Hello developers!
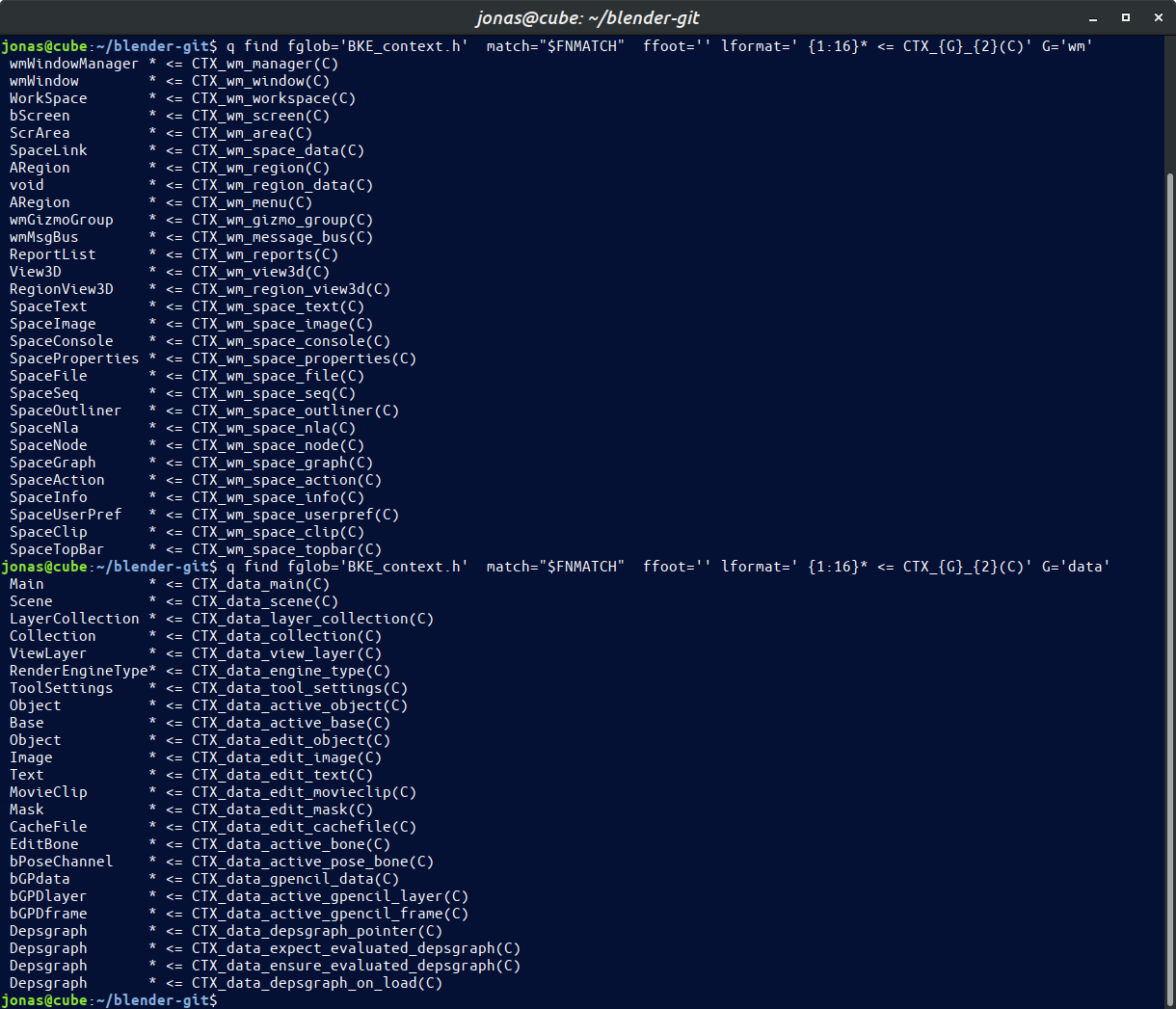
I am new in this (blender dev) context, but a senor consultant in SW-Engineering. I often find myself digesting non-trivial code-bases using structure/meta - data extraction with python, graphviz dot and the like. It started a long time ago and that habit has proven quite useful and appreciated.
No, I’m not talking about what Doxygen does. That’s kind of trivial.
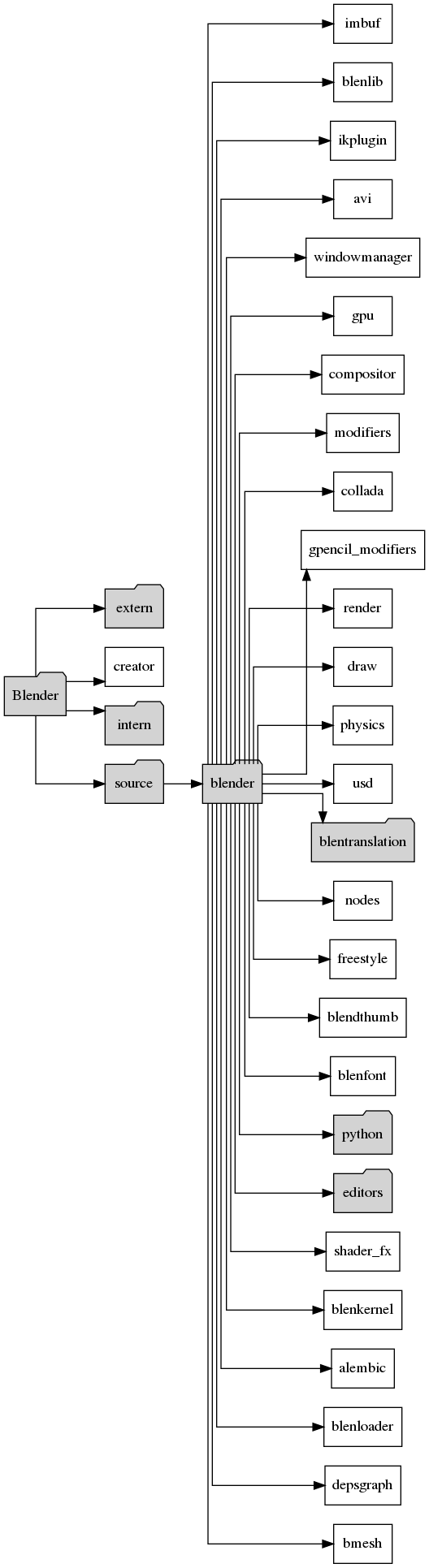
I’m talking about what can be done to extract dependency-graph from a convoluted or deps-agnostic build-environment, State-machine graphs from scattered graph-agnostic code-fragments. Similar with interaction diagrams and event-propagation. To the point where you could rearrange an entire code-base automatically …
The value is, of course, the resulting meta-data and visualizations are always up to date, since they are generated from the code-base.
So, while I’ve already started, taking notes while breaking it down, I was wondering…
- Is there anyone else out there doing similar things?
- Are there more of this in there that I have not found?
Please tell me of it so I can align my efforts with what exists in the project …
Oh, and although I initially do this mainly for my own convenience …
As a consultant I’ve been in many different development cultures/environments. Still, a common and very interesting side-effect of presenting this meta and visualizations is that people after a while spontaneously strive to align their work, folder-structure, build-rules, file and function-names, with the rules I use to extract the information. More so the more quality the visualization have. I’ve also noticed a clear positive effect on the common understanding of the shared code-landscape when this happens. It’s an interesting meta-cognitive mechanism that is also one of the few instrumentation’s that clearly help handle continuous improvement in stagnant legacy.
So, If you are, or know of someone who is, interest in this aspect, please inform them/me?!
Cheers!
/jonas
PS:
Note! This is raw. I will soon present a crisp blocked layered arch-view auto-generated from the same meta…
:DS