Proposal: Generate stub files for blender
I would like to improve blender python auto completion setup. Community created projects to mitigate this issue (see below) but I think this is very basic functionality that should be shipped with blender. I am willing to work on topic in the next months to come. In this post I want to complete design and get feedback.
Brief: generate official blender python stub files (.pyi) as part of release process. Stub files are official way to provide type information for auto completion.
Problem and solutions overview
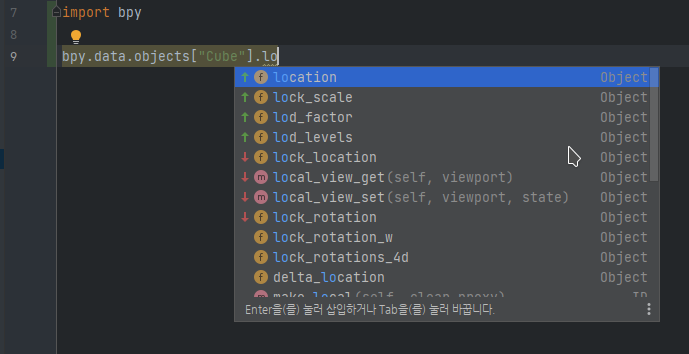
The problem is that most IDEs can not inspect blender python API, because it is compiled from C. Therefore auto completion sucks.
The problem we are facing in Blender is problem of all c-compiled python modules and there are some solutions to the problems:
Argument clinic (from python developers)
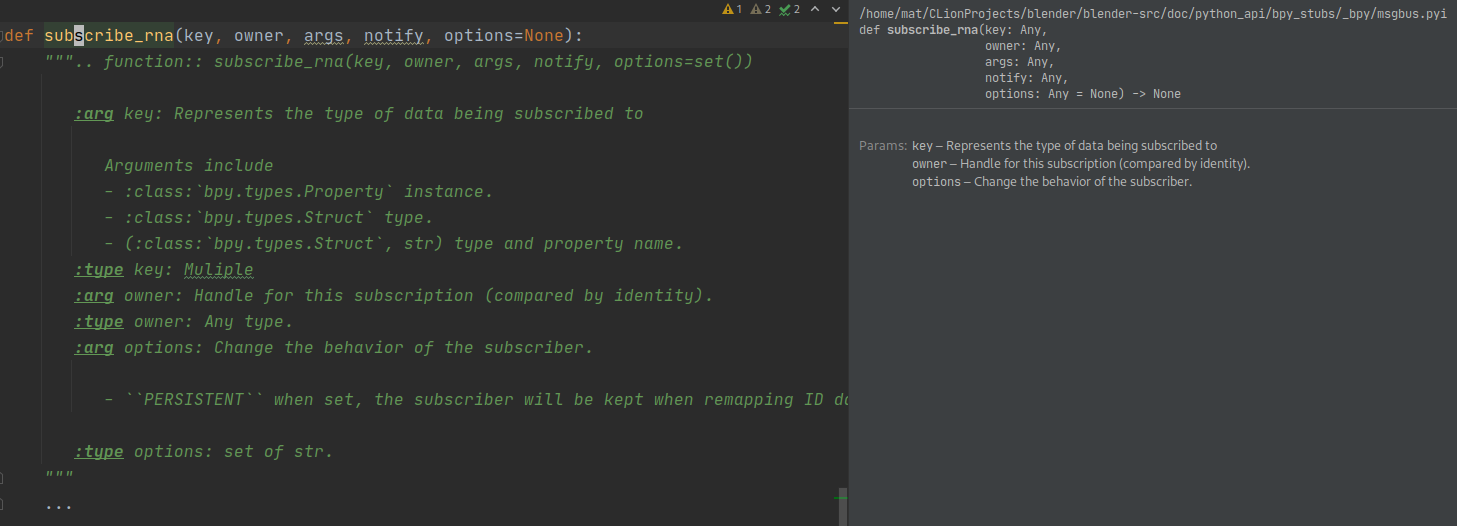
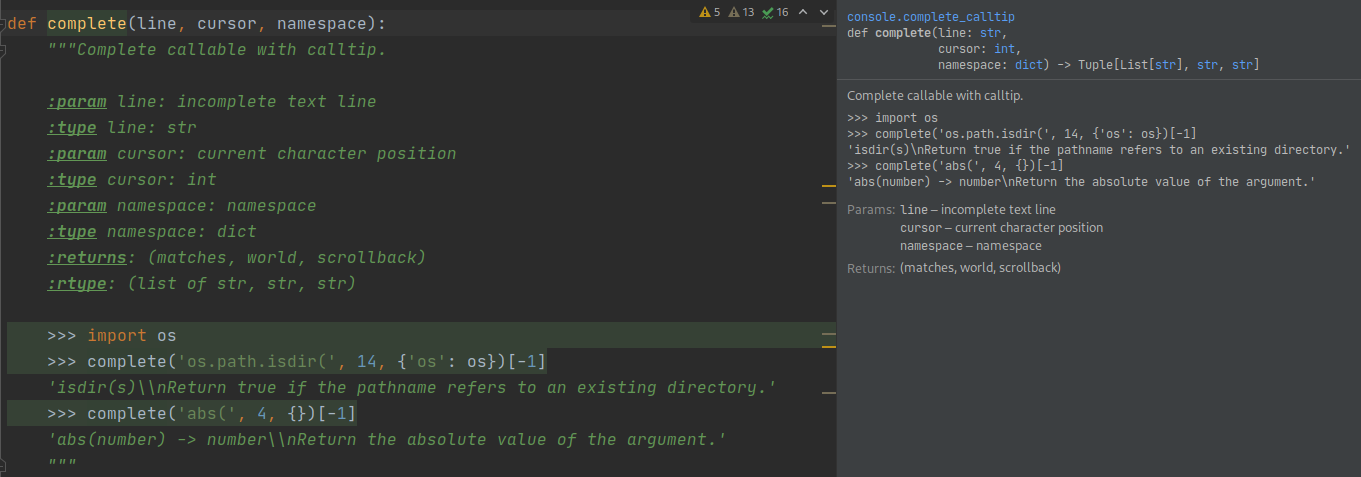
Argument Clinic is a Python internal tool that adds data about function signature to the c-compiled function. This data is stored in __text_signature__ attribute and it allows for the use of inspect.signature.
Pros:
- it works really well, somebody else has done the job
Cons:
- it is tightly integrated with python source code, integration with blender will be hard (code example: _abc.c.h). It is all or nothing situation. In theory we can take only elements from Argument Clinic, but including only part of the pipeline will be very error prone in long run.
- it is python internal tool - the future of the tool is uncertain
- it works only with
make
Example:
# Python/clinic/bltinmodule.c.h:533 <- strange name - see the docs
PyDoc_STRVAR(builtin_len__doc__,
"len($module, obj, /)\n"
"--\n"
"\n"
"Return the number of items in a container.");
>>> len.__text_signature__
'($module, obj, /)'
>>> print(inspect.signature(len))
(obj, /)
>>> inspect.signature(bpy.utils.register_class)
ValueError: no signature found for builtin <built-in function register_class>
Stub generators
There are not that many generators. The ones I tried does not give great results in general, partly because they are mean to be hand tweaked and partly because blender has complicated python API.
- mypy (stubgen to be exact) - I compiled blender as module and managed to get it running - the result is not great, stubgen is meant to be hand tweaked
- make-stub-files - does not support c-compiled module
- python-skeletons - todo investigate
- pygenstub - todo investigate
Edit: recently I discovered that pytype, MonkeyType also can generate stub files, but did not have time to investigate.
Blender specific projects
- Blender-PyCharm (and forks) - one file implementation based on sphinx_doc_gen.py (this script is from blender repo, but it is quite hard to read and a bit under-documented). How it works:
- list blender modules
- Inspect modules (
dir,__dict__,inspect.members) - parse each element’s
__doc__(which is formatted inrstsphinx fashion) to get function signature
- fake-bpy-module - successful, but heavily object oriented implementation
- list blender modules
- based only on documentation generate python files (this same files are passed to generate sphinx documentation)
Pros:
- not so much work, single file implementation is possible (or as addon)
Cons of the above:
- every mistake in function signature syntax in documentation will cause script to fail, this is a lot of maintenance, see fake-bpy-module/src/patches
edit: @jacqueslucke mentioned also: code autocomplete and blender vscode.
Conclusion and work plan
For the last month I was experimenting with different solutions, the best seem to be either full switch to Argument Clinic or adapting Blender-PyCharm solution. Personally I prefer the later but I would love to discuss that.
How to do it
I have a few options on my mind:
- ship with blender addon/operator with ability to generate
blender-stubpackage
- pros: it takes minimal amount of space
- cons: you need blender to install stub files
- when releasing blender, publish package on pypi.org
- pros: standard way of distributing python modules
- cons: another thing for dev to remember about
- Ship blender with pregenerated stub files:
- pros: we can use standard frameworks (like
jedi,rope) for console and text editor completion. - cons: it will add megabytes to release (but text is highly compress-able)
- Create language server addon specifically for Blender (based on framework like pyls), thx for tip @rfletchr. This addon would provide things like completion, diagnostics, hoover information, formatting etc. In this solution we do not need to create stub files, as completion can be done inside blender.
I need to investigate this topic as I do not know how it integrates with IDEs, what happens if you try to use external packackes from pip and autocompletion from Blender…
- Pros: we can autocomplete collection, object, scene names; no need to generate stub files
- Cons: Probably client must be implemented as addon, separately for every IDE, for example for visual studio docs;
- Create custom script for pasing blender source files and extract information about function signatures. This solution is inspired by Argument Clinic and blender scripts like makerna.