Hey @Zuorion
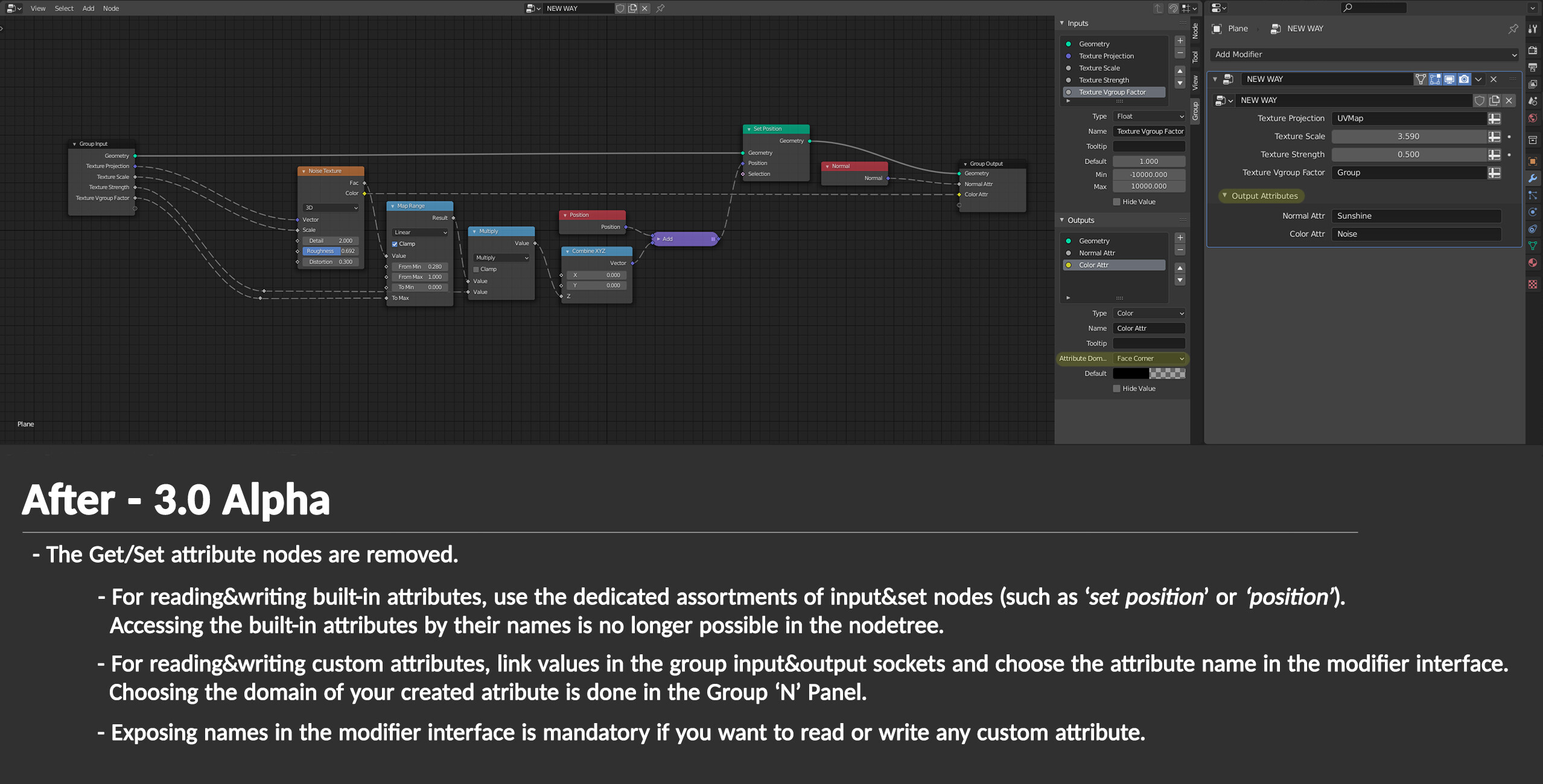
Currently, we can’t read/write attributes within nodetrees anymore. The goal of this topic is to talk about the nodes that lets us access any attributes.
Currently, it’s done externally in the modifier interface, please see more information about the new way here.
I also did a before-after comparison, perhaps it can help you understand what we are talking about ![]()