- Bending
- Twist
- Pinning
- Friction
There are other types of constraints too.
Modifier UI
Parameters should be indepent from each other as much as possible
Possible panels:
- Material Properties
- Settings for the edge length and bend constraints (stiffness, damping, restitution)
- Pinning
- Surface pinning (enabled by default)
- “Goal positions”
- Collision
- Collision collection
- Self collision
- Forces
- Gravity (use scene gravity)
- Wind
- Quality
- Solver Substeps
- Collision substeps
- …
Generic Modifier UI Features
Add items to the right click menu for modifier buttons:
- Toggle Single/Attribute
- Override Value (checkbox)
- Switch Object/Collection (for geometry input socket type)
- Hide Input (for a future input hiding feature)
Remove the attribute toggle from the modifier UI.
Node Group UI
The solver node is just a single node group.
Behaviors are separate nodes that are connected in as bundles/closures. Behaviors set up in separate nodes include:
- Gravity
- Colliders
- Attachment
The solver node has some internal constraints built in, including:
- Stiffness
Lists
Lists are necessary for implementing constraint evaluation with nodes because the solver needs to store values and do processing per constraint rather than per point.
The first version of lists would be very simple and just support plain arrays, no nesting and no fields.
List Nodes
- List
- Length (could be a field)
- Field
- Add Element
- Remove Elements
- Get Element
- Concatenate Lists
- Filter (gather)
- Index list or selection field input
- Different modes eventually (we will probably want a closure predicate)
- Replace Elements
- Index list or selection input
- Two list inputs, one is the size of the indices/selection
- A list output with replaced elements
What does the index mean when list and field contexts are combined?
To keep things simple we don’t have List of Fields, we only have Field of Lists (aka list field).
A syntactic sugar that would be useful is a multi-input socket that concatenate items to form a list.
Guides Workflow
Two workflows:
- Only sculpt the guides, all child hair is generated procedurally
- Guide hairs are selected/generated as a subset of original geometry
The biggest limitation is that we can’t store the fact that curves can’t be influenced by multiple guides. This is why we have a special builtin node for interpolating child positions rather than implementing it as a node group. Actually storing this multi-parent information is probably not so bad, something like 36 bytes per curve if each curve has 4 parents. This calls for lists (potentially nested lists), and potentially list attributes.
Other features are important for making the guides workflow work properly:
- Tangent space calculation
- Custom normals
For Each Geometry
Processes every unique geometry in an instance tree, creating the same behavior we have in current builtin nodes. The output node can have multiple geometry outputs. There can also be output attributes-- fields are evaluated on the output node. Non-instance geometry is processed in the same way, just like builtin nodes.
The instance component of each unique geometry isn’t passed to the inside of the zone. The zone doesn’t process non-top-level instances-- that use case isn’t addressed here.
Adding the instances as a separate input to the zone may be helpful.
There is some existing design work here: #123021 - Proposal: Instance's References Foreach Loop - blender - Blender Projects
Modal Node Tools
In Blender currently there are two types of modal operators:
- Operators based on the initial state (like bevel). These have redo panels.
- History dependent operators using the previous state at every modal step. These don’t have redo panels.
Theoretically it would be useful even for history dependent operators to have redo panels. Since the redo happens with a single “exec” call, it would require the context information (like mouse position) of every modal step to be stored as RNA lists.
If boolean inputs have keymap items set up, they should not be displayed in the redo panel.
One issue with this design is that the keymap is defined as part of the asset. Usually for operators the keymap is defined at a completely different level. It should be possible to override the group’s keymap in the preferences keymap. The preferences could store keymaps associated with assets that are operators (rather than associated with operators directly). Local node tools that aren’t assets always have the default keymap that’s part of the node group.
Last Properties
The “Last properties” system doesn’t work for node tools because all node tools use the same operator. We really need a map from asset to the last properties for that asset, but it’s not clear where that should be stored (currently for regular operators it’s stored in the type). We don’t have a good solution for this yet.
Socket Shapes
We need socket shapes for:
- Images
- Grids
- Fields
- Dynamic
- Single Value
Shader nodes wouldn’t need to change, at least not much. The compositor would change to use image sockets for images and it would open the opportunity to have sockets for many existing node properties.
In the same release we change the socket shapes, we will add features to improve the debugging experience, like tooltips describing the expected/current “structure type” and icons of the current data drawn on top of links.
Field Context Zone
This is a way to implement a custom field input, and a replacement for part of the older “geometry field” concept that we decided against. The zone has a geometry input and list outputs. Inside the zone, the geometry is the context geometry of the field evaluation. This resolves the duplication of nodes like “Sample Index” and “Evaluate at Index” which are the same, but one has a geometry input and one is a field input.
The attribute statistic node is another example where this would be useful.
Besides the geometry context, this would also work for volume grid and list contexts.
Old Particle System Features
- Emission already handled by the hair system
- Substeps (needs generic improvement of simulation/depsgraph evaluation)
- Collisions
- Quality More substeps specific to collision handling
- Distance Try to avoid adding this option to the new system
- Impulse Clamping Part of solver
- Collision Collection Part of solver
- Structure
- Vertex Mass Try to configure as mass per length
- Stiffness Should be configured independently from mass
- Random Replaced with fields
- Damping Part of solver
- Volume
- Air Drag Should be exposed somehow
- The rest of the options can be skipped
Extra Modifier Evaluation Outputs
Modifier evaluation can also output a bundle. The object info node retrieves the bundle. Each modifier implicitly passes the bundle through if it has no bundle input or output. If a modifier node group does have a bundle input or output, it processes the previous bundle.
The extra data bundle could contain a closure. That could be useful for encoding a force field and its evaluation to increase shareability. There may be additional constraints on these closures like not depending on anonymous attributes or some fields that have difficult lifetime handling.
Internal Data Sockets
- KD tree
- BVH tree
- Bake reference
These can use the same socket type / color: black.