Info
Developers or artists interested in contributing are welcome to join at the links below.
- Workboard - plans, ongoing work, and community tasks
- Chat Channel - general development communication
- Video Call - dailies at 14:00 CEST
- Meeting Agendas and Notes - updated throughout the week
Meeting Notes
-
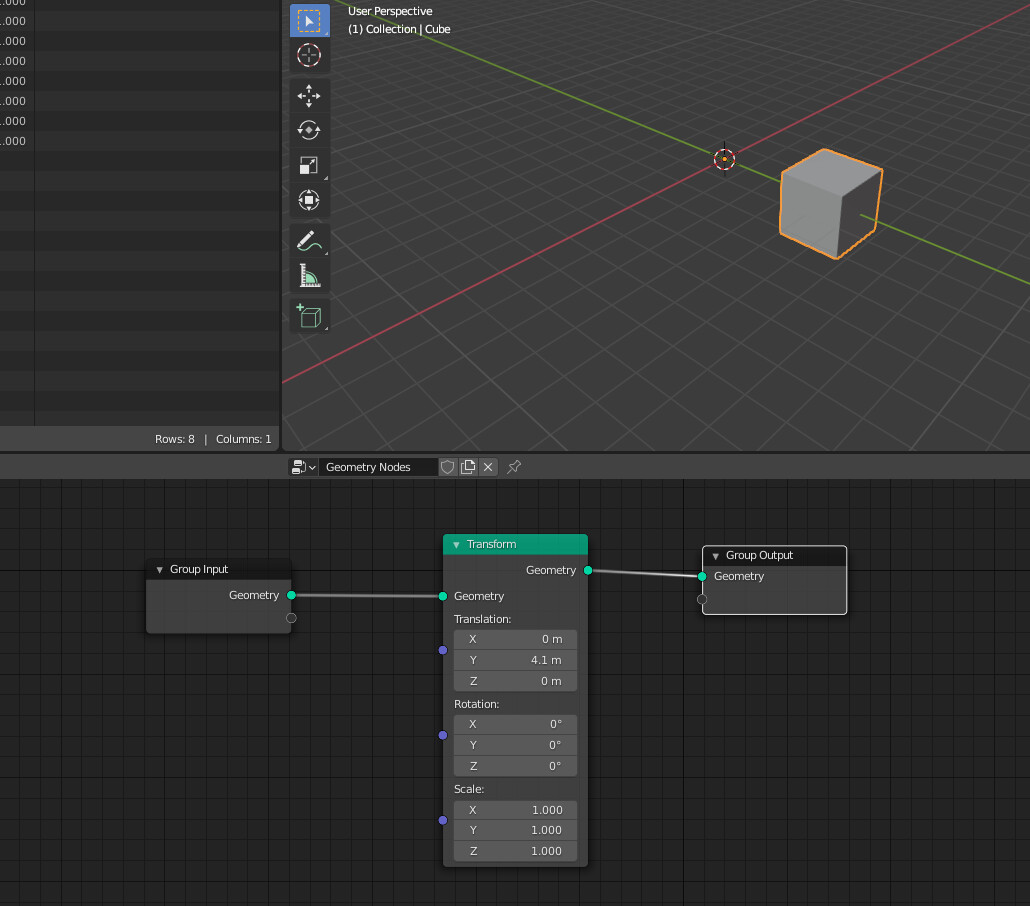
T91529: Object/Collection info nodes redesign for fields.
- It can work just like the Group Input node as to how to add new outputs and specify their data type.
- When using the socket input for the object/collection, the attributes are then exposed to the Group Input, so the mapping can happen in the modifier (or higher node group).
-
T90871: Join/Switch node redesign for fields.
- Multi-input sockets don’t work that well for joining attributes since the order would matter on for every single attribute
- Defining the order in multiple places means it’s easy to get wrong.
- Does the node really need to handle joining anonymous attributes? They could just be added afterwards.
- That may be less efficient though.
- Multi-input sockets don’t work that well for joining attributes since the order would matter on for every single attribute
-
Curve fillet node sign-off/demo.
- Not creating the fillet for straight corners may cause issues when someone relies on the curve indices.
- However, the alternative is adding many points in the same place, so changing this doesn’t feel like an obvious improvement.
- It could become an option in the future if necessary.
- Not creating the fillet for straight corners may cause issues when someone relies on the curve indices.
- Fields Visualization:
- Use the Diamond with a circle dot for the sockets that can take either field or data.
- Insist on the dashed line for a final solution (see how it looks).
- Meanwhile use 0.7 thickness for function flow.
-
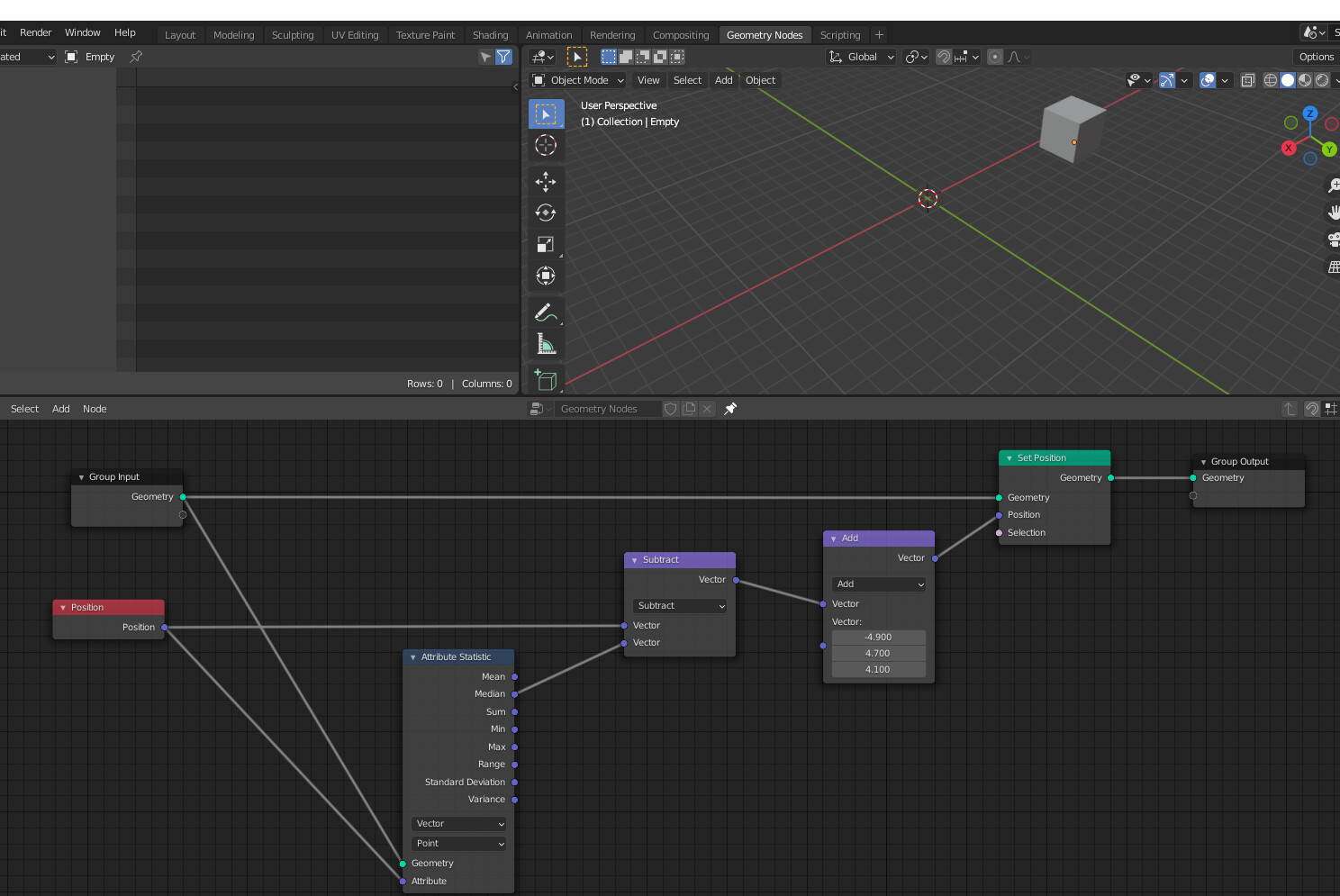
T91373: Random Number node.
- Multiple types in the same node:
- Yes.
- Use a dropdown to choose between types.
- Which data types (initial patch):
- Float: uniform in range
- Vector: uniform in range
- Integer: uniform in range
- Boolean: probability 0-1
- Node name:
- “Random” is too generic.
- “Random Value” is ok, even though “Value” used to refer to only floats in the past.
- “Number” wouldn’t fit as well for vectors and other data types
- Seed(s):
- Two seeds are necessary when one wants the to use two nodes in the same context, since otherwise the seed must be offset.
- In the future there can be a generic-type multi-input socket for a dynamic number of seeds.
- For now we can simply add “Seed 1” and “Seed 2” inputs.
- After the meeting we decided to use “ID” and “Seed” instead (see T91373).
- For a stable inputs one has to plug in the “Stable ID” output from the Distribute node.
- That should be more intuitive now that that output has a better name.
- Don’t change seeds when the node is copied (as was tried in D10142.
- Could be added later on as a feature of the copy operator if necessary.
- Implicit index input:
- “Seed 1” has an implicit Index field input.
- Distribution modes (should be added in separate patches afterwards):
- vector: In sphere, on sphere, direction + spread angle
- float/vector/int: Gaussian, midpoint
- Deprecate Random Float node.
- Multiple types in the same node:
- Distribution node names:
- Scatter vs. Distribute:
- Distribute sounds slightly better
- Distribute has clearer implications for the poisson disk mode
- Scatter sounds like there would be fewer points.
- Surface vs. Faces:
- One of these is necessary to distinguish is from other types of distribution like distributing in a volume.
- Faces is more correct, since it only operates on meshes.
- Faces is shorter.
- There may be other surface types in the future that the node does not work with.
- Making the node specific to faces allows us to output things like polygon index, barycentric coordinates, … in the future.
- Points vs. no Points:
- Without “Points” it is not clear enough what the node is doing.
- Verb first:
- Puts the action first, which is the most important part of the name.
- Part of the UI human interface guidelines.
- This rule can be applied most consistently.
- Leads to natural sounding node names.
- Downside is that it makes names longer.
- → Distribute Points on Faces
- → Distribute Points in Volume (for the future when that is added)
- Scatter vs. Distribute:
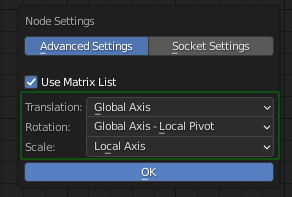
- Transform Instances:
- Seems to be better to have separate nodes for Translate, Rotate and Scale.
- Otherwise there are many different modes for choosing pivots and orientations for the different operations.
- Example from the Offset Matrix node in Animation Nodes, where all is done in one node:
- Translate Position:
- Could be a useful utility node next to the Set Position node.
- Instead of updating the position, the input would just be added to the existing position.
- However, it is better have an “Offset” boolean input in the Set Position node.
- Revisit Join/Switch node redesigns from monday:
- Can we keep them as they are given the workarounds we discussed? At least for now.
- A stretch, but maybe the order for the attribute inputs can be inferred?
- Not blocking for bcon2, maybe not even for 3.0, depending on how much users request the functionality.
- When to use instances in nodes and when to realize them? (T91672):
- Nodes could work on instances transparently, but then we don’t really have an improvement from the situation in 2.93 where it was confusing and arbitrary when they were used or realized.
- The “Realize Instances” node can be used to change the behavior of the following nodes to work on the whole geometry.
- However, that presents a performance problem, since the following nodes can sometimes work on all instances transparently as an optimization.
- So the realize instances node will functionally realize instances, but internally it can just tag the geometry so it can act as realized geometry.
- Many nodes should warn when there is a combination of instances and real geometry, because the output might feel arbitrary if they only affect the real geometry otherwise. They should even output an empty geometry.
- The “Set Handle Type” node is an example of this.
- Conversion nodes like curve to mesh and distribute points node should also have a warning, and we’ll need to remove the “read-only instances” optimization and optimize realize instances code instead.
-
Separate components node
- This has to be deprecated so a new version can output instances.
- That shouldn’t be an option, since that’s what the realize instances node is for.
-
D11522: Geometry Nodes: String to Curve
- Final new feature before Bcon2-- discuss/sign off before committing
- Implicit Instance Index in the Instance on Points node?
- Implicit index input is fine-- it makes the node more friendly and gives more useful behavior by default, and is still intuitive.
- Use modulo on the index.
- Show warning when
Pick Instanceis on and there is realized geometry inInstance.
- Node menu cleanup.
-
D12574: Geometry Nodes: Separate + Delete Geometry for fields
- Eventually the separate geometry node could have an index input and output a list of instances
- The nodes also work on instances, even though a selection field input could only depend on position and index for now.