Thanks for this proposal. However I’m having a hard time wrapping my head around some corner cases. For me the biggest issue is, that it mixes different evaluation scopes on the same level of the graph.
As already mentioned by you, field nodes can’t just be evaluated, they need a context. You once write
and thus make the node the context.
Further down below you say:
I think it’s important to decide about this specific concept of the context and evaluate the different implications. Surely making the node the context is the more flexible approach and in my opinion be the preferred choice. However the context then can change quite drastically for each field being defined. Having the definition of the field in that case outside of the node itself makes it hard for the user understand what the context really provides. I would expect something more local. The field could be managed in a manner similar to sub-graphs in a group node, but on a per parameter basis. The weight parameter in your first example might just provide a small button to jump into the field-graph. The field graph, just like a group sub-graph provides a field-input node, that offers the full context, which the outer node itself (in this case Displace Points) provides. The output node of the field-graph just requires a single valued float in this case.
This approach also has a nice duality to expressions you also mention in your concept. The field-graph can be transcribed into an expression and without diving into the field-graph can be visualized as the expression on the node itself. Editing the expression would also alter the field-graph. So one could jump back and forth with textual and visual editing of the field itself.
What you describe is quite similar to the Attribute Processor idea. Just a bit more limited because you only allow a single output. The general idea of going into a different graph to make this kind of processing makes sense (which is why we built the Attribute Processor). However, we are still in the process of trying to find a good way to make it work in a single node graph.
Hi, Jacques, i think you wanted picture 12 (group gutts of the “Every Nth”-group) to be under picture 13, not under picture 11.
Btw, i’m superglad you joined the team.
I think it is fairly in-between the attribute processor and your same-graph-field approach. For me this proposal is not more limiting because of the single output, but more flexible because of the custom context the field-graph gets. Since every node can define the field context for every field it offers, we could much more flexibly react to specific needs of a certain field in each node. One thing I could think of might be a bevel node. In it’s context of the width field, it could provide the edge lengths of the edges going along the curvature of the bevel. That would be a very specific field highly tied to this node. Offering this on the top level graph feels a bit strange. My assumption is, that local field graphs would have a higher chance to provide a richer context, than the same-graph approach.
Another big advantage I see with local field-graphs is, that I as a user immediately see, what could be executed massively parallel and what is going to be evaluated up to the parallelism the graph itself exposes. Since fields will be evaluated per point/polygon/edge/voxel/… this would have a much higher potential for optimizations in cases my node graph runs pretty slow. If everything is entangled within the same graph, this is harder to separate.
Im not sure if I understand the proposal correctly, but imagine we were building a generic scattering tool and we want the user to be able to choose between different algorithms or possibly create their own one.
One pattern that could be useful for this would be higher order fields. Fields, that can take a field as an input.
We could expose a socket on the node group that expects such a HOF and provide our different algorithms / strategies as nodes. Inside the node group we can then pipe the internal data inside the user provided field to compute the final result.
The two things i like the most are:
1.: It looks like Blender (Dalai’s concept looks much more alien and is hard to watch for my weak eyes).
2.: Finally i can reuse my shader knowledge of procedural textures - manipulating their vectors by other proc. textures (or just numbers).
I’m dreaming of being able to demonstrate with Blender how simple Nature’s protein programs really are (think of plant growth). Thanks for the amazing progress Blender made. And regarding compatibility worries i agree with Dalai: for that we have the LTS.
@Grinsegold
I like the reference to shaders. Because it does extend the idea of fields beyond GN.
If the concept of fields is not narrowed to Geometry Nodes (but have its own “Fields” node editor), there might be other interesting uses which won’t be covered by discussions on fields.
Our old Texture Nodes are just a special case of using texture coordinates on fields.
(UV → COLOR … with UV:=R^2 and COLOR := R^3 ).
If fields could be accessed as textures from shader node tree, they would just substitute old Texture Nodes system.
In similar way, fields could be useful to forge sculpt brushes.
We do have those “force fields” in Blender. But, it seems that “force fields” are just another special cases of fields.
Another case might be fields of type (R^3->TIME OFFSET). Imagine a cached single tree animation. And imagine a forest of those. Such field could offset the playback of animation of cached tree, creating kind of moving forest effect.
I like much the idea of fields in Blender. And I am curious how it evolves.
I’m currently wondering why so many people talk about primitive data types w. r. t. fields. I also would like to see geometry fields. I can easily think about a node similar to the point instance node, that creates real copies of geometry. Using a geometry field would allow to make each copy unique. Is this something that’s ruled out, since you’re concentrating on primitive data types or would such a thing be possible?
I hope this proposal is still alive. While all of the proposals make sense and are clear improvements over the current way things work, I still find this to be the one that solves the most problems and better integrates into blender imo.
I think you’re right, trying real-world scenarios is the only way to determine which of these directions is the most appropriate to take. What do the nodetrees used in Sprite Fright look like when “mocked-up” to use either fields of anonymous attributes ?
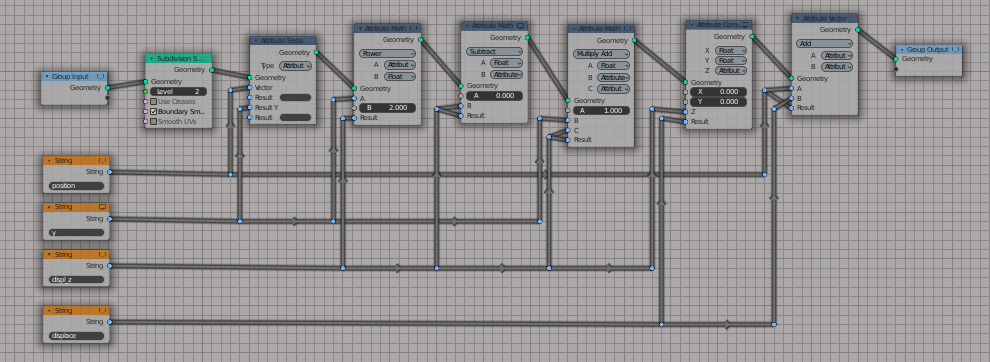
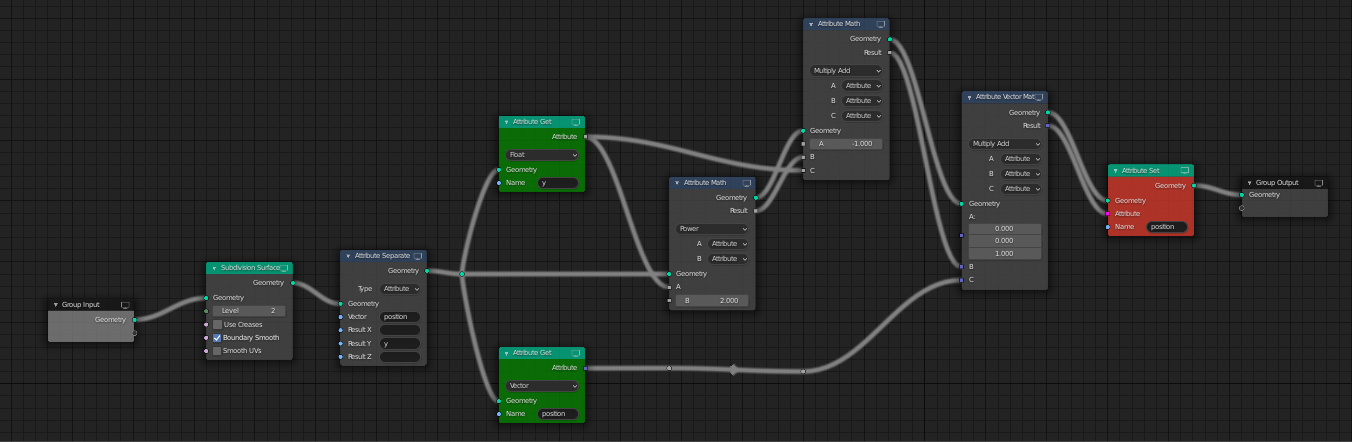
I would love to see a version with the fields proposal especially. Frankly (from your screenshot) I think splitting vector attributes (I mean when you single out position.Y) is still kind of convoluted. I would verge either on the fields proposal on the attribute processor one, because with those a “separate node” (like the one from the shader editor) makes it visually obvious that there’s a split happening, and with nodes that’s what I am looking for : visual programming. At a glance, the user can see there’s a fork, whereas in attribute nodes the “splitting” is represented textually, instead of through node links. It’s just too bad that the attribute processing would have to happen in a separate context, but honestly I could live with that… other software have this “limitation” and it works well enough for them…
That’s just the take of someone less versed in the coding side of things of course… but to be frank the weird layout of the attribute nodes might play a part in that. I think the dropdown for choosing whether to use attributes or values as operands could be closer to the actual number socket, and that would go a long way for readability.
edit typed too much, but at least I got my noobish opinion out in the wild
Atm, the “Attribute Separate” node follows old behavior. It does not return Anonymous Attributes.
Some thoughts … I fear this would be some typing too
In Geometry Nodes we keep track of side effects by chaining Geometry connections. No matter what, we need to build up our node tree by chaining side effects in a reasonable order.
Anonymous Attributes give more freedom than plain Attribute Nodes. We do not need to keep track of return values. Returned Attribute values are also retun-slots of Nodes. Node flows more accurately describe whats going on.
Plain GN does mix return values of Attributes with input slots (string names) of Attribute Nodes. Within a node tree with output values we have to keep track of Attribute outputs within Node Inputs. Resulting in a node flow which keeps track of “GN side effects” in a linear way. Node tree might do formally correct steps, but on a user level I get impression like I have my nose in assembler code. I have to go through step by step to get an idea of whats going on. Instead having a node graph which reveals by itself.
I hope no one throws tomatoes at me, but for me it feels odd and counter-intuitive.
I believe, a node tree with Anonymous Attributes likely is less verbose and easier to gasp than plain GN node tree. Imo, this is a big plus. With Anonymous Attributes we would still have to deal with side effects. We have to chain side effects in a reasonable way to get desired result.
Thinking about the fields approach …
I guess, it rather resembles a functional approach. It liberates us from keeping track of side effects. Without the need to burden ourselves with side effects, we could chain fields (functions) in a flexible way. Finally we apply our field to an attribute, and perform a side effect.
yeah and is there a performance penalty of keeping all those intermediate attributes all along the tree ? or is it more costly to delete them when they’re not needed ? because if I’m not mistaken right now they live indefinitely, right ? Ideally as a user I shouldn’t have to worry about garbage collection and as I understand it the anonymous attributes proposal requires the user to explicitly “save” attributes.
Good point.
There could be large objects. Without GN I already had enough opportunities to freeze blender.
But a GN modifier which defines 10 vector attributes. That is much more data which has to be stored in the memory. How could it work for massive “monster” objects, which already claim large parts of memory for themselves?
And now, after you mentioned manual “Garbage Collection” … brrrrrh!
Maybe, Anonymous Attributes could save memory space and scale better for dense monster objects?
Perhaps fields are the most memory-friendly solution for massive monster objects.
I had the same thought today as well, while making a “map range” node with attributes as input.
Do i use the attribute delete node to clear any temporary attributes?
Should i “recycle” old attributes after they did their job instead of creating new, better named ones to save a slot? What happens if one of my temporary attributes already happens to be a in use when my node group uses/ overwrites it?
I’m a big fan of the concept behind anonymous attributes as this would make things simpler; even with the increase in complexity they might bring.
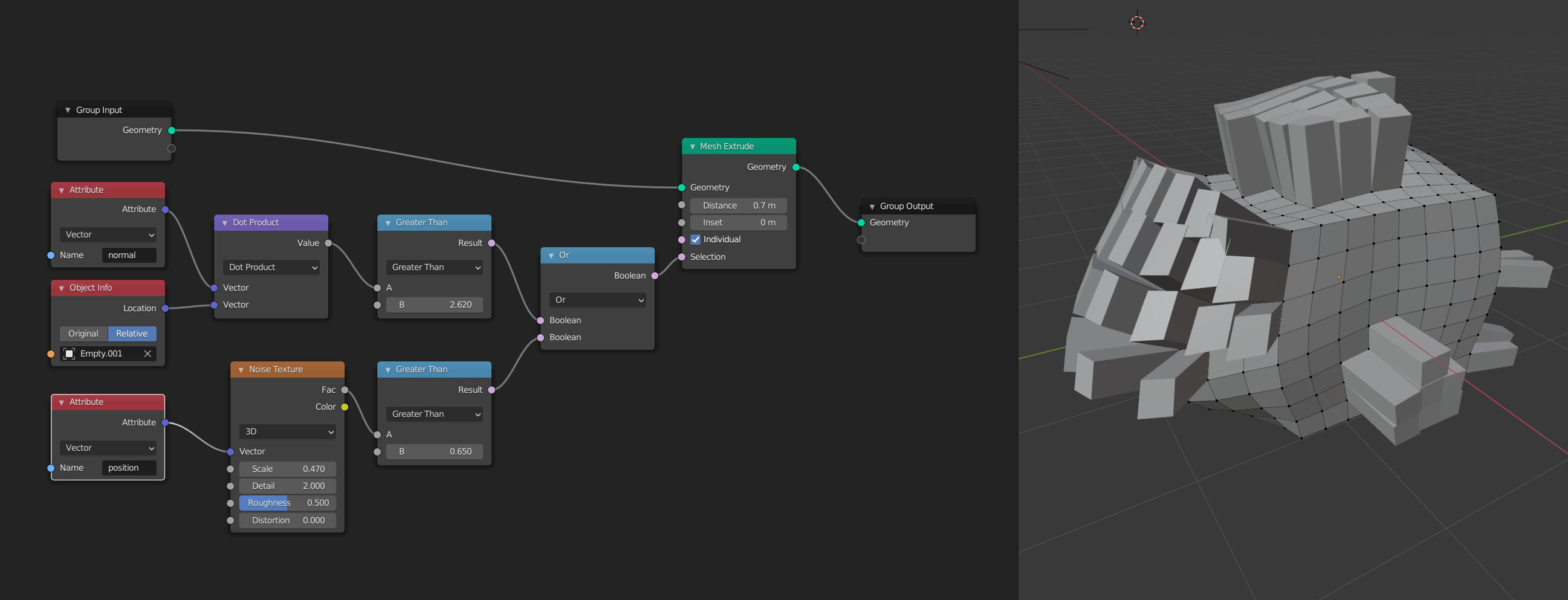
Hi all! Jacques and I have finished up a basic prototype of this proposal, the first of two prototypes. The prototype isn’t meant to be a complete implementation, and in order to get it done quicker we made some compromises, hacked a bit, and didn’t complete some of the features. But generally it should work well at giving an idea of how this would work in a more complete version.
Here is a screenshot of how selections work with this patch-- much more intuitive I think! Fabian’s extrude patch is already there as well, as an example of a mesh node that takes a selection input.