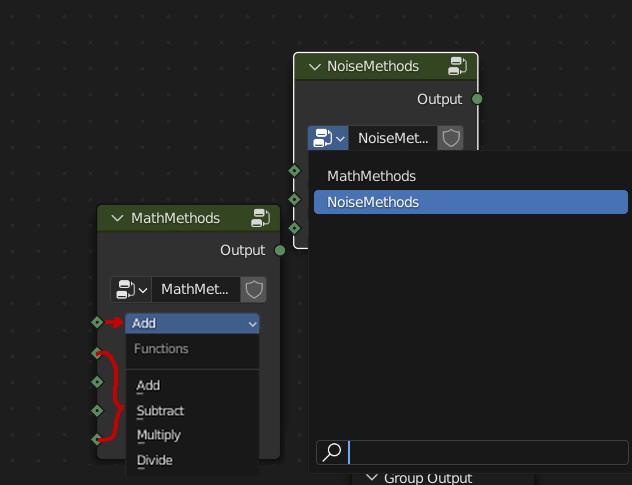
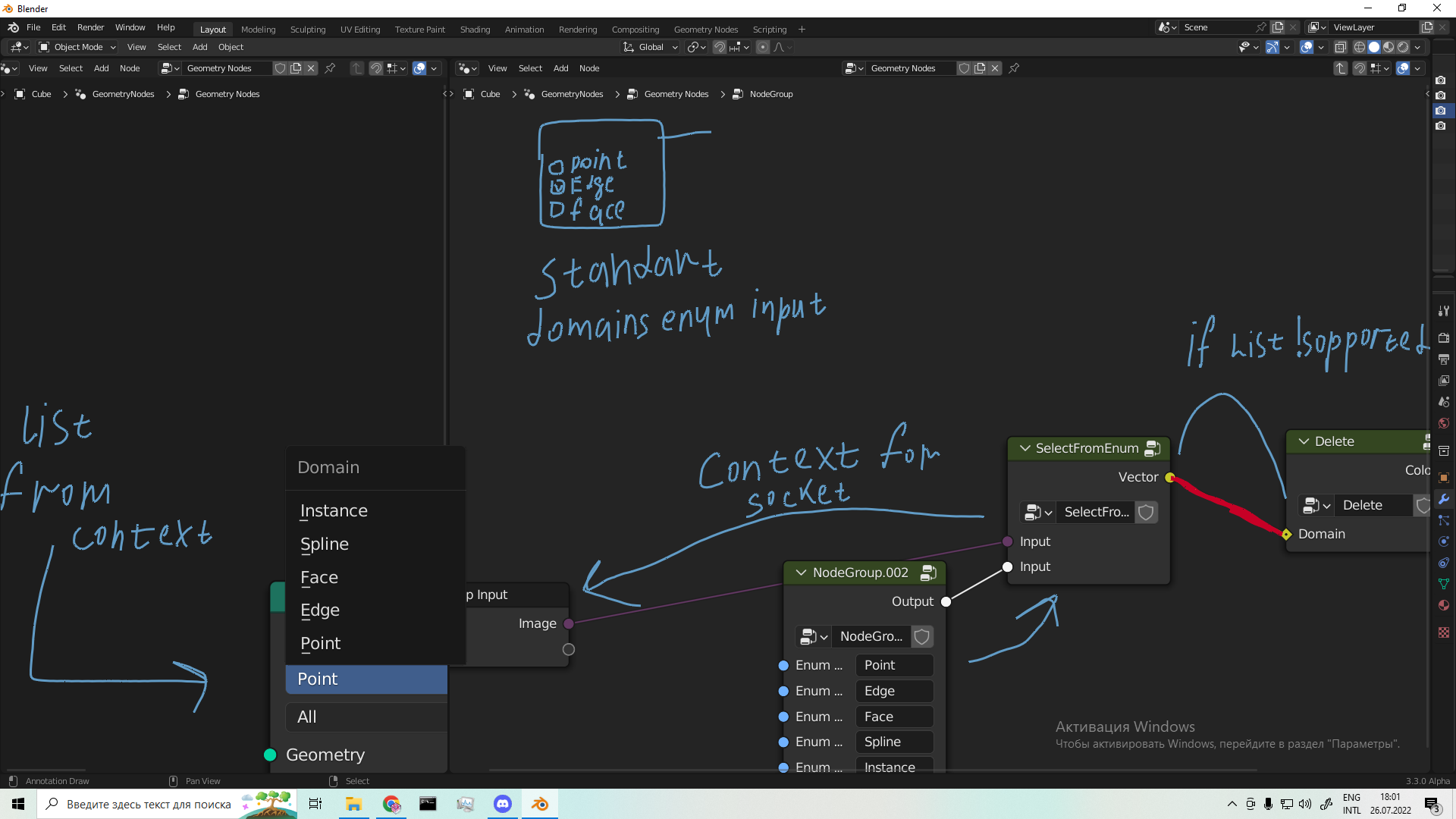
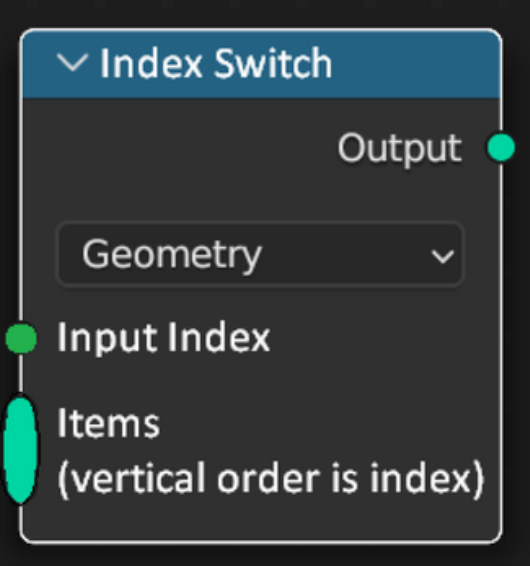
Not saying there are no other solutions, but I think always breaking node groups just because the enum is reordered or you want to add something in the beginning feels wrong.
This would be technically possible, but does not have high priority for me atm. Of course changing the operation for every element also has a certain performance cost (although if done right, you would not have to pay this cost when only one operation is used).
That’s also not unreasonable. Creating enum data blocks should work and I’ve thought about that before. The main problem is that it seems highly unlikely that a new ID data block will be accepted just for enums. There is precedence where something similar has been done before: color palettes. However that is also seen as a mistake by some. Personally, I’m not sure when some piece of data becomes important enough to justify that it becomes its own data block.
In the original proposal I essentially worked around this by saying that you should put the Enum node into a node group to reuse it.
Right, internally the data that is passed through enum sockets from left to right is an identifier for a specific enum value (which is an integer). However, for the proposed enum sockets to work we also have to infer the enum type (which contains all the possible enum values) from right to left. So that when you expose an enum socket to the Group Input, the correct possible enum values will be shown in the parent node group.
I’m not sure which Blender version you are using but in Blender 3.0 you should see a data type selector in the sidebar that you are showing:
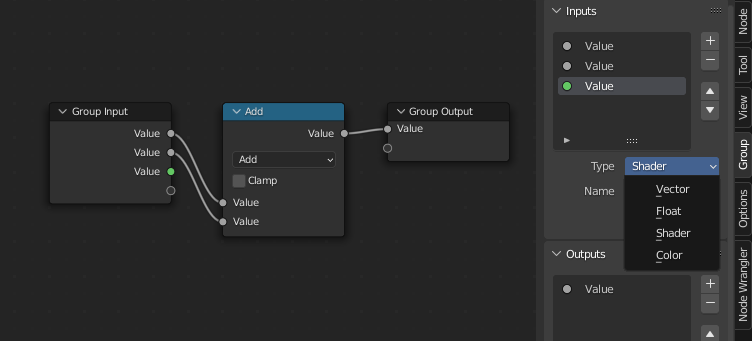
That can definitely work, given we have some kind of enum data block, or a non-data block alternative. I wonder, how would you expose built-in enums with this approach (which definitely do not have their own data blocks).